Wikipedia contains a wealth of tabular data on almost any topic imaginable. In this article, we'll go step-by-step through an example of scraping structured data from a Wikipedia table using Elixir.
The goals are:
- Learn the basic workflow for scraping data off the web
- Become familiar with common Elixir libraries for web scraping like HTTPoison and Floki
- Write a script to extract all data from a Wikipedia table into a reusable format
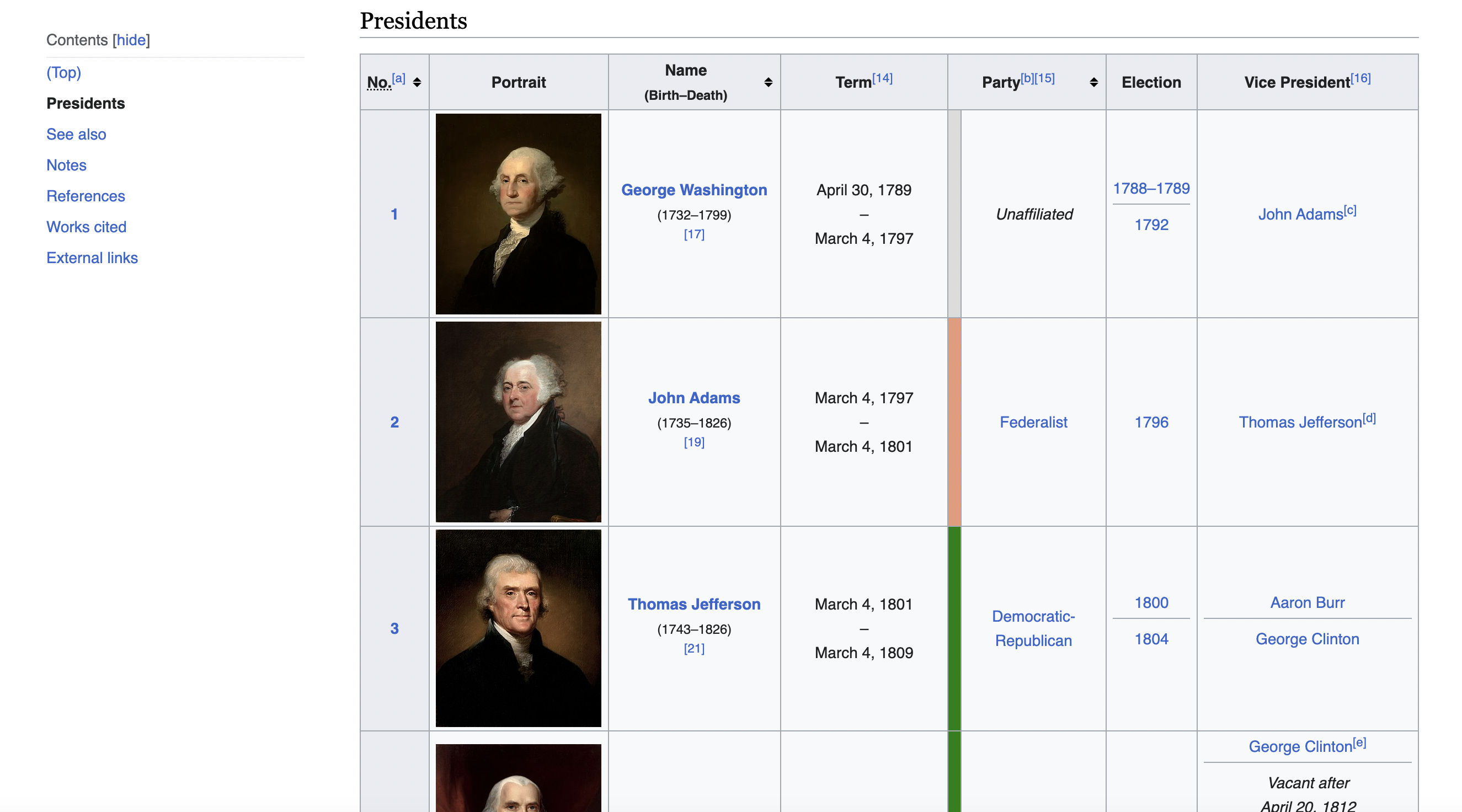
We'll focus specifically on scraping the List of presidents of the United States to pull data on every U.S. president.
