Web scraping is the process of extracting data from websites automatically through code. It allows you to harvest and use public data in all kinds of beneficial ways.
In this article, we'll walk through a full example of scraping article titles and links from the home page of The New York Times (NYT). Their site doesn't have an API to access this article data directly, so web scraping provides a method to get it.
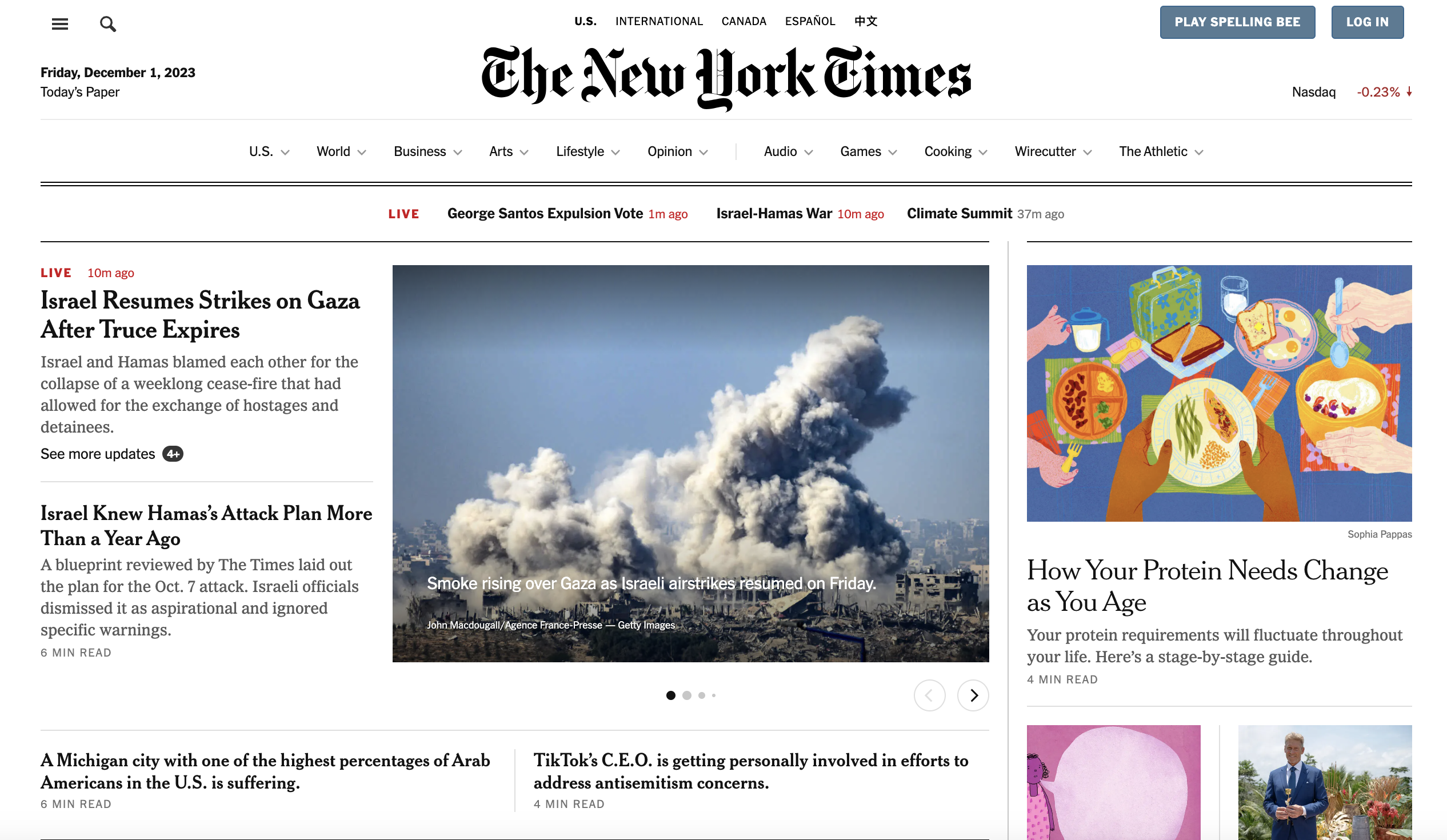
Why Scrape The New York Times?
The NYT publishes high-quality, timely articles across many topics. Scraping them allows you to tap into this great content for projects like:
Many ideas are possible once the data has been extracted!
Step 1: Set Up Imports and Modules
We first need to import the .NET namespaces and define a module for our scraper code:
Imports System.Net
Imports System.IO
Imports HtmlAgilityPack
Module Program
Wrapping our code in a module allows it to be called from other parts of the application.
