In this beginner-friendly guide, we will understand how to scrape Reddit posts using a simple Java program. We'll go through the code step-by-step, explaining how it works with detailed comments and examples.
here is the page we are talking about

Introduction
Web scraping refers to automatically collecting information from websites. Here, we will scrape post data from Reddit by:
- Sending a request to the Reddit URL
- Downloading the HTML content of the page
- Parsing the HTML to extract post information we want
This process allows us to get structured data from websites to power applications, analysis, research and more.
Scraping activities can sometimes violate terms of service. Be sure to review and strictly follow all applicable laws, terms and policies related to scraping.
Now, let's jump into the code!
Imports
We import several Java packages that provide useful functionality:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
Key highlights:
We'll see how these are used throughout the program.
Main Method
The
public static void main(String[] args) {
// Code goes here
}
All scraping logic will be enclosed within this method.
Define Target URL
We'll scrape posts from Reddit's front page:
String redditUrl = "<https://www.reddit.com>";
This hardcoded URL is our target. We could also take it as input.
Set User-Agent Header
Websites identify clients via the User-Agent header. We'll mimic a Chrome browser:
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
This helps avoid bot detection mechanisms sites may employ.
Send GET Request
We use the Jsoup library to send a HTTP GET request:
Document doc = Jsoup.connect(redditUrl)
.userAgent(userAgent)
.get();
The
The return
Check for Success
We validate the status by checking if the document is not
if (doc != null) {
// Success!
} else {
// Request failed
}
Save HTML Content
Let's save the downloaded HTML to a file:
String htmlContent = doc.html();
String filename = "reddit_page.html";
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filename))) {
writer.write(htmlContent);
System.out.println("Saved to " + filename);
} catch (IOException e) {
System.err.println("Failed to save: " + e);
}
We get the HTML using
Parse HTML
So far we have only downloaded the Reddit front page HTML. To extract actual post data, we need to parse the HTML content:
Document page = Jsoup.parse(htmlContent);
This creates a parsable
Extract Post Blocks
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
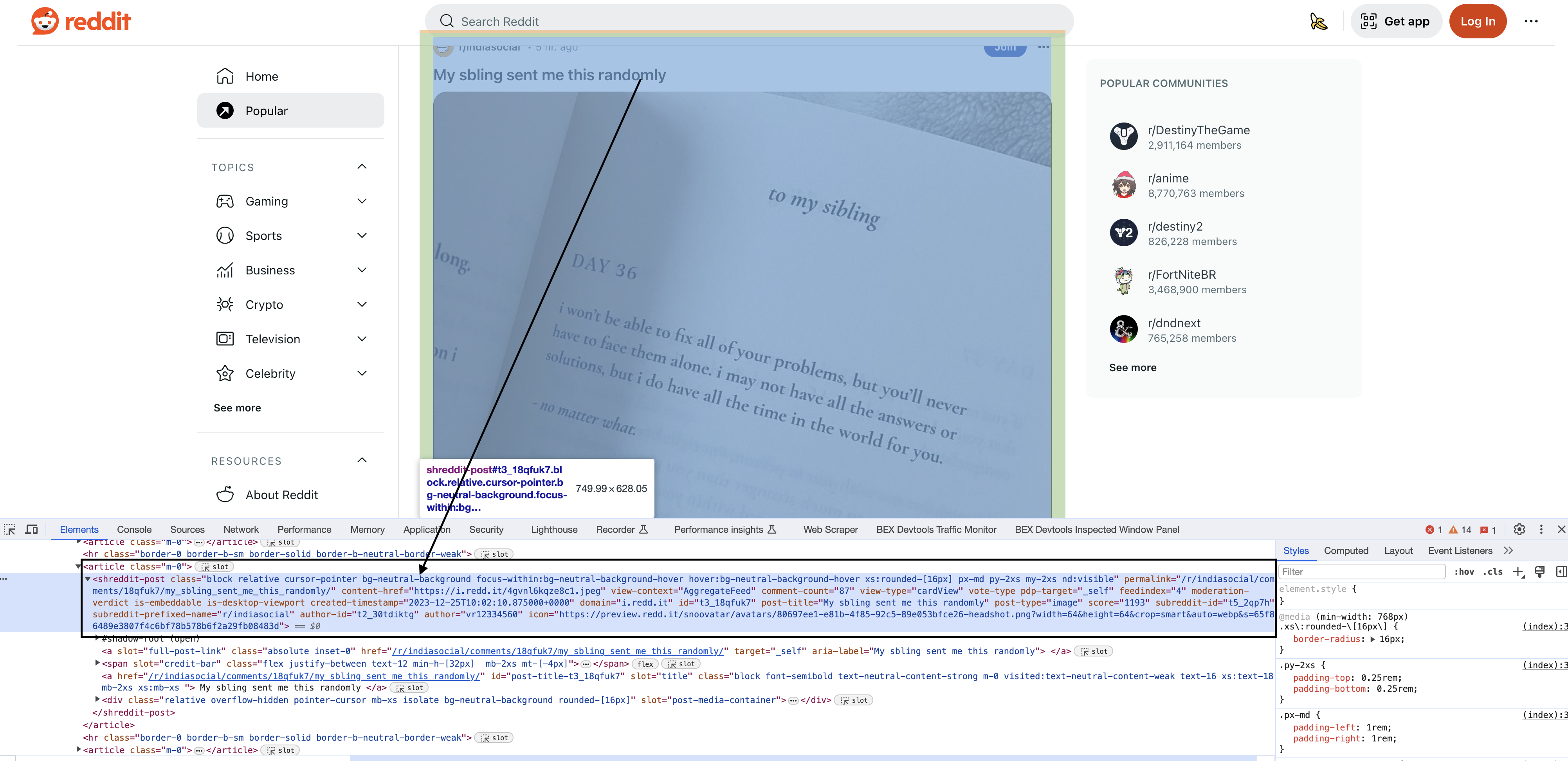
Each post on Reddit is contained in an HTML
Elements blocks = page.select("shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible");
Let's break this complex selector down:
This selector specifically identifies Reddit post blocks, saving them in an
Selectors are very powerful but do take practice to master. We'll explore more examples ahead.
