Wikipedia contains a vast trove of structured data on topics ranging from history and science to pop culture and current affairs. Web scraping allows you to automatically extract this data for analysis or usage in other applications.
In this post, we will walk through a program that scrapes Wikipedia to extract details on all US presidents using popular open-source libraries - cURL for sending HTTP requests and Gumbo for parsing the returned HTML content.
The Game Plan
Before diving into the code, let's understand at a high-level what our scraper will do:
- Send a HTTP GET request to the Wikipedia page https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States using cURL
- Handle the HTML content returned by Wikipedia using a callback function
- Parse the HTML with Gumbo to locate the right data table using its "wikitable sortable" CSS class
- Iterate through the rows and cells in this table to build a nested vector with president details
- Print out fields like name, term, party and vice president for each president entry
Okay, now that we know the big picture, let's walk through the code snippet section-by-section. Don't worry if something doesn't make sense the first time. We will cover all key concepts in detail along the way.
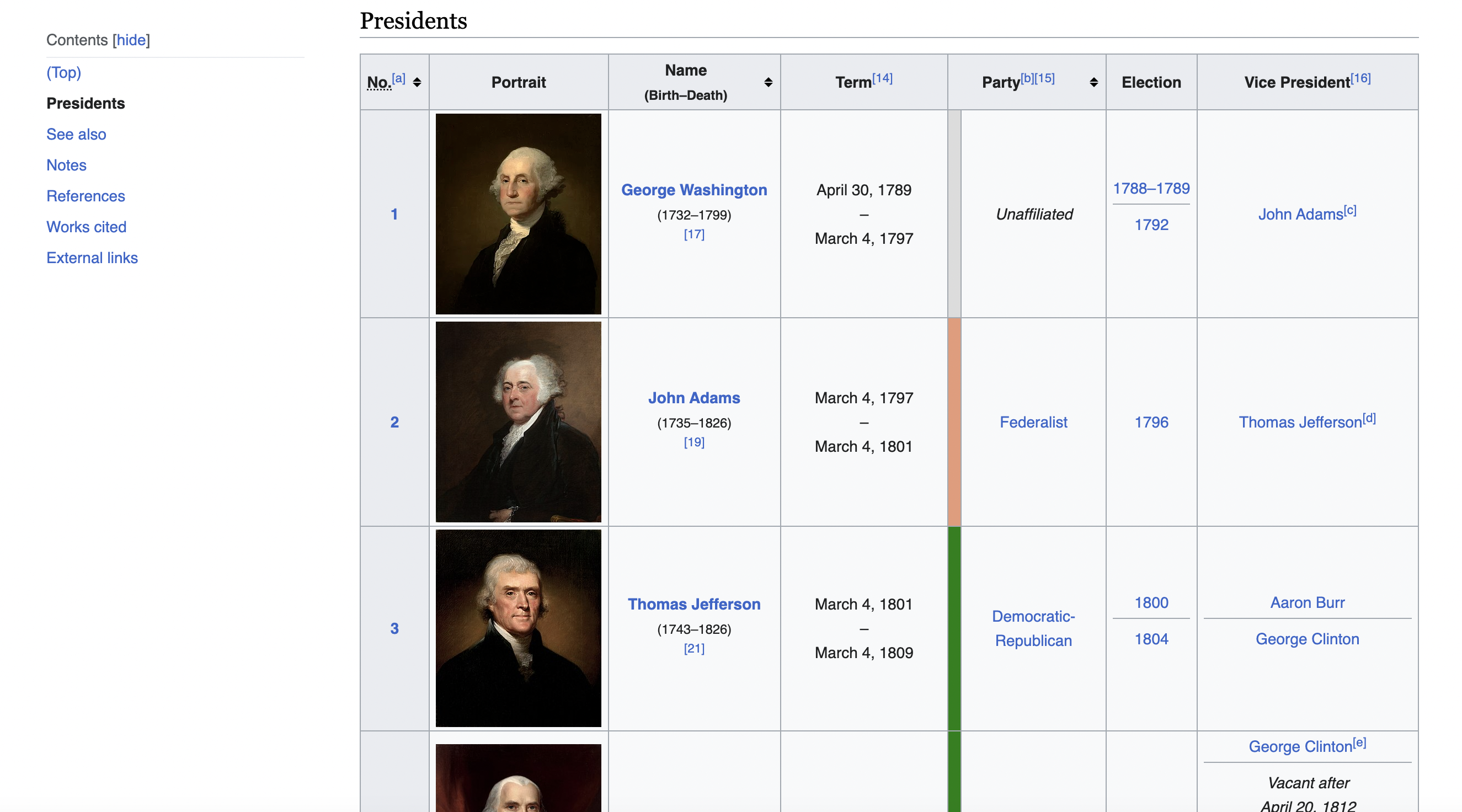
This is the table we are talking about
Include Necessary Libraries
We include the required C++ headers and libraries at the top of the program:
#include <iostream>
#include <string>
#include <vector>
#include <curl/curl.h>
#include <gumbo.h>
These include IO streams, string handling, dynamic arrays, cURL for network requests and Gumbo for HTML parsing.
