Hacker News is a popular social news website focused on computer science and entrepreneurship topics. It features user-submitted links and discussions, akin to a programming-focused reddit. In this beginner's guide, we will walk through Python code to scrape articles from the Hacker News homepage using web scraping.
This is the page we are talking about…
Prerequisites
To follow along, you'll need:
Install libcurl and Gumbo with apt:
apt install libcurl4-openssl-dev libgumbo-dev
And include the necessary headers in your Python code:
import curl
import gumbo
Overview
The goal of our script is to scrape information from the articles shown on the Hacker News homepage, including:
To achieve this, we will:
- Send a GET request to retrieve the page HTML
- Parse the HTML content using Gumbo
- Extract information by selecting elements
- Print out the scraped data
Let's take a look section-by-section!
Initialize libcurl
We start by initializing libcurl which we'll use to send the HTTP requests:
curl = curl_easy_init()
if (!curl) {
// Error handling
}
Define URL and Send Request
Next we set the URL to scrape - the Hacker News homepage:
url = "<https://news.ycombinator.com/>"
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
We also attach callbacks to accumulate the response and write it to a string variable that will hold the page HTML:
std::string response_data;
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
Finally, we kick off the request and handle any errors:
CURLcode res = curl_easy_perform(curl);
if (res != CURLE_OK) {
// Error handling
}
Now
Parse HTML with Gumbo
The next step is to parse the HTML content using Gumbo, an HTML5 parsing library.
We initialize Gumbo, passing in the page HTML, which gives us a parsed DOM tree to query:
GumboOutput* output = gumbo_parse(response_data.c_str());
GumboNode* root = output->root;
Find Rows and Iterate Over Articles
Inspecting the page
You can notice that the items are housed inside a So articles are arranged in table rows. We use a selector to find all rows, storing them in a convenient vector structure: We can now iterate over the rows, identifying article rows using another selector - the This allows us to process each article's data. With an article row selected, we can now extract information from the page elements. This is where most beginners struggle, so we'll go through each field one-by-one: Title We get the title with this selector - it looks for the element with Within that, we find the anchor tag which holds the text: And finally, we access the title text: URL The article URL is stored in an anchor attribute: Points The points element has class Author The author element has class Timestamp The timestamp is stored in a title attribute: Comments For comments, we