Step 2: Create Request to NYT Website
To make a request to any web page, we need to specify the URL. For The New York Times home page:
Dim url As String = "<https://www.nytimes.com/>"
We also should define a user agent header that identifies our program as a browser. This gets around blocks some sites have against scraping bots:
Dim userAgent As String = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
Then we can construct an
Dim request As HttpWebRequest = DirectCast(WebRequest.Create(url), HttpWebRequest)
request.UserAgent = userAgent
This request will simulate a browser visiting the URL.
Step 3: Send Request and Get Response
To actually call the URL, we use the
Dim response As HttpWebResponse = DirectCast(request.GetResponse(), HttpWebResponse)
This will connect to the URL and return an
We should check that the request was successful by looking at the status code:
If response.StatusCode = HttpStatusCode.OK Then
' Request succeeded
End If
Status code 200 means everything went smoothly. Other codes indicate an error happened.
Step 4: Load HTML into Parser
Now that we have the raw HTML content from the page, we need to parse it to extract the articles. The Html Agility Pack (HAP) library allows easy parsing and querying of HTML in .NET.
We load the response stream into an
Dim htmlDoc As New HtmlDocument()
htmlDoc.Load(response.GetResponseStream())
This document represents a structured tree of elements that we can now explore using CSS selectors and XPath queries.
Step 5: Use XPath to Extract Articles
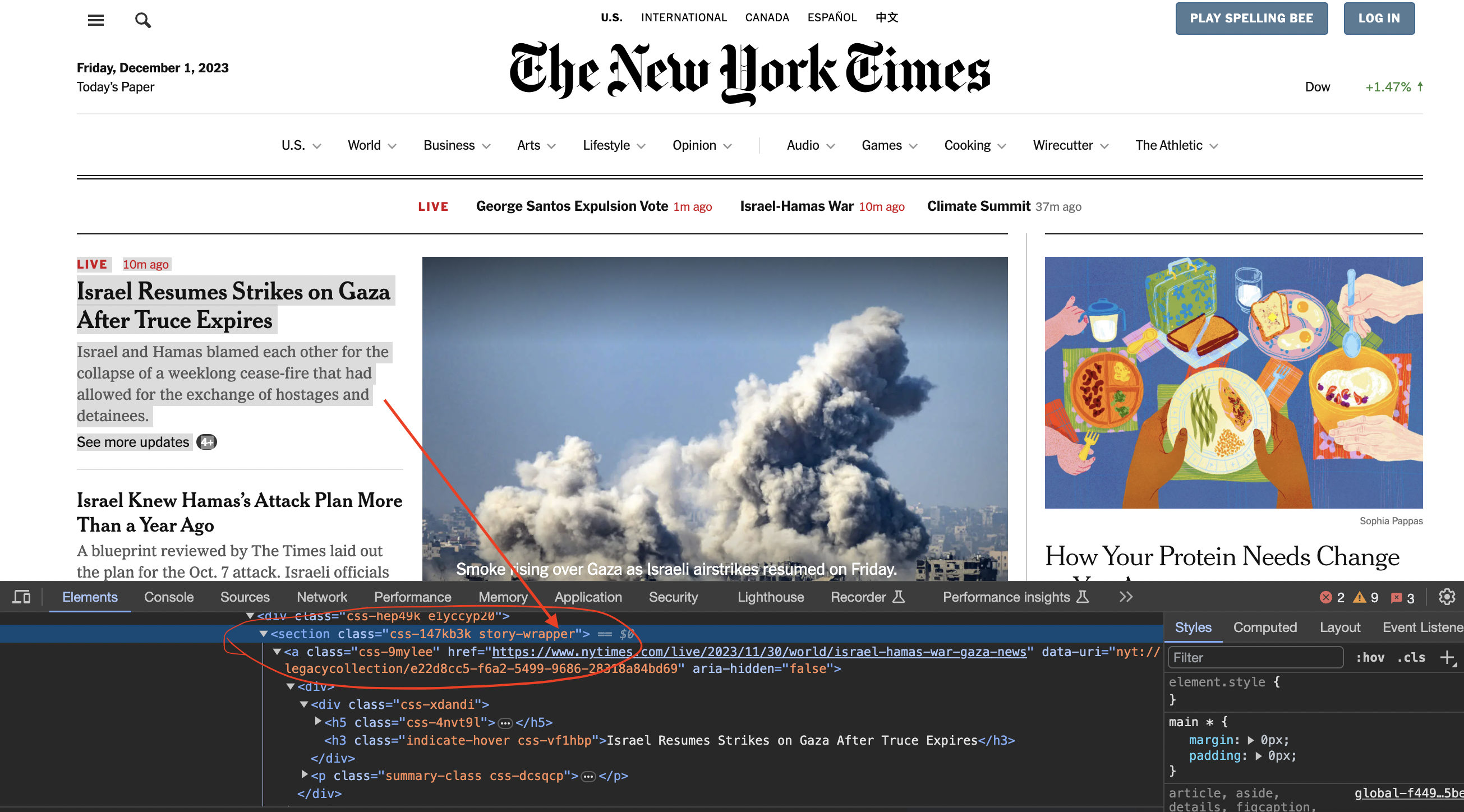
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
HAP has many options to target elements - we'll use XPath queries here since they work well for scraping structured data.
