Web scraping can seem daunting for beginners, but it opens up a lot of possibilities to programmatically extract and store data from websites. In this article, we'll walk through a simple example of scraping article titles and links from the New York Times homepage using C#.
Setting the Stage
Let's imagine you want to keep track of the top news articles on the New York Times every day. Visiting the site and copying these manually would be tedious. Web scraping provides a programmatic way to automate this!
We'll use the .NET framework along with two handy packages - HttpClient for making requests and HTML Agility Pack for parsing and extracting HTML elements.
Creating the C# Project
First, we need a project to work in. Create a new console app in Visual Studio and install the Nuget packages:
Install-Package HtmlAgilityPack
We'll also need
Making the Initial Request
The first step is to make a request to fetch the contents of the NYT homepage. This will retrieve the raw HTML that we can then parse:
// Parameterize homepage URL
private static string url = "<https://www.nytimes.com/>";
// Create HTTP client
using (var client = new HttpClient())
{
// GET request
HttpResponseMessage response = await client.GetAsync(url);
// Check success status code
if(response.StatusCode == HttpStatusCode.OK) {
// Do something with the response
}
}
We use the
Inspecting the page
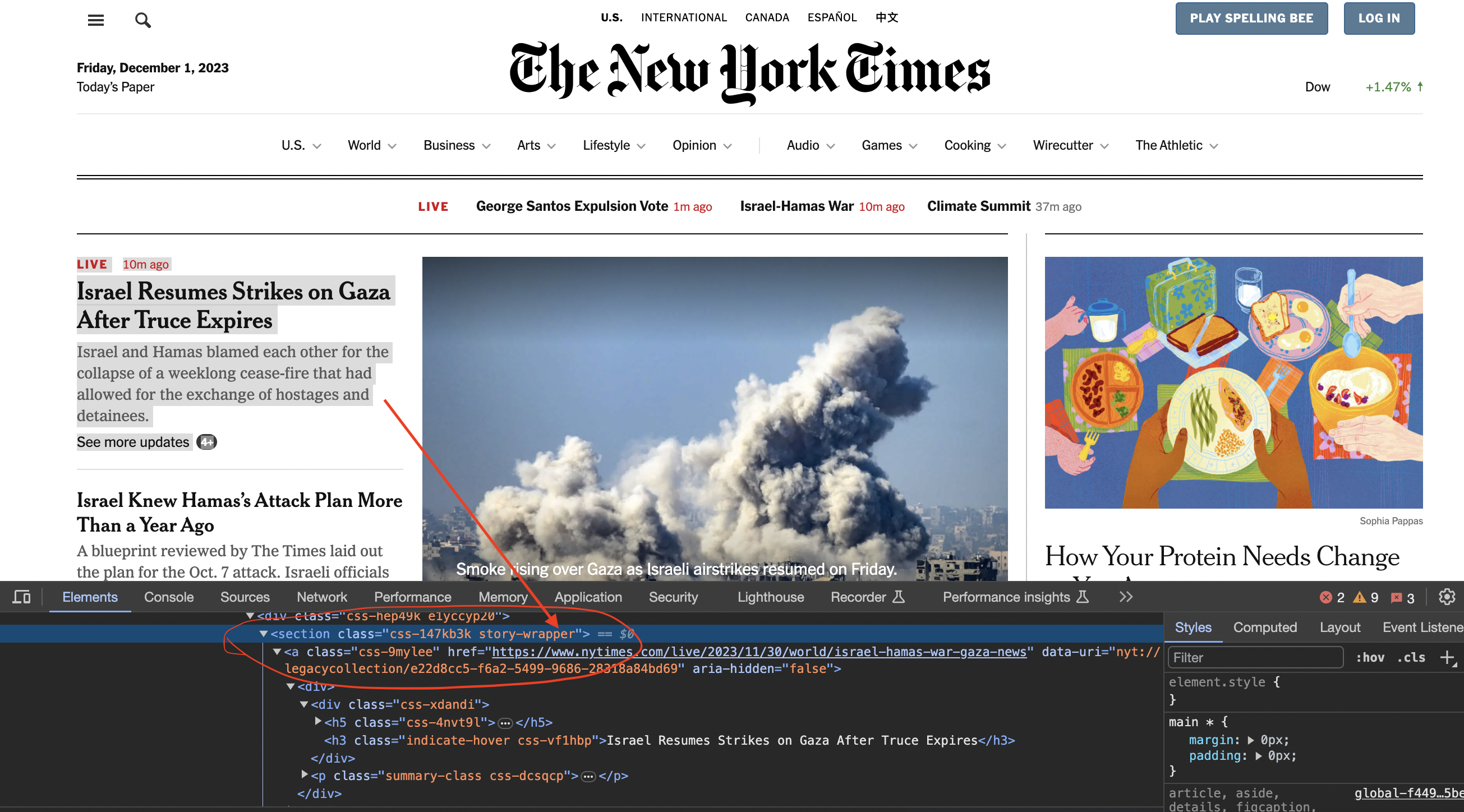
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
Parsing the HTML
Next, we want to extract the article titles and links from the response HTML using HTML Agility Pack:
// Load HTML from response
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(await response.Content.ReadAsStringAsync());
// XPath queries to extract nodes
var titles = htmlDoc.DocumentNode.SelectNodes("//h3[@class='indicate-hover']");
var links = htmlDoc.DocumentNode.SelectNodes("//a[@class='css-9mylee']");
Here we use XPath syntax to target elements with specific CSS classes —
Storing the Scraped Data
Now that we've extracted the titles and links, let's store them in generic lists:
List<string> articleTitles = new List<string>();
List<string> articleLinks = new List<string>();
foreach(var titleNode in titles) {
articleTitles.Add(titleNode.InnerText);
}
foreach(var linkNode in links) {
articleLinks.Add(linkNode.GetAttributeValue("href", ""));
}