We also define the URL to scrape and helper methods used later on:
const std::string url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>";
Initialize cURL Session
We begin by initializing a cURL session which will allow sending requests to URLs:
// Initialize cURL
CURL* curl = curl_easy_init();
This creates a curl CURL* handle that holds all the settings and state data for a cURL session. We can now configure options on this handle before making requests.
Set User Agent Header
Sites like Wikipedia may block suspicious requests lacking browser User Agent strings to prevent abuse. So we need to spoof a valid desktop browser header:
// Define a user-agent header
struct curl_slist* headers = nullptr;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
This masquerades our requests as coming from a Windows PC running Chrome browser. curl_slist_append() builds string list containing custom headers.
Configure Request URL
With the headers set, we specify the Wikipedia URL to send the GET request to:
// Set the URL to fetch
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
The url.c_str() part passes in a C-style string from our std::string variable containing the president list URL.
Define Write Callback
To collect the data returned by Wikipedia, we supply a callback function that accumulates response content as it arrives from cURL:
// Response data
std::string response_data;
// Set the write callback function to handle the response
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
// Callback writes data to this string
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
size_t WriteCallback(void *contents, size_t size, size_t nmemb, std::string *output) {
// Append content to output string
size_t newLength = size * nmemb;
output->append((char*)contents, newLength);
return newLength;
}
The callback accepts chunks of data, calculates their length and appends to an accumulating output string. This string is what we will parse for president data after the full response arrives.
Send Request and Check Errors
With all options configured, we send the HTTP GET request to Wikipedia:
// Perform the request
CURLcode res = curl_easy_perform(curl);
Once done, we check for any errors and handle cases like failed requests or HTTP status codes indicating issues:
// Check for errors
if (res != CURLE_OK) {
std::cerr << "Failed to retrieve page. Error: " << res << std::endl;
return 1;
}
If everything went fine, we now have the full HTML content from Wikipedia stored in our response_data string, ready for parsing!
Parse HTML Content with Gumbo
To extract meaningful information, we first need to parse the raw HTML text and convert it into a structured format. This is done using the Gumbo HTML5 parser library.
GumboOutput* output = gumbo_parse(response_data.c_str());
This converts the HTML into a parse tree that allows easy traversal and manipulation. We can now search for elements by name, id, class etc.