This is the table we are talking about
Introduction to Web Scraping
The internet is filled with useful data, but that data isn't always in a format that's easy for a computer to process. Web scraping refers to the practice of programmatically extracting data from websites and transforming it into a structured format like CSV or JSON.
Scraping follows four main steps, which we will walk through:
- Send an HTTP request to download a web page
- Parse the HTML content to extract useful data
- Transform the extracted data into a structured format
- Output or store the final dataset
That's web scraping in a nutshell! It allows us to pull data off websites even when they don't have an official API for programmatic access. Next we'll look at how to implement a scraper in Elixir.
Setting Up an Elixir Web Scraper
We'll need two libraries to scrape the web:
Let's add them to our project by running:
mix deps.get
With the libraries installed, here is the basic scaffold of our scraper:
url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>"
{:ok, response} = HTTPoison.get(url)
html = response.body
doc = Floki.parse_document(html)
# Find and extract data...
# Output data...
We use HTTPoison to GET the Wikipedia page content, then Floki parses the HTML into a queryable document. Next we'll dig into each step more closely.
Downloading the Wikipedia Page
The first step is sending a GET request to download the web page content:
url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>"
headers = [
{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}
]
{:ok, response} = HTTPoison.get(url, headers)
Here are a some things happening:
We set a User-Agent because some sites block default Elixir user agents. Mimicking a real browser helps avoid blocks.
Parsing the Page with Floki
Next we'll parse the HTML content into a queryable document using Floki:
html = response.body
doc = Floki.parse_document(html)
This parses the HTML response body and lets us find elements using CSS selectors, just like jQuery!
Extracting Row Data
With the page loaded into a Floki document, we can query elements and extract data.
Inspecting the page
When we inspect the page we can see that the table has a class called wikitable and sortable
