Web scraping is a technique for extracting data from websites automatically. It can be useful for collecting articles, building datasets, and automating workflows. In this beginner-friendly guide, we'll walk through scraping article titles and links from The New York Times homepage using Scala and the Jsoup library.
Use Case
Why would you want to scrape The New York Times site? Here are a few examples:
While The New York Times provides API access, scraping can complement that by extracting data directly from the rendered web pages.
Setup
We'll use Jsoup, a Java library for parsing HTML. To follow along, you'll need:
Add this to your SBT build:
libraryDependencies += "org.jsoup" % "jsoup" % "1.15.3"
This scaffolds out the imports and entry point:
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
object TimesScraper {
def main(args: Array[String]): Unit = {
// Scraping logic will go here
}
}
Making a Request
To scrape a web page, we need to first download its HTML content. Jsoup provides a clean API for this by handling much of the HTTP complexity under the hood.
We'll use
val url = "<https://www.nytimes.com/>"
val doc: Document = Jsoup.connect(url).get()
The
Note: Websites often check the User-Agent header to prevent scraping. Let's spoof a real browser's user agent to avoid issues:
val userAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
val doc: Document = Jsoup
.connect(url)
.userAgent(userAgent)
.get()
We can now parse this
Parsing the Page
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
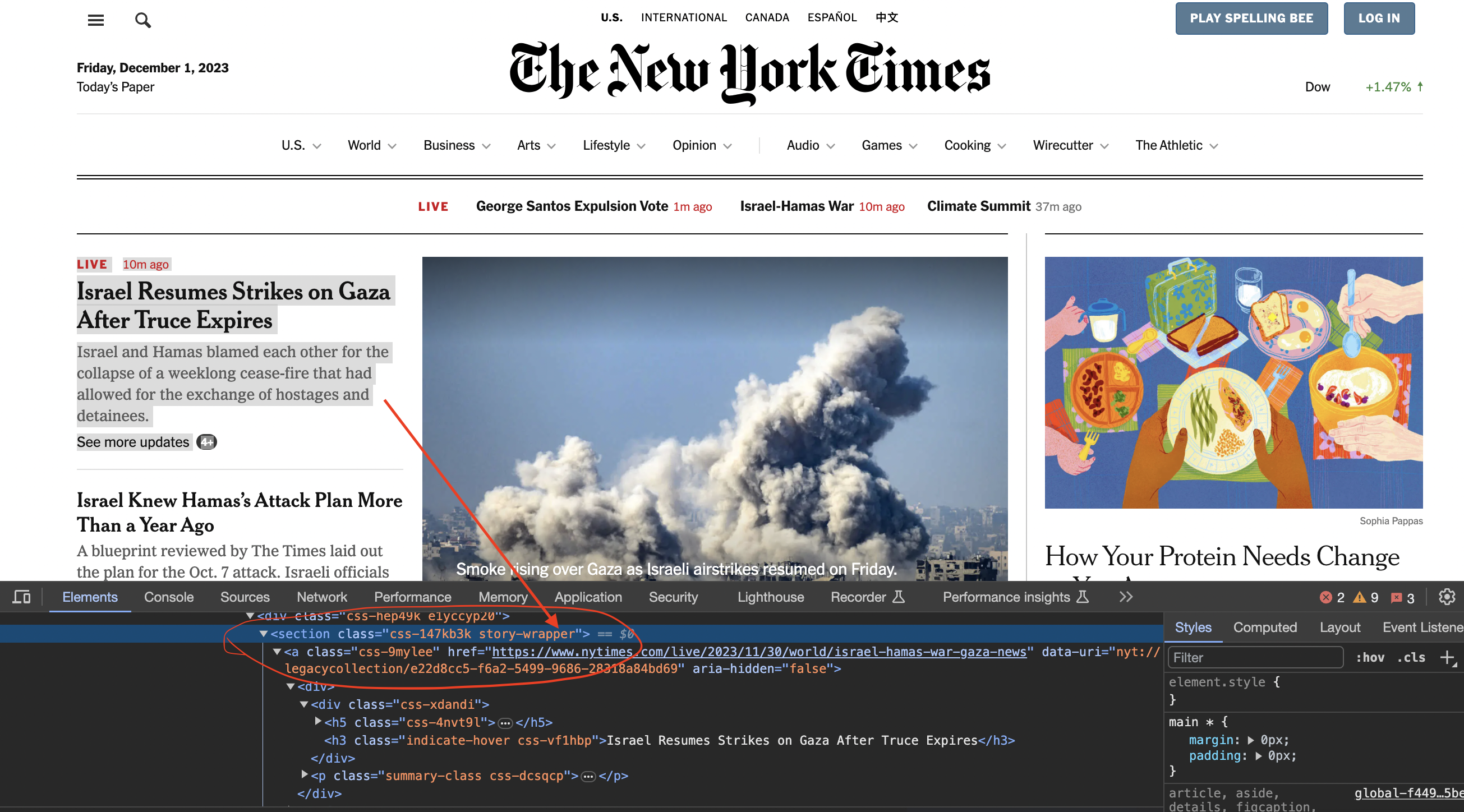
Next we'll use Jsoup's DOM traversal methods and CSS selectors to find elements.
The New York Times site has a
val articleSections = doc.select("section.story-wrapper")
We can iterate through these sections and use more specific selectors to extract the title and link from each one.
Jsoup lets you pass CSS selector strings like jQuery. Here's how to get the title and link elements:
// Get article title
val titleElement = articleSection.selectFirst("h3.indicate-hover")
// Get article link
val linkElement = articleSection.selectFirst("a.css-9mylee")
Then we can use Jsoup's DOM methods to extract the text and attributes values:
// Extract title text
val articleTitle = titleElement.text()
// Extract href value
val articleLink = linkElement.attr("href")
And voila! We now have each article title and link scraped from the homepage.
Putting It All Together
Here is the full scraper code:
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
object TimesScraper {
def main(args: Array[String]): Unit = {
val url = "<https://www.nytimes.com/>"
val userAgent = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
val doc: Document = Jsoup
.connect(url)
.userAgent(userAgent)
.get()
val articleSections = doc.select("section.story-wrapper")
var articleTitles = List[String]()
var articleLinks = List[String]()
for (articleSection <- articleSections.asScala) {
val titleElement = articleSection.selectFirst("h3.indicate-hover")
val linkElement = articleSection.selectFirst("a.css-9mylee")
if (titleElement != null && linkElement != null) {
val articleTitle = titleElement.text()
val articleLink = linkElement.attr("href")
articleTitles = articleTitle :: articleTitles
articleLinks = articleLink :: articleLinks
}
}
println(articleTitles)
println(articleLinks)
}
}
And we're done! Run the code and you'll see the latest articles printed out.
You can now store these in a database, send them to a web API, or process them further.
Next Steps
This covers the basics of using Jsoup to scrape data from an HTML page. Some ideas for next steps:
Web scraping opens up many possibilities for building cool and useful data pipelines. Hopefully this tutorial provided a solid foundation for leveraging these techniques in your projects.
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.