Web scraping refers to programmatically extracting data from websites. We may want to scrape data for analysis, monitoring changes over time, aggregating information across sites, and more.
In this article, we'll walk through PHP code to scrape the titles and links of articles from the New York Times homepage.
Prerequisites
To follow along, you'll want a basic knowledge of:
We'll also use features like constants, arrays, loops, and object-oriented syntax.
Walkthrough
Let's go through each section of the code:
Define URLs and Constants
We start by defining the base New York Times URL and a user agent string constant that identifies us to the site:
// URLs and constants
define('URL', '<https://www.nytimes.com/>');
define('USER_AGENT', 'Mozilla/5.0...');
Defining reusable values up top keeps things clean.
Pro tip: Setting a common user agent tricks sites into thinking you're a normal browser rather than a bot!
Initialize Arrays to Store Data
We'll store the scraped headlines and links in PHP arrays, which we initialize empty:
// Initialize arrays
$titles = [];
$links = [];
Unlike some languages, PHP arrays don't need a pre-set capacity. They grow dynamically as we append data.
cURL Request
Here we use cURL to request the NYTimes homepage, setting key options:
// Curl request
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => URL,
CURLOPT_HTTPHEADER => ['User-Agent: ' . USER_AGENT],
CURLOPT_RETURNTRANSFER => true
]);
Curling here refers to transferring data to/from a URL. We configure cURL with the base URL, user agent from our constant earlier, and tell it to return (rather than print) response data.
Analogy: It's like an old-timey phone handset making a call to the NYTimes website and listening for the response.
Check Response
It's good practice to verify we got a proper response before trying to parse it:
// Send request
$response = curl_exec($ch);
$code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($code !== 200) {
die("Error: Failed to access {URL} - Status {$code}");
}
Here we execute the request, get the response code, and if it's not 200 OK, stop execution.
Pro tip: Always handle errors gracefully!
Parse HTML
Now we can parse the HTML response using DOMDocument:
// Load HTML
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($response);
Suppressing libxml errors avoids issues with imperfect HTML. We then load the HTML into a DOMDocument which allows accessing elements easily.
Fun fact: DOM stands for Document Object Model and represents the hierarchical structure of HTML.
Inspecting the page
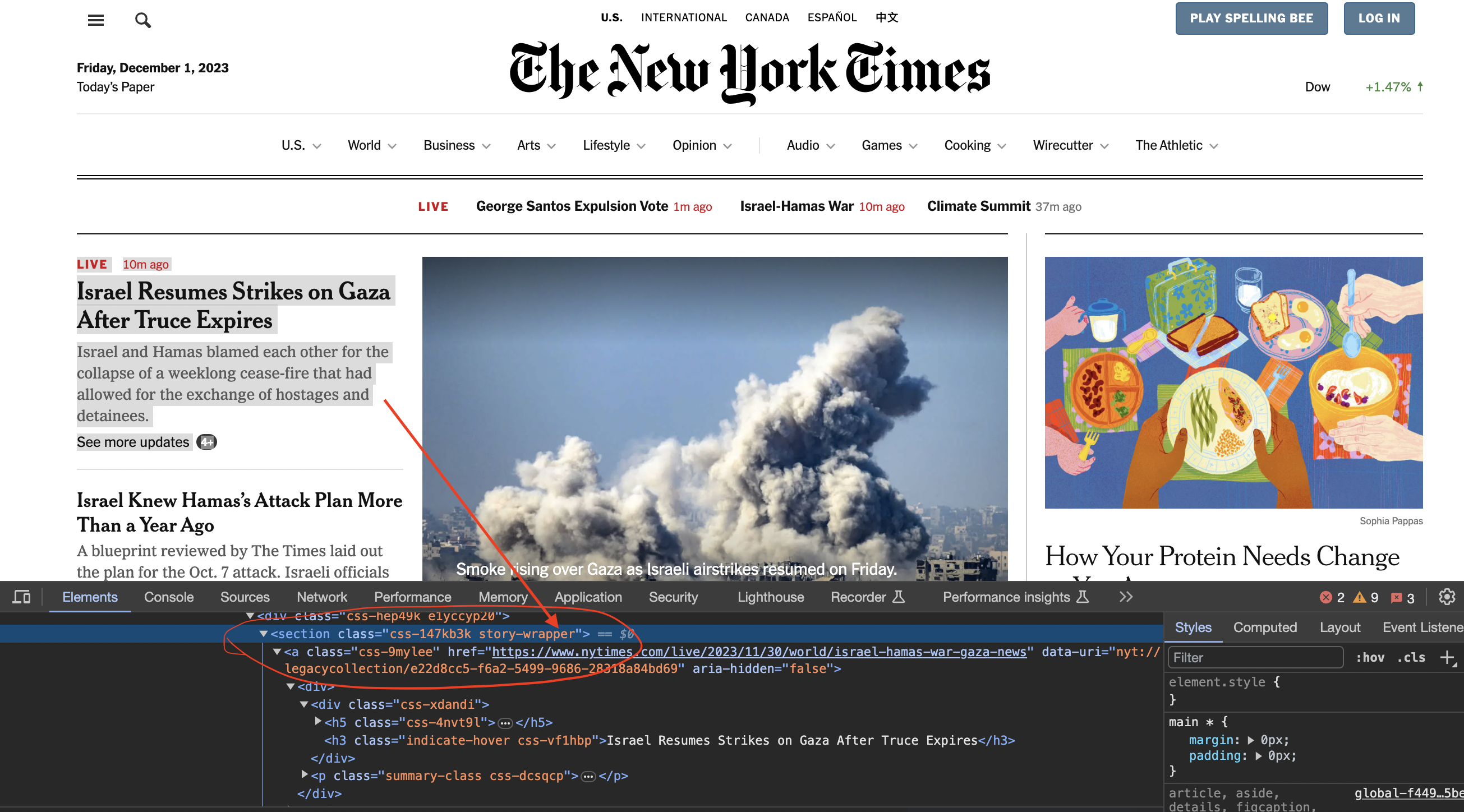
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