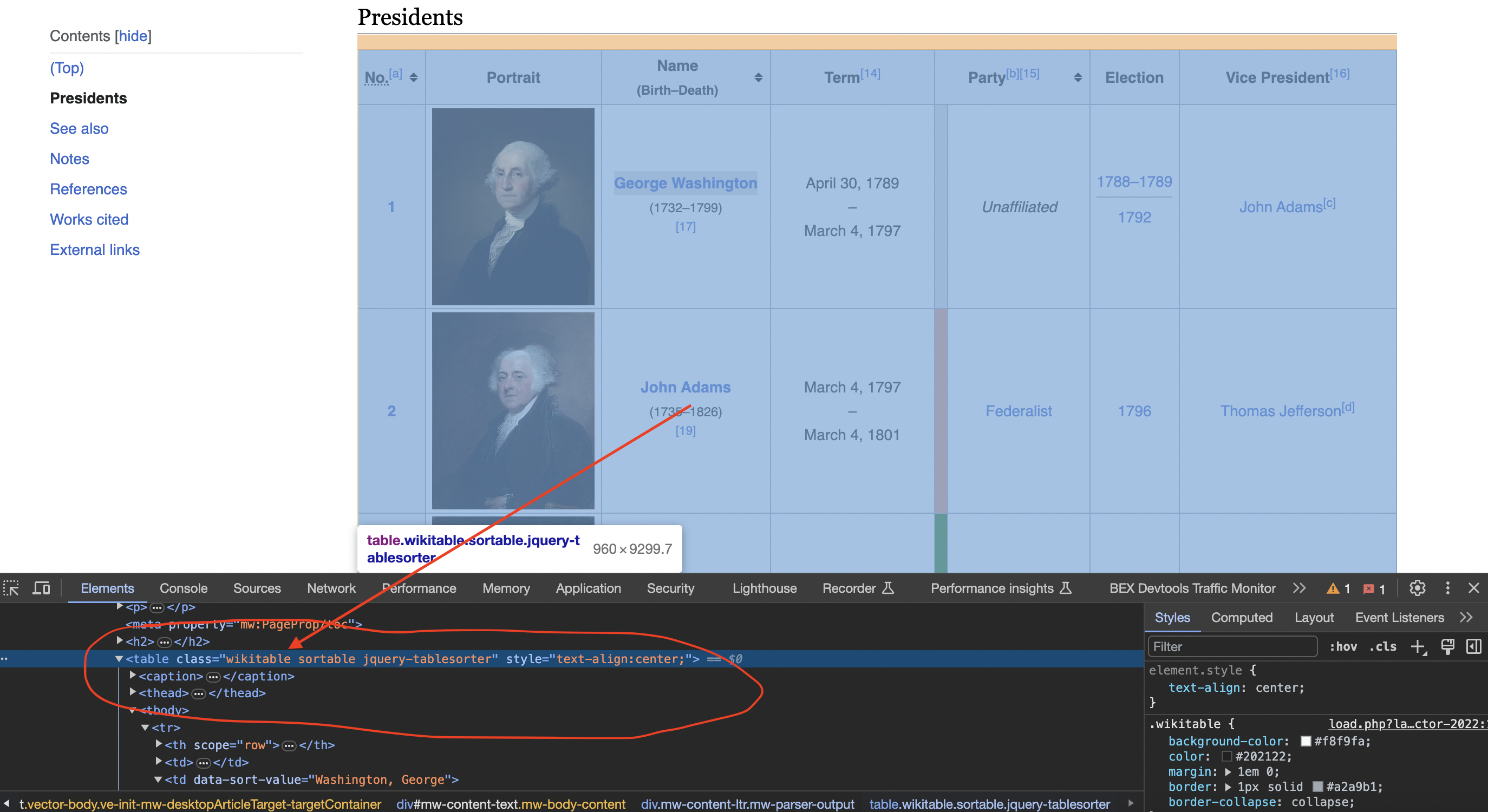
First we'll locate the presidents table:
table = Floki.find(doc, "table.wikitable.sortable")
We looked at the page source to find this specific table selector.
Next we loop through the rows, extracting the data from each:
rows = Floki.find(table, "tr")
Enum.each(rows, fn row ->
columns = Floki.find(row, ["td", "th"])
data = Enum.map(columns, fn col ->
Floki.text(col)
end)
IO.inspect(data)
end)
This prints out a list of strings for each table cell in every row!
Transforming the Data
Now we have messy strings for each cell value. To clean this up:
- Skip the header row
- Store each row into a map with keys
# Drop header
rows = Enum.drop(rows, 1)
Enum.each(rows, fn row ->
[number, _, name, term, _, party, election, vp] =
Enum.map(Floki.find(row, ["td", "th"]), &Floki.text/1)
data = %{
number: number,
name: name,
term: term,
party: party,
election: election,
vice_president: vp
}
IO.inspect(data)
end)
Much better! We now have nicely structured president data.
We could write this structured data to a file, insert into a database, or process further.
Full Script
Here is the complete Elixir web scraper put together:
url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>"
headers = [{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"}]
{:ok, response} = HTTPoison.get(url, headers)
if response.status_code == 200 do
html = response.body
doc = Floki.parse_document(html)
table = Floki.find(doc, "table.wikitable.sortable")
data = []
rows = Floki.find(table, "tr")
rows = Enum.drop(rows, 1)
Enum.each(rows, fn row ->
[number, _, name, term, _, party, election, vp] =
Enum.map(Floki.find(row, ["td", "th"]), &Floki.text/1)
row_data = %{
number: number,
name: name,
term: term,
party: party,
election: election,
vice_president: vp
}
data = [data | [row_data]]
end)
Enum.each(data, fn president ->
IO.inspect(president)
end)
else
IO.puts("Failed to retrieve page")
end
This full example puts together all the pieces:
The same principles can be applied to build scrapers for almost any site. With a little bit of tuning, you'll be able to extract and wrangle all sorts of useful data from across the web.
Some things to explore next:
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.