Locate President Data Table
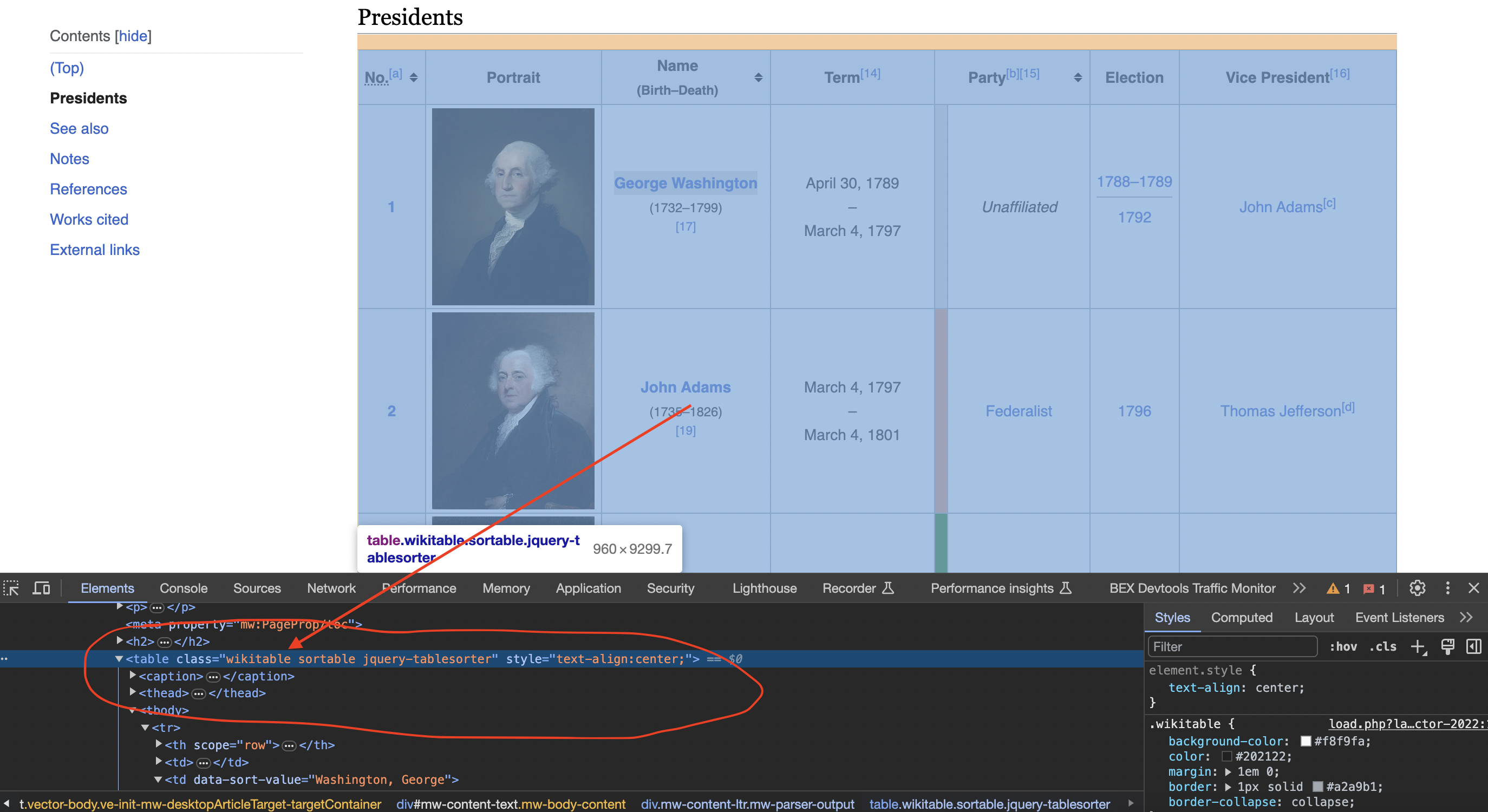
Inspecting the page
When we inspect the page we can see that the table has a class called wikitable and sortable
Our president data resides in a HTML We iterate all child elements of the root node, looking for a table with matching class name: Gumbo provides methods like gumbo_get_attribute() to easily check for attributes on the nodes during iteration. Now that we have a reference to the presidents table node, we can extract the data row-by-row: This loops over rows, gets the cell contents from each and stores in a 2D string vector that holds details for every president. Finally, we can format and print the extracted president data: And we have successfully scraped structured data from a Wikipedia page! The complete code discussed in this article: Let's summarize the key things we learned about scraping Wikipedia: The same principles can be applied to build scrapers for any other Wikipedia list pages like countries, movies etc. Some things to watch out for with web scraping: In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser! If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail. Overcoming IP Blocks Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works. Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. We have a running offer of 1000 API calls completely free. Register and get your free API Key here.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with some styling classes applied:
<table class="wikitable sortable jquery-tablesorter">
GumboNode* table = nullptr;
for (size_t i = 0; i < output->root->v.element.children.length; ++i) {
GumboNode* child = static_cast<GumboNode*>(output->root->v.element.children.data[i]);
if (child->type == GUMBO_NODE_ELEMENT &&
child->v.element.tag == GUMBO_TAG_TABLE &&
gumbo_get_attribute(&child->v.element.attributes, "class") &&
response_data.find("wikitable sortable") != std::string::npos) {
table = child;
break;
}
}
Extract President Data Row-by-Row
// Row and cell data vectors
std::vector<std::vector<std::string>> data;
for (size_t i = 0; i < table->v.element.children.length; ++i) {
GumboNode* row = static_cast<GumboNode*>(table->v.element.children.data[i]);
if (row->type == GUMBO_NODE_ELEMENT && row->v.element.tag == GUMBO_TAG_TR) {
// Extract president details from cells
std::vector<std::string> row_data;
// Code to get cells and their text contents
data.push_back(row_data);
}
}
Print Scraped President Details
for (const std::vector<std::string>& president : data) {
std::cout << "Name: " << president[2] << "\\n";
std::cout << "Term: " << president[3] << "\\n";
// etc...