Iterate Sections
We can now iterate document sections and extract data:
// Iterate article sections
foreach ($doc->getElementsByTagName('section') as $section) {
// Check for story-wrapper
if ($section->getAttribute('class') === 'css-147kb3k story-wrapper') {
// Get title and link
$title = $section->getElementsByTagName('h3')->item(0);
$link = $section->getElementsByTagName('a')->item(0);
// Append extracted data
if ($title && $link) {
$titles[] = trim($title->textContent);
$links[] = $link->getAttribute('href');
}
}
}
Here we loop section elements, checking for story-wrappers. We grab the h3 and a elements to get titles/links, trim whitespace, and append results to our arrays from earlier.
Key ideas: Target elements by tag name and class, access child elements, attributes like href, and text content.
Output Data
Finally, we can output or use the data:
// Output data
foreach ($titles as $i => $title) {
echo "Title: {$title}<br>";
echo "Link: {$links[$i]}<br><br>";
}
This prints each title and corresponding link. The $i key lets us access the links array in parallel.
And we've now scraped NYTimes headlines! The full code is listed again below:
<?php
// URLs and constants
define('URL', 'https://www.nytimes.com/');
define('USER_AGENT', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36');
// Initialize arrays to store data
$titles = [];
$links = [];
// Curl request
$ch = curl_init();
curl_setopt_array($ch, [
CURLOPT_URL => URL,
CURLOPT_HTTPHEADER => ['User-Agent: ' . USER_AGENT],
CURLOPT_RETURNTRANSFER => true
]);
// Send request
$response = curl_exec($ch);
$code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
if ($code !== 200) {
die("Error: Failed to access {URL} - Status {$code}");
}
//echo $response;
// Load HTML
libxml_use_internal_errors(true);
$doc = new DOMDocument();
$doc->loadHTML($response);
// Iterate article sections directly
foreach ($doc->getElementsByTagName('section') as $section) {
// Check for story-wrapper section
//echo $section->getAttribute('class')."<br>";
if ($section->getAttribute('class') === 'css-147kb3k story-wrapper') {
// Get title and link
$title = $section->getElementsByTagName('h3')->item(0);
$link = $section->getElementsByTagName('a')->item(0);
// Append extracted data
if ($title && $link) {
$titles[] = trim($title->textContent);
$links[] = $link->getAttribute('href');
}
}
}
// Output data
foreach ($titles as $i => $title) {
echo "Title: {$title}<br>";
echo "Link: {$links[$i]}<br><br>";
}
?>Recap and Next Steps
Key steps we covered:
Main takeways:
To practice, try customizing the script:
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.