Iterate Post Blocks
We can now loop through the selected post blocks:
for (Element block : blocks) {
// Extract data from each block
}
Extract Post Data
Inside the loop, we use attributes and selectors to extract specific post data we want from each block:
String permalink = block.attr("permalink");
String contentHref = block.attr("content-href");
String commentCount = block.attr("comment-count");
String postTitle = block.selectFirst("div[slot=title]").text().trim();
String author = block.attr("author");
String score = block.attr("score");
Let's understand how we get each field:
Permalink
The
block.attr("permalink")
We simply extract this attribute value.
Content URL
Similar to permalink, the content URL is also stored as a block attribute:
block.attr("content-href")
Comment Count
Comment count for the post is again extracted from an attribute:
block.attr("comment-count")
And so on for the other fields like author and score.
Post Title
Title requires an additional selector within the block:
block.selectFirst("div[slot=title]")
We then extract
Selectors give us incredible flexibility to pinpoint specific data from HTML.
Print Extracted Data
We can now print the extracted post data:
// Print the extracted information for each block
System.out.println("Permalink: " + permalink);
System.out.println("Content Href: " + contentHref);
System.out.println("Comment Count: " + commentCount);
System.out.println("Post Title: " + postTitle);
System.out.println("Author: " + author);
System.out.println("Score: " + score);
System.out.println();
This outputs data from each post.
Full Code
For reference, here is the complete code we just walked through:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class RedditScraper {
public static void main(String[] args) {
// Define the Reddit URL you want to download
String redditUrl = "https://www.reddit.com";
// Define a User-Agent header
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36";
// Send a GET request to the URL with the User-Agent header
try {
Document doc = Jsoup.connect(redditUrl)
.userAgent(userAgent)
.get();
// Check if the request was successful (status code 200)
if (doc != null) {
// Get the HTML content of the page
String htmlContent = doc.html();
// Specify the filename to save the HTML content
String filename = "reddit_page.html";
// Save the HTML content to a file
try (BufferedWriter writer = new BufferedWriter(new FileWriter(filename))) {
writer.write(htmlContent);
System.out.println("Reddit page saved to " + filename);
} catch (IOException e) {
System.err.println("Failed to save Reddit page: " + e.getMessage());
}
// Parse the entire HTML content
Document page = Jsoup.parse(htmlContent);
// Find all blocks with the specified tag and class
Elements blocks = page.select("shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible");
// Iterate through the blocks and extract information from each one
for (Element block : blocks) {
String permalink = block.attr("permalink");
String contentHref = block.attr("content-href");
String commentCount = block.attr("comment-count");
String postTitle = block.selectFirst("div[slot=title]").text().trim();
String author = block.attr("author");
String score = block.attr("score");
// Print the extracted information for each block
System.out.println("Permalink: " + permalink);
System.out.println("Content Href: " + contentHref);
System.out.println("Comment Count: " + commentCount);
System.out.println("Post Title: " + postTitle);
System.out.println("Author: " + author);
System.out.println("Score: " + score);
System.out.println();
}
} else {
System.err.println("Failed to download Reddit page");
}
} catch (IOException e) {
System.err.println("Failed to make a GET request: " + e.getMessage());
}
}
}
We were able to build a complete Reddit scraper in Java extracting post titles, URLs, authors and more!
Selectors are extremely powerful for targeting elements on web pages. With some practice, you'll be scraping all sorts of data.