Let's go through a step-by-step tutorial for extracting data from eBay listings using Go. I'll explain each part of the code in detail.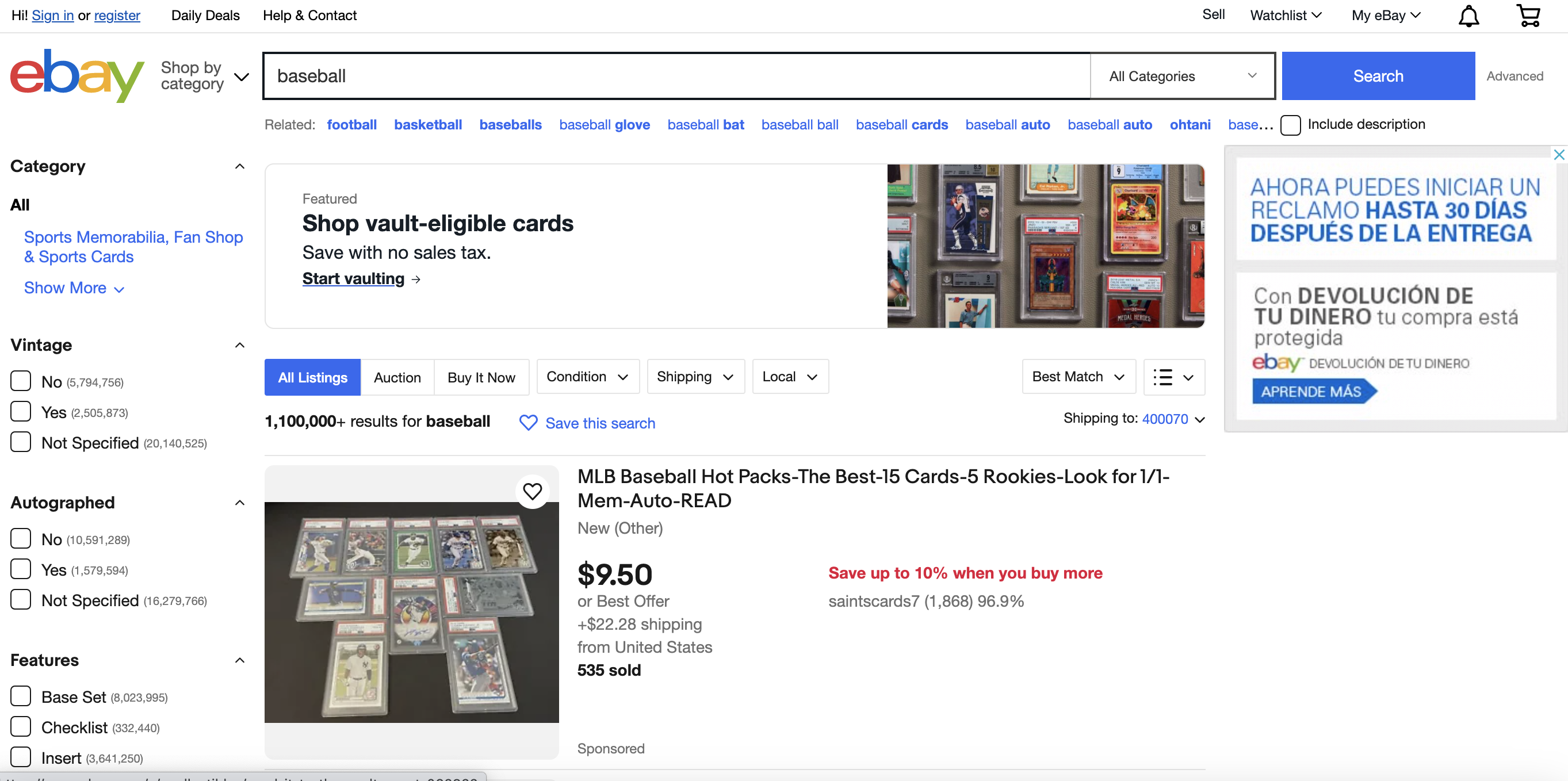
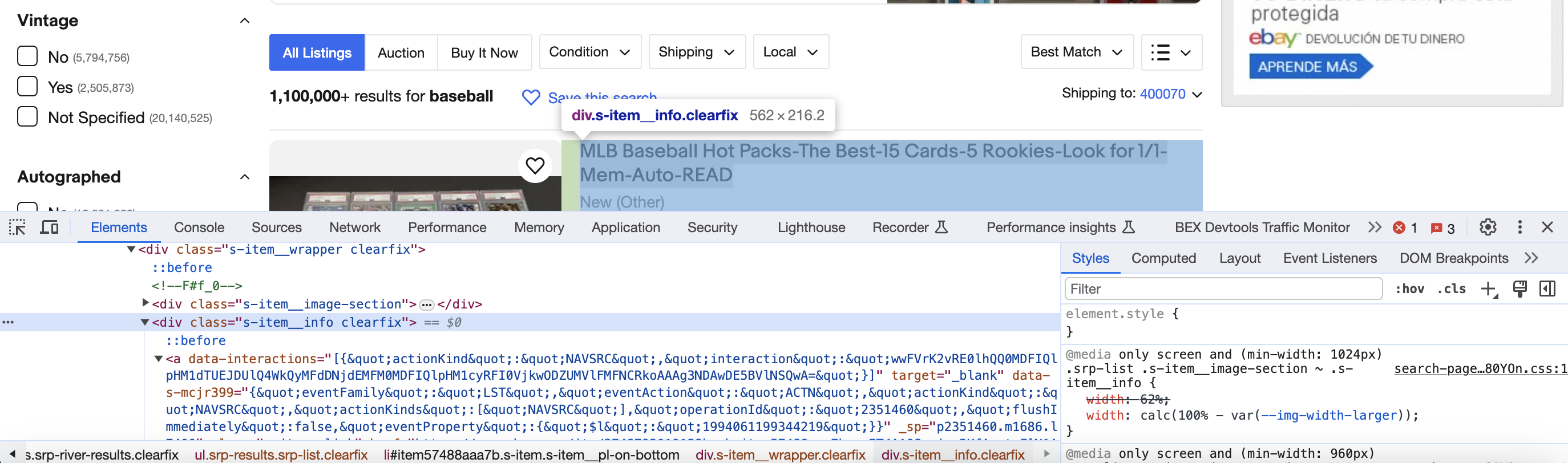
Setup
We'll use the
Install them:
go get github.com/PuerkitoBio/goquery
And import:
import (
"net/http"
"github.com/PuerkitoBio/goquery"
)
Define the eBay URL and a user-agent:
url := "<https://www.ebay.com/sch/i.html?_nkw=baseball>"
userAgent := "Mozilla/5.0 ..." // Use your browser's UA string
Fetch the Page
Make a GET request to fetch the HTML:
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", userAgent)
resp, _ := client.Do(req)
defer resp.Body.Close()
We create a
Parse the HTML
Load the HTML into goquery to parse it:
doc, _ := goquery.NewDocumentFromReader(resp.Body)
Extract Listing Data
Find all listings with a CSS selector:
doc.Find(".s-item__info").Each(func(i int, s *goquery.Selection) {
title := s.Find(".s-item__title").Text()
url, _ := s.Find(".s-item__link").Attr("href")
price := s.Find(".s-item__price").Text()
// Extract other fields like details, seller, etc
})
Loop through them, and use
Print Results
fmt.Println("Title:", title)
fmt.Println("URL:", url)
fmt.Println("Price:", price)
