Have you ever wanted to systematically extract data from a website? That process is called web scraping, and it's a very useful skill for building Elixir applications. In this beginner-friendly walkthrough, we'll cover how to use Elixir libraries like HTTPoison and Floki to scrape article titles and links from the New York Times homepage.
Let's get started!
What is Web Scraping?
Web scraping refers to programmatically fetching web page content and extracting the data you need.
For example, say we want to get a list of article headlines from the New York Times to display in our Elixir app. We could manually copy and paste each headline, but that's tedious for us humans. Web scraping automates that grunt work.
The scraper will:
- Download the New York Times homepage HTML
- Parse through that HTML content
- Pick out the article titles and links
- Output those titles and links for us to display
Pretty handy! Scraping saves us humans a lot of repetitive work.
Scraping the New York Times Homepage
Let's walk through this scraper code step-by-step:
defmodule Scraper do
require HTTPoison
require Floki
First, we define a Scraper module and require the HTTPoison and Floki libraries. We'll use HTTPoison to download the web page HTML. Then Floki will help us query and traverse the HTML content to extract the data we want.
Next, we configure the
@user_agent [{"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0"}]
This helps us spoof a browser's user agent string so the New York Times server thinks we're Firefox rather than a scraper bot. Useful insider trick!
Now let's define the main fetch logic:
def fetch_articles do
case HTTPoison.get("<https://www.nytimes.com/>", @user_agent) do
{:ok, %HTTPoison.Response{status_code: 200, body: body}} ->
parse_articles(body)
{:ok, %HTTPoison.Response{status_code: status_code}} ->
IO.puts "Failed to retrieve web page, status code: #{status_code}"
{:error, %HTTPoison.Error{}} ->
IO.puts "Failed to retrieve web page"
end
end
We make an HTTP GET request to fetch https://www.nytimes.com, passing that user agent header we configured earlier.
This returns an HTTP response which we pattern match on:
You'll often see this status code matching pattern when making web requests from Elixir.
Inspecting the page
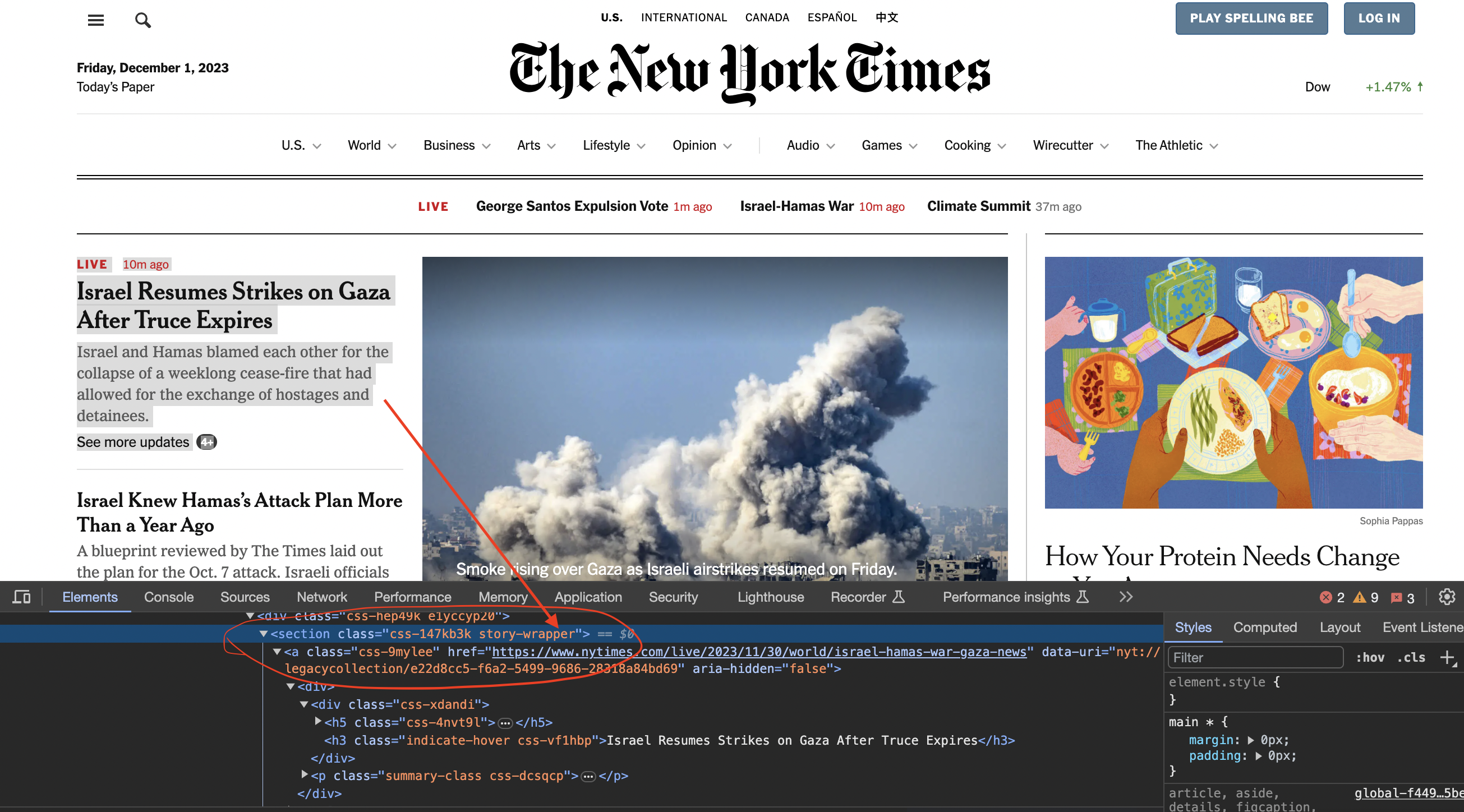