}
Full Code
#include <iostream>
#include <string>
#include <vector>
#include <curl/curl.h>
#include <gumbo.h>
// Define the URL of the Wikipedia page
const std::string url = "https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States";
// Callback function to handle HTTP response
size_t WriteCallback(void* contents, size_t size, size_t nmemb, std::string* output) {
size_t total_size = size * nmemb;
output->append(static_cast<char*>(contents), total_size);
return total_size;
}
int main() {
// Initialize cURL
CURL* curl = curl_easy_init();
if (curl) {
// Define a user-agent header
struct curl_slist* headers = nullptr;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
// Set the URL to fetch
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
// Response data
std::string response_data;
// Set the write callback function to handle the response
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
// Perform the HTTP request
CURLcode res = curl_easy_perform(curl);
// Check if the request was successful (status code 200)
if (res == CURLE_OK) {
// Parse the HTML content using Gumbo parser
GumboOutput* output = gumbo_parse(response_data.c_str());
if (output) {
// Find the table with the specified class name
GumboNode* table = nullptr;
for (size_t i = 0; i < output->root->v.element.children.length; ++i) {
GumboNode* child = static_cast<GumboNode*>(output->root->v.element.children.data[i]);
if (child->type == GUMBO_NODE_ELEMENT &&
child->v.element.tag == GUMBO_TAG_TABLE &&
gumbo_get_attribute(&child->v.element.attributes, "class") &&
response_data.find("wikitable sortable") != std::string::npos) {
table = child;
break;
}
}
// Initialize empty vector to store the table data
std::vector<std::vector<std::string>> data;
// Iterate through the rows of the table
for (size_t i = 0; i < table->v.element.children.length; ++i) {
GumboNode* row = static_cast<GumboNode*>(table->v.element.children.data[i]);
if (row->type == GUMBO_NODE_ELEMENT && row->v.element.tag == GUMBO_TAG_TR) {
std::vector<std::string> row_data;
for (size_t j = 0; j < row->v.element.children.length; ++j) {
GumboNode* cell = static_cast<GumboNode*>(row->v.element.children.data[j]);
if (cell->type == GUMBO_NODE_ELEMENT && (cell->v.element.tag == GUMBO_TAG_TD || cell->v.element.tag == GUMBO_TAG_TH)) {
row_data.push_back(cell->v.element.original_tag.data);
}
}
data.push_back(row_data);
}
}
// Print the scraped data for all presidents
for (const std::vector<std::string>& president_data : data) {
std::cout << "President Data:" << std::endl;
std::cout << "Number: " << president_data[0] << std::endl;
std::cout << "Name: " << president_data[2] << std::endl;
std::cout << "Term: " << president_data[3] << std::endl;
std::cout << "Party: " << president_data[5] << std::endl;
std::cout << "Election: " << president_data[6] << std::endl;
std::cout << "Vice President: " << president_data[7] << std::endl;
std::cout << std::endl;
}
// Clean up Gumbo parser output
gumbo_destroy_output(&kGumboDefaultOptions, output);
} else {
std::cerr << "Failed to parse HTML." << std::endl;
}
} else {
std::cerr << "Failed to retrieve the web page. CURL code: " << res << std::endl;
}
// Clean up cURL
curl_easy_cleanup(curl);
curl_slist_free_all(headers);
} else {
std::cerr << "Failed to initialize cURL." << std::endl;
}
return 0;
}Wrapping Up
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!