First we get all
Dim articleSections As HtmlNodeCollection = htmlDoc.DocumentNode.SelectNodes("//section\\[contains(@class, 'story-wrapper')\\]")
This finds the key sections containing articles on NYT's home page.
We iterate over these sections and use more XPath queries to extract the title and link inside each:
For Each articleSection As HtmlNode In articleSections
Dim titleElement As HtmlNode = articleSection.SelectSingleNode(".//h3\\[contains(@class, 'indicate-hover')\\]")
Dim linkElement As HtmlNode = articleSection.SelectSingleNode(".//a\\[contains(@class, 'css-9mylee')\\]")
Next
These queries target the specific elements in each section that contain the data we want.
Step 6: Store Results in Lists
As we extract each title and link, we can store them in lists:
Dim articleTitles As New List(Of String)
Dim articleLinks As New List(Of String)
'...
articleTitles.Add(titleElement.InnerText.Trim())
articleLinks.Add(linkElement.GetAttributeValue("href", ""))
These lists give us easy access to the scraped data for any processing or output we want.
Step 7: Print/Process Results
Finally, we can print the article titles and links:
For i As Integer = 0 To articleTitles.Count - 1
Console.WriteLine("Title: " & articleTitles(i))
Console.WriteLine("Link: " & articleLinks(i))
Console.WriteLine()
Next
This will output each article scraped from the homepage.
The full code can be found at the end of this article.
Key Takeaways
The key steps to scrape structured article data are:
- Identify target site and elements
- Craft web request with user agent
- Parse page HTML
- Extract data with XPath
- Store in object model
- Output/process results
From here you could expand to scrape additional fields, save to a database, or integrate with other systems. Web scraping opens up many possibilities!
Next Steps
To extend this simple scraper:
Web scraping brings the vast content of the web to your fingertips! Let us know if you have any other questions.
Full code:
Imports System.Net
Imports System.IO
Imports HtmlAgilityPack
Module Program
Sub Main()
' URL of The New York Times website
Dim url As String = "https://www.nytimes.com/"
' Define a user-agent header to simulate a browser request
Dim userAgent As String = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
' Create an HTTP request with the user-agent header
Dim request As HttpWebRequest = DirectCast(WebRequest.Create(url), HttpWebRequest)
request.UserAgent = userAgent
' Send an HTTP GET request to the URL
Dim response As HttpWebResponse = DirectCast(request.GetResponse(), HttpWebResponse)
' Check if the request was successful (status code 200)
If response.StatusCode = HttpStatusCode.OK Then
' Create an HtmlDocument to parse the HTML content
Dim htmlDoc As New HtmlDocument()
htmlDoc.Load(response.GetResponseStream())
' Find all article sections with class 'story-wrapper'
Dim articleSections As HtmlNodeCollection = htmlDoc.DocumentNode.SelectNodes("//section[contains(@class, 'story-wrapper')]")
' Initialize lists to store the article titles and links
Dim articleTitles As New List(Of String)()
Dim articleLinks As New List(Of String)()
' Iterate through the article sections
If articleSections IsNot Nothing Then
For Each articleSection As HtmlNode In articleSections
' Check if the article title element exists
Dim titleElement As HtmlNode = articleSection.SelectSingleNode(".//h3[contains(@class, 'indicate-hover')]")
' Check if the article link element exists
Dim linkElement As HtmlNode = articleSection.SelectSingleNode(".//a[contains(@class, 'css-9mylee')]")
' If both title and link are found, extract and append
If titleElement IsNot Nothing AndAlso linkElement IsNot Nothing Then
Dim articleTitle As String = titleElement.InnerText.Trim()
Dim articleLink As String = linkElement.GetAttributeValue("href", "")
articleTitles.Add(articleTitle)
articleLinks.Add(articleLink)
End If
Next
End If
' Print or process the extracted article titles and links
For i As Integer = 0 To articleTitles.Count - 1
Console.WriteLine("Title: " & articleTitles(i))
Console.WriteLine("Link: " & articleLinks(i))
Console.WriteLine()
Next
Else
Console.WriteLine("Failed to retrieve the web page. Status code: " & response.StatusCode)
End If
End Sub
End ModuleIn more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.