The New York Times publishes some of the most influential journalism in the world. As developers, we can leverage web scraping techniques to systematically extract articles from nytimes.com to power all kinds of useful applications.
Let's walk through this Java code to scrape article headlines and links from the New York Times homepage:
First we import the Jsoup Java library which does all the heavy lifting for web scraping:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
Jsoup handles connecting to web pages, parsing HTML, finding elements, extracting data - so we don't have to get bogged down in the nitty gritty web page details.
Next we set the URL we want to scrape:
String url = "<https://www.nytimes.com/>";
Now here's an insider trick when scraping - we simulate a browser's user agent string so that our Java app identifies itself properly to the web server:
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
Document document = Jsoup.connect(url).userAgent(userAgent).get();
Instead of the default Java user agent, we use a Chrome browser user agent. This prevents the New York Times server from blocking our scraper for looking suspicious.
Next we use Jsoup's powerful selector syntax to find the sections of the homepage that contain articles:
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
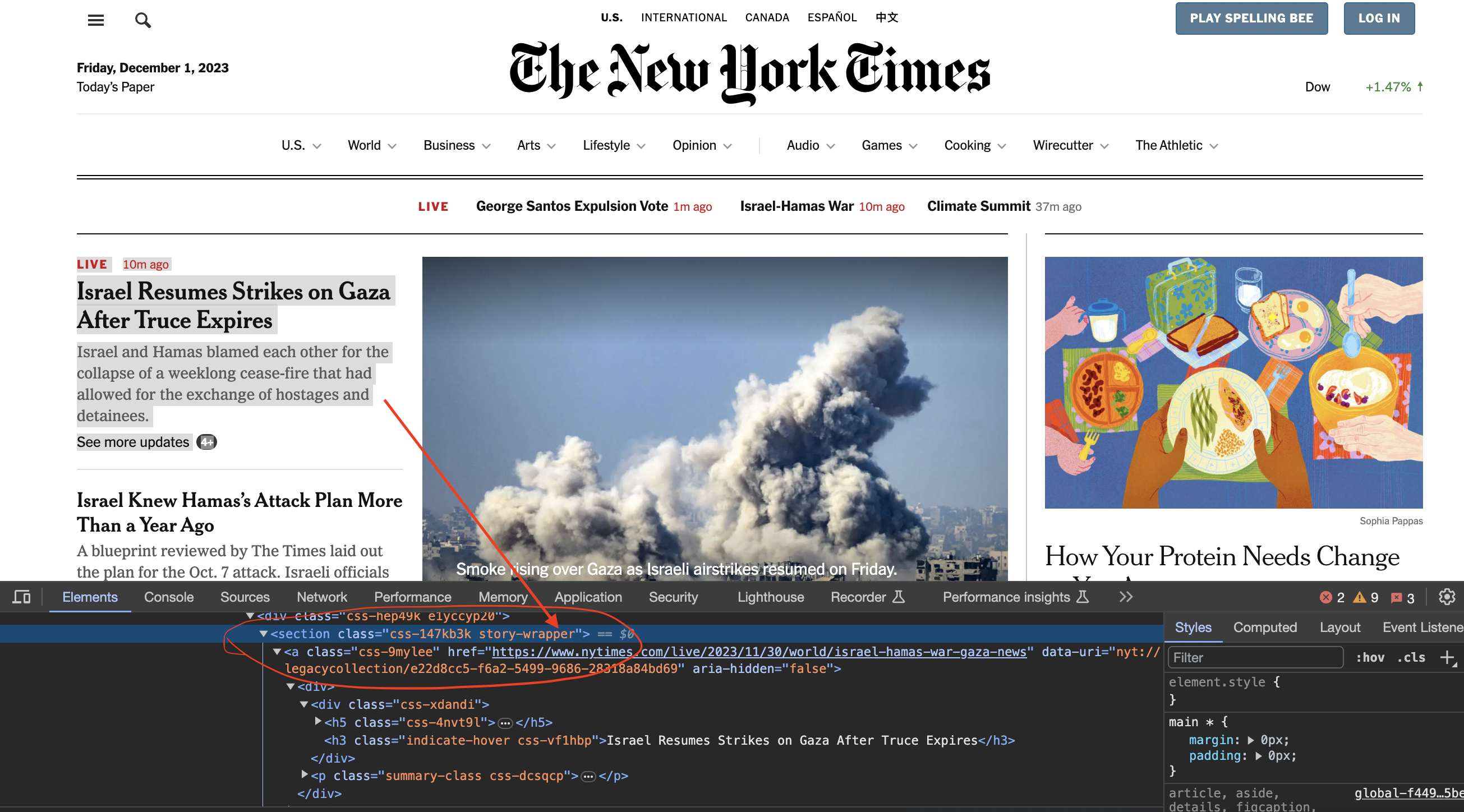
Elements articleSections = document.select("section.story-wrapper");
Here
Then we iterate through each article section and extract the headline and link using descendant selectors:
for (Element articleSection : articleSections) {
Element titleElement = articleSection.selectFirst("h3.indicate-hover");
Element linkElement = articleSection.selectFirst("a.css-9mylee");
if (titleElement != null && linkElement != null) {
String articleTitle = titleElement.text().trim();
String articleLink = linkElement.attr("href");
System.out.println("Title: " + articleTitle);
System.out.println("Link: " + articleLink);
}
}
The key ideas here are:
And that's the gist of this simple New York Times scraper! Jsoup handles the heavy lifting while we use CSS-style selectors to pinpoint the data we want.
Some ways you could expand on this:
Here is the full code:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class NYTimesScraper {
public static void main(String[] args) {
String url = "<https://www.nytimes.com/>";
try {
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
Document document = Jsoup.connect(url).userAgent(userAgent).get();
Elements articleSections = document.select("section.story-wrapper");
for (Element articleSection : articleSections) {
Element titleElement = articleSection.selectFirst("h3.indicate-hover");
Element linkElement = articleSection.selectFirst("a.css-9mylee");
if (titleElement != null && linkElement != null) {
String articleTitle = titleElement.text().trim();
String articleLink = linkElement.attr("href");
System.out.println("Title: " + articleTitle);
System.out.println("Link: " + articleLink);
}
}
} catch (IOException e) {
System.err.println("Failed to retrieve the web page: " + e.getMessage());
}
}
}
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.