We loop through each extracted node, get its underlying text or attribute value, and add it to the respective list.
Thread Safety and Error Handling
As one last improvement, we can use parallel threads and locks for efficiency and thread-safety:
Parallel.ForEach(titles, titleNode => {
lock(articleTitles) {
articleTitles.Add(titleNode.InnerText);
}
});
We should also wrap our HTTP call in a try-catch block to handle errors:
try {
// Make request
// Parse HTML
// Extract data
} catch (Exception ex) {
Console.WriteLine("An error occurred!");
}
And that's it! Here is the full code for reference:
using System;
using System.Net;
using System.Collections.Generic;
using System.Threading.Tasks;
using HtmlAgilityPack;
namespace NyTimesScraper
{
class Program
{
// Parameterize URL
private static string url = "https://www.nytimes.com/";
static async Task Main(string[] args)
{
// Added error handling
try
{
// Use HttpClient for better performance
using (var client = new HttpClient())
{
// Set user-agent
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
// Send GET request
HttpResponseMessage response = await client.GetAsync(url);
// Added status code check
if (response.StatusCode == HttpStatusCode.OK)
{
// Use HTML Agility Pack
var htmlDoc = new HtmlDocument();
htmlDoc.LoadHtml(await response.Content.ReadAsStringAsync());
// Use Generics instead of arrays
List<string> articleTitles = new List<string>();
List<string> articleLinks = new List<string>();
// Multi-threaded parsing
Parallel.ForEach(htmlDoc.DocumentNode.SelectNodes("//section[@class='story-wrapper']"), node =>
{
// Extract title and link
var title = node.SelectSingleNode("./h3[@class='indicate-hover']").InnerText.Trim();
var link = node.SelectSingleNode("./a[@class='css-9mylee']").GetAttributeValue("href", null);
// Add to lists (thread-safe)
lock(articleTitles) {
articleTitles.Add(title);
}
lock(articleLinks) {
articleLinks.Add(link);
}
});
// Store/display results
StoreInCsv(articleTitles, articleLinks);
}
}
}
catch (Exception ex)
{
Console.WriteLine("Error: " + ex.Message);
}
}
private static void StoreInCsv(List<string> titles, List<string> links)
{
// Code to store in CSV file
Console.WriteLine("Count: " + titles.Count);
}
}
}While basic, this walkthrough covers the key aspects of web scraping using C# and .NET. With a few tweaks, you could customize this scraper for any site or data.
Some challenges to tackle next:
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.