find the element with text And extract the text: The key things to understand are: With data extracted, we can now print it out! The last step is to print the scraped content: And with that, we have successfully scraped the articles from Hacker News! We finish by freeing the Gumbo parsed output and cleaning up libcurl: In this guide we: Web scraping takes practice, but by breaking it down step-by-step hopefully this tutorial provided a solid foundation! Here is the full code: This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with the class athing 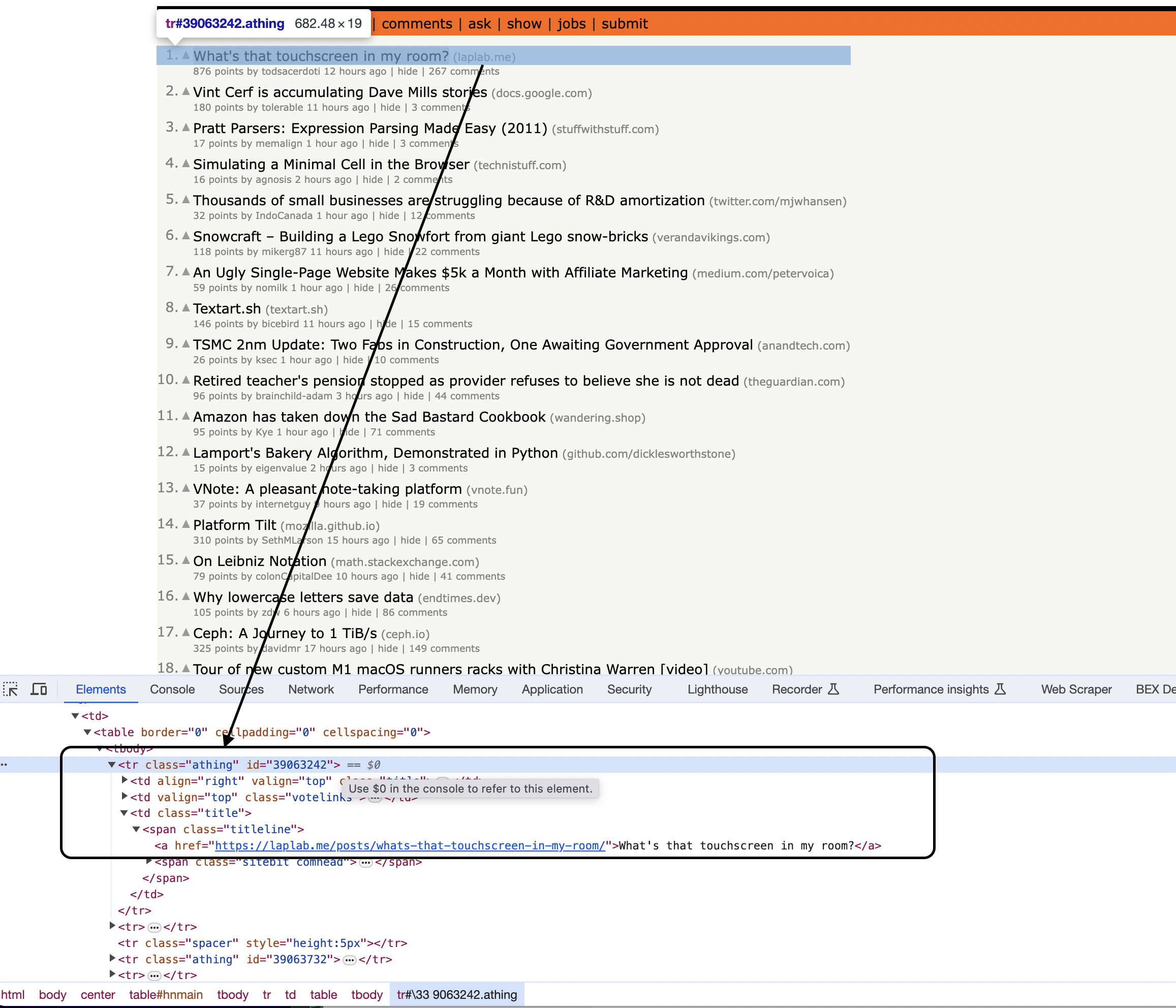
GumboVector* rows = &root->v.element.children;
for (unsigned int i = 0; i < rows->length; ++i) {
GumboNode* row = (GumboNode*)rows->data[i];
if (row->v.element.tag == GUMBO_TAG_TR) {
GumboAttribute* class_attr = gumbo_get_attribute(&row->v.element.attributes, "class");
if (class_attr && strcmp(class_attr->value, "athing") == 0) {
// This is an article row
current_article = row;
current_row_type = "article";
}
}
}
Extracting Article Data
GumboNode* title_elem = gumbo_get_element_by_class(current_article, "title");
GumboNode* anchor_elem = gumbo_get_element_by_tag(title_elem, GUMBO_TAG_A);
const char* article_title = anchor_elem->v.element.v.text.start;
const char* article_url = gumbo_get_attribute(&anchor_elem->v.element.attributes, "href")->value;
GumboNode* subtext = gumbo_get_element_by_class(row, "subtext");
const char* points = gumbo_get_text(subtext->v.element.children.data[0]);
const char* author = gumbo_get_text(gumbo_get_element_by_class(subtext, "hnuser"));
const char* timestamp = gumbo_get_attribute(&subtext->v.element.children.data[2]->v.element.attributes, "title")->value;
GumboNode* comments_elem = gumbo_get_element_by_text(subtext, "comments");
const char* comments = comments_elem ? gumbo_get_text(comments_elem) : "0";
Print Extracted Data
std::cout << "Title: " << article_title << std::endl;
std::cout << "URL: " << article_url << std::endl;
// etc
Cleanup and Conclusion
gumbo_destroy_output(&kGumboDefaultOptions, output);
curl_easy_cleanup(curl);
#include <iostream>
#include <string>
#include <curl/curl.h>
#include <gumbo.h>
// Callback function for libcurl to write HTTP response to a string
size_t WriteCallback(void* contents, size_t size, size_t nmemb, std::string* output) {
size_t total_size = size * nmemb;
output->append((char*)contents, total_size);
return total_size;
}
int main() {
// Initialize libcurl
CURL* curl = curl_easy_init();
if (!curl) {
std::cerr << "Failed to initialize libcurl" << std::endl;
return 1;
}
// Define the URL of the Hacker News homepage
std::string url = "https://news.ycombinator.com/";
// Send a GET request to the URL
std::string response_data;
curl_easy_setopt(curl, CURLOPT_URL, url.c_str());
