Wikipedia contains a wealth of valuable information spanning all topics imaginable. Much of this info is tucked away in tables, infoboxes, and other structured data on pages. As developers and data enthusiasts, having access to this data can enable all sorts of useful applications.
That's where web scraping comes into play. Web scraping refers to the technique of programmatically extracting data from websites using tools that parse and select information out of HTML. In this post, we'll walk through a hands-on example of scraping Wikipedia to pull together a dataset of US presidents.
This is the table we are talking about
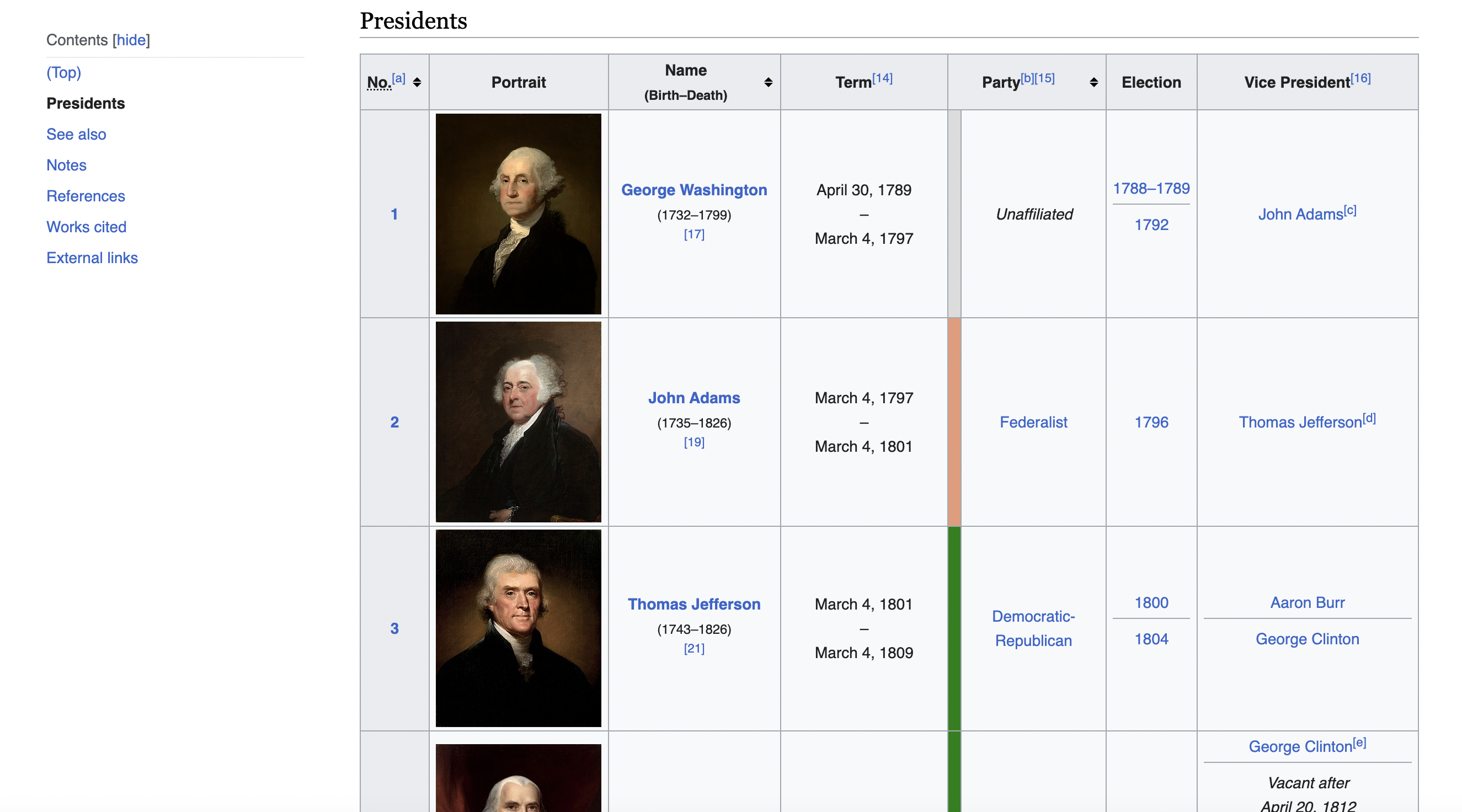
Setting the Stage with Jsoup
For this tutorial we'll use Jsoup, a Java library designed for working with real-world HTML and scraping data out of it.
