In this article, we will be walking through Go code that scrapes articles from the Hacker News homepage and extracts key data points about each article. The goals are to:
- Explain how the code works from start to finish, focusing on areas that beginners typically find confusing
- Describe in detail how each data field is extracted from the HTML using Go's goquery library
- Provide the full code at the end as a runnable reference
This will teach you core concepts around web scraping with Go that you can apply to build scrapers for other sites.
This is the page we are talking about…
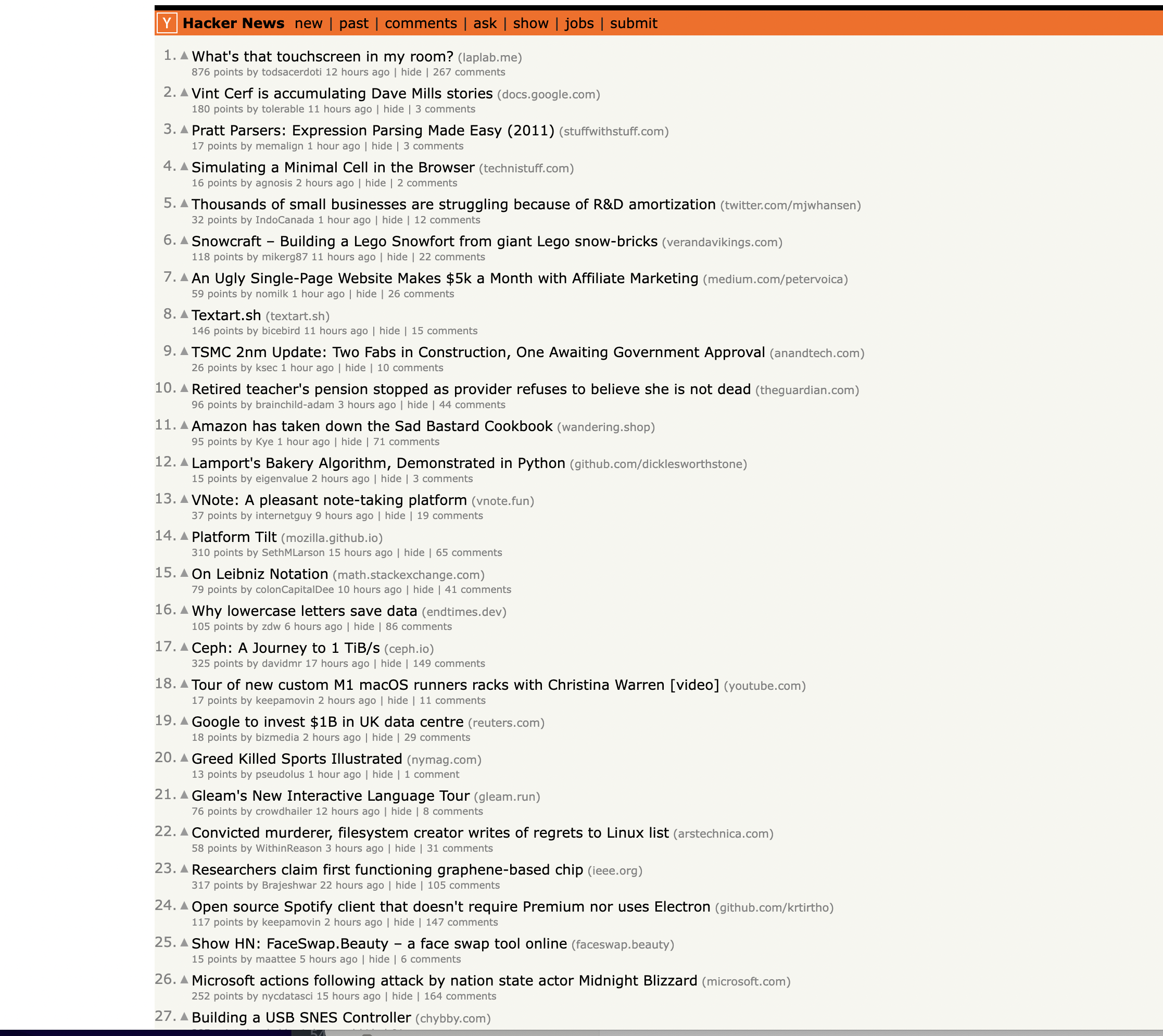
Prerequisites
To run this code, you just need:
With those in place, you can jump right into the explanations and example code below.
Step-by-Step Walkthrough
Below I will walk through exactly what this code does, section by section. The focus is on specifics around interacting with HTML and extracting data, since that tends to trip up Go beginners.
Imports
We start by importing the necessary packages:
import (
"fmt"
"net/http"
"github.com/PuerkitoBio/goquery"
"strings"
)
Making the HTTP Request
Next we define the URL we want to scrape and make the HTTP GET request:
// Define the URL
url := "<https://news.ycombinator.com/>"
// Send HTTP GET request
res, err := http.Get(url)
// Handle errors
if err != nil {
fmt.Println("Failed to retrieve page:", err)
return
}
defer res.Body.Close()
We use Go's built-in
We also make sure to
Parsing the HTML with goquery
Once we have the page content, we can parse it using goquery - Go's version of jQuery specifically for parsing HTML:
if res.StatusCode == 200 {
// Parse HTML using goquery
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
fmt.Println("Failed to parse HTML:", err)
return
}
// Find all rows
rows := doc.Find("tr")
// ...rest of scraping logic
}
Assuming a 200 OK status code, we load the HTML into a goquery Document. This allows us to treat the HTML as jQuery/CSS selectors that we can query elements against.