fmt.Println(strings.Repeat("=", 50)) // Separator
Full Code
package main
import (
"net/http"
"github.com/PuerkitoBio/goquery"
"fmt"
"strings"
)
func main() {
url := "https://www.ebay.com/sch/i.html?_nkw=baseball"
userAgent := "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
client := &http.Client{}
req, _ := http.NewRequest("GET", url, nil)
req.Header.Set("User-Agent", userAgent)
resp, _ := client.Do(req)
defer resp.Body.Close()
doc, _ := goquery.NewDocumentFromReader(resp.Body)
doc.Find(".s-item__info").Each(func(i int, s *goquery.Selection) {
title := s.Find(".s-item__title").Text()
url, _ := s.Find(".s-item__link").Attr("href")
price := s.Find(".s-item__price").Text()
details := s.Find(".s-item__subtitle").Text()
seller := s.Find(".s-item__seller-info-text").Text()
shipping := s.Find(".s-item__shipping").Text()
location := s.Find(".s-item__location").Text()
sold := s.Find(".s-item__quantity-sold").Text()
fmt.Println("Title:", title)
fmt.Println("URL:", url)
fmt.Println("Price:", price)
fmt.Println("Details:", details)
fmt.Println("Seller:", seller)
fmt.Println("Shipping:", shipping)
fmt.Println("Location:", location)
fmt.Println("Sold:", sold)
fmt.Println(strings.Repeat("=", 50))
})
}