First we'll define some imports to pull in the Jsoup functionality:
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
Jsoup contains tools for fetching web pages, traversing/selecting DOM elements, and extracting text or other data.
Making the Initial Request
Let's define the URL of the Wikipedia page we want to scrape:
val url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>"
This page contains a large structured table with data on each American president.
To fetch the contents of that page, we use the
val response = Jsoup.connect(url).get()
One thing I always recommend is setting a user agent header. This mimics a real web browser so the server knows the request didn't come from an unknown bot:
val headers = mapOf("User-Agent" to "Mozilla/5.0 ...")
Jsoup.connect(url).headers(headers).get()
Checking for Success
We can then check the status code of the response to confirm it succeeded:
if (response.statusCode() == 200) {
// scraping logic here
} else {
println("Failed, status code: ${response.statusCode()}")
}
Server responses are full of helpful metadata. Get familiar with status codes to better handle errors.
Parsing the Page with Jsoup
Now that we have the raw HTML, we need to parse it into a structured Document object that we can query:
val soup: Document = response
This Document represents the entire parsed page, modeled after the DOM tree structure.
Selecting Elements
Inspecting the page
When we inspect the page we can see that the table has a class called wikitable and sortable
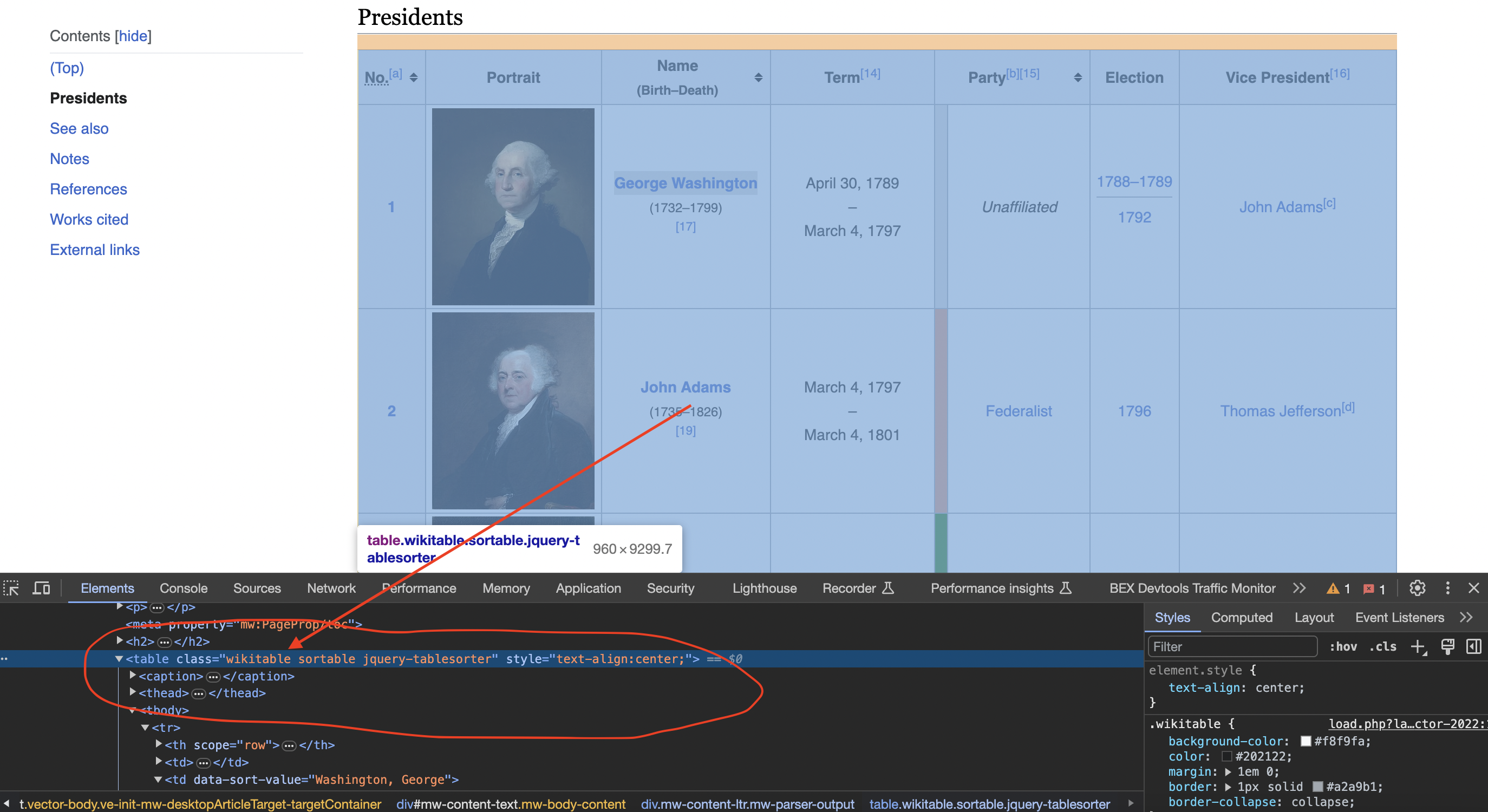
We can use CSS-style selectors to locate specific elements in that document:
val table: Element? = soup.select("table.wikitable.sortable").first()
This selects the first table element with the classes
Jsoup selectors are very powerful - read more about selector syntax.
Extracting the Data
Finally, we can iterate through the rows and cells of this table to extract our president data:
table?.select("tr")?.drop(1)?.forEach { row ->
val columns = row.select("td, th")
val row_data = columns.map { col ->
col.text()
}
println(row_data) // prints array of cell data
}
And there you have it - we now have the structured data scraped from Wikipedia! Jsoup handles all the heavy lifting.