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
Next up, parsing the articles:
defp parse_articles(html) do
html
|> Floki.find("section.story-wrapper")
|> Enum.map(fn element ->
title =
element
|> Floki.find("h3.indicate-hover")
|> Floki.text()
|> String.trim()
link =
element
|> Floki.find("a.css-9mylee")
|> Floki.attribute("href")
{title, link}
end)
|> print_articles()
end
The parse_articles function receives the raw HTML of the webpage. We use Floki to find all the story elements, then extract the title and link attributes from each one. The last line passes those article data maps to print_articles/1 to output.
Finally, printing the articles:
defp print_articles(articles) do
Enum.each(articles, fn {title, link} ->
IO.puts "Title: #{title}"
IO.puts "Link: #{link}"
IO.puts ""
end)
end
This iterates through our list of article maps, printing out each title and link.
And that's it! When we call fetch_articles, this will scrape and output the latest New York Times articles.
We could extend this scraper to extract article authors, summaries, images, etc by finding additional elements with Floki. We could also persist these articles to a database to power an Elixir news app. Lots of possibilities!
Key takeways:
Give this scraper code a run yourself:
defmodule Scraper do
require HTTPoison
require Floki
@user_agent [{:"User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0"}]
def fetch_articles do
case HTTPoison.get("https://www.nytimes.com/", @user_agent) do
{:ok, %HTTPoison.Response{status_code: 200, body: body}} ->
parse_articles(body)
{:ok, %HTTPoison.Response{status_code: status_code}} ->
IO.puts "Failed to retrieve web page, status code: #{status_code}"
{:error, %HTTPoison.Error{}} ->
IO.puts "Failed to retrieve web page"
end
end
defp parse_articles(html) do
html
|> Floki.find("section.story-wrapper")
|> Enum.map(fn element ->
title =
element
|> Floki.find("h3.indicate-hover")
|> Floki.text()
|> String.trim()
link =
element
|> Floki.find("a.css-9mylee")
|> Floki.attribute("href")
{title, link}
end)
|> print_articles()
end
defp print_articles(articles) do
Enum.each(articles, fn {title, link} ->
IO.puts "Title: #{title}"
IO.puts "Link: #{link}"
IO.puts ""
end)
end
endIn more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.