Inspecting the page
You can notice that the items are housed inside a For example, Now this is where beginners tend to get lost - how to actually extract each data field from the HTML using goquery. I will walk through this section slowly, explaining how every piece of data is selected: Let's break this down field-by-field: Article titles are inside We use The title text itself links to the article. So we find the Points are inside a The author anchor has a class Interesting selector here! We look for any anchor The timestamp is stored in a title attribute rather than text. We use And that covers all the data extraction logic! The key ideas are: With these building blocks, you can query elements in powerful ways. For reference, here is the complete code: This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with the class athing 
elements from the page. Extracting Article Data
// Initialize variables
var currentArticle *goquery.Selection
var currentRowType string
// Iterate through rows
rows.Each(func(i int, row *goquery.Selection) {
// Get class and style attributes for identifying row types
class, _ := row.Attr("class")
style, _ := row.Attr("style")
// Logic for identifying article vs detail rows
if class == "athing" {
currentArticle = row
currentRowType = "article"
} else if currentRowType == "article" {
// This is a details row
// Extract data only if currentArticle is set
if currentArticle != nil {
// -- Article title
titleElem := currentArticle.Find("span.title")
articleTitle := titleElem.Text()
// -- Article URL
articleURL, _ := titleElem.Find("a").Attr("href")
// -- Points, author, comments
subtext := row.Find("td.subtext")
points := subtext.Find("span.score").Text()
author := subtext.Find("a.hnuser").Text()
commentsElem := subtext.Find("a:contains('comments')")
comments := strings.TrimSpace(commentsElem.Text())
// -- Timestamp
timestamp := subtext.Find("span.age").AttrOr("title", "")
// Print everything
fmt.Println("Title:", articleTitle)
fmt.Println("URL:", articleURL)
fmt.Println("Points:", points)
fmt.Println("Author:", author)
fmt.Println("Timestamp:", timestamp)
fmt.Println("Comments:", comments)
fmt.Println(strings.Repeat("-", 50))
}
}
})
Article Title
titleElem := currentArticle.Find("span.title")
articleTitle := titleElem.Text()
. Article URL
articleURL, _ := titleElem.Find("a").Attr("href")
Points
points := subtext.Find("span.score").Text()
Author
author := subtext.Find("a.hnuser").Text()
Comments
commentsElem := subtext.Find("a:contains('comments')")
comments := strings.TrimSpace(commentsElem.Text())
Timestamp
timestamp := subtext.Find("span.age").AttrOr("title", "")
Full Code
package main
import (
"fmt"
"net/http"
"github.com/PuerkitoBio/goquery"
"strings"
)
func main() {
// Define the URL of the Hacker News homepage
url := "https://news.ycombinator.com/"
// Send a GET request to the URL
res, err := http.Get(url)
if err != nil {
fmt.Println("Failed to retrieve the page:", err)
return
}
defer res.Body.Close()
// Check if the request was successful (status code 200)
if res.StatusCode == 200 {
// Parse the HTML content of the page using goquery
doc, err := goquery.NewDocumentFromReader(res.Body)
if err != nil {
fmt.Println("Failed to parse HTML:", err)
return
}
// Find all rows in the table
rows := doc.Find("tr")
// Initialize variables to keep track of the current article and row type
var currentArticle *goquery.Selection
var currentRowType string
// Iterate through the rows to scrape articles
rows.Each(func(i int, row *goquery.Selection) {
class, _ := row.Attr("class")
style, _ := row.Attr("style")
if class == "athing" {
// This is an article row
currentArticle = row
currentRowType = "article"
} else if currentRowType == "article" {
// This is the details row
if currentArticle != nil {
// Extract information from the current article and details row
titleElem := currentArticle.Find("span.title")
articleTitle := titleElem.Text()
articleURL, _ := titleElem.Find("a").Attr("href")
subtext := row.Find("td.subtext")
points := subtext.Find("span.score").Text()
author := subtext.Find("a.hnuser").Text()
timestamp := subtext.Find("span.age").AttrOr("title", "")
commentsElem := subtext.Find("a:contains('comments')")
comments := strings.TrimSpace(commentsElem.Text())
// Print the extracted information
fmt.Println("Title:", articleTitle)
fmt.Println("URL:", articleURL)
fmt.Println("Points:", points)
fmt.Println("Author:", author)
fmt.Println("Timestamp:", timestamp)
fmt.Println("Comments:", comments)
fmt.Println(strings.Repeat("-", 50)) // Separating articles
}
// Reset the current article and row type
currentArticle = nil
currentRowType = ""
} else if style == "height:5px" {
// This is the spacer row, skip it
return
}
})
} else {
fmt.Println("Failed to retrieve the page. Status code:", res.StatusCode)
}
}curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!