Potential Challenges
There are always practical challenges with real-world scraping:
The example here sidesteps some of those issues, but they come up frequently. We have a whole separate guide on handling those scrapers dilemmas.
Now that you have the foundations, you can scrape most semi-structured data off sites like Wikipedia. Always be responsible by adding throttling, caching, and obeying robots.txt.
Check out the full code for this Wikipedia scraper below. Hopefully this gives you a template to start extracting your own datasets!
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
fun main() {
// Define the URL of the Wikipedia page
val url = "https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States"
// Define a user-agent header to simulate a browser request
val headers = mapOf("User-Agent" to "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36")
// Send an HTTP GET request to the URL with the headers
val response = Jsoup.connect(url).headers(headers).get()
// Check if the request was successful (status code 200)
if (response.statusCode() == 200) {
// Parse the HTML content of the page using Jsoup
val soup: Document = response
// Find the table with the specified class name
val table: Element? = soup.select("table.wikitable.sortable").first()
// Initialize empty lists to store the table data
val data: MutableList<List<String>> = mutableListOf()
// Iterate through the rows of the table
table?.select("tr")?.drop(1)?.forEach { row ->
val columns = row.select("td, th")
// Extract data from each column and append it to the data list
val row_data = columns.map { col -> col.text() }
data.add(row_data)
}
// Print the scraped data for all presidents
for (president_data in data) {
println("President Data:")
println("Number: ${president_data[0]}")
println("Name: ${president_data[2]}")
println("Term: ${president_data[3]}")
println("Party: ${president_data[5]}")
println("Election: ${president_data[6]}")
println("Vice President: ${president_data[7]}")
println()
}
} else {
println("Failed to retrieve the web page. Status code: ${response.statusCode()}")
}
}In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.