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, WriteCallback);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &response_data);
CURLcode res = curl_easy_perform(curl);
if (res != CURLE_OK) {
std::cerr << "Failed to retrieve the page. Error: " << curl_easy_strerror(res) << std::endl;
curl_easy_cleanup(curl);
return 1;
}
// Initialize Gumbo parser
GumboOutput* output = gumbo_parse(response_data.c_str());
GumboNode* root = output->root;
// Find all rows in the table
GumboVector* rows = &root->v.element.children;
// Iterate through the rows to scrape articles
GumboNode* current_article = NULL;
const char* current_row_type = NULL;
for (unsigned int i = 0; i < rows->length; ++i) {
GumboNode* row = (GumboNode*)rows->data[i];
if (row->v.element.tag == GUMBO_TAG_TR) {
GumboAttribute* class_attr = gumbo_get_attribute(&row->v.element.attributes, "class");
if (class_attr && strcmp(class_attr->value, "athing") == 0) {
// This is an article row
current_article = row;
current_row_type = "article";
} else if (current_row_type && strcmp(current_row_type, "article") == 0) {
// This is the details row
if (current_article) {
// Extract information from the current article and details row
GumboNode* title_elem = gumbo_get_element_by_class(current_article, "title");
if (title_elem) {
GumboNode* anchor_elem = gumbo_get_element_by_tag(title_elem, GUMBO_TAG_A);
if (anchor_elem) {
const char* article_title = anchor_elem->v.element.v.text.start;
const char* article_url = gumbo_get_attribute(&anchor_elem->v.element.attributes, "href")->value;
GumboNode* subtext = gumbo_get_element_by_class(row, "subtext");
const char* points = gumbo_get_text(subtext->v.element.children.data[0]);
const char* author = gumbo_get_text(gumbo_get_element_by_class(subtext, "hnuser"));
const char* timestamp = gumbo_get_attribute(&subtext->v.element.children.data[2]->v.element.attributes, "title")->value;
GumboNode* comments_elem = gumbo_get_element_by_text(subtext, "comments");
const char* comments = comments_elem ? gumbo_get_text(comments_elem) : "0";
// Print the extracted information
std::cout << "Title: " << article_title << std::endl;
std::cout << "URL: " << article_url << std::endl;
std::cout << "Points: " << points << std::endl;
std::cout << "Author: " << author << std::endl;
std::cout << "Timestamp: " << timestamp << std::endl;
std::cout << "Comments: " << comments << std::endl;
std::cout << "--------------------------------------------------" << std::endl;
}
}
}
// Reset the current article and row type
current_article = NULL;
current_row_type = NULL;
}
}
}
// Clean up libcurl and Gumbo
gumbo_destroy_output(&kGumboDefaultOptions, output);
curl_easy_cleanup(curl);
return 0;
}curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!