In this article, we'll go through Elixir code that scrapes real estate listings from Realtor.com for properties in San Francisco.
This is the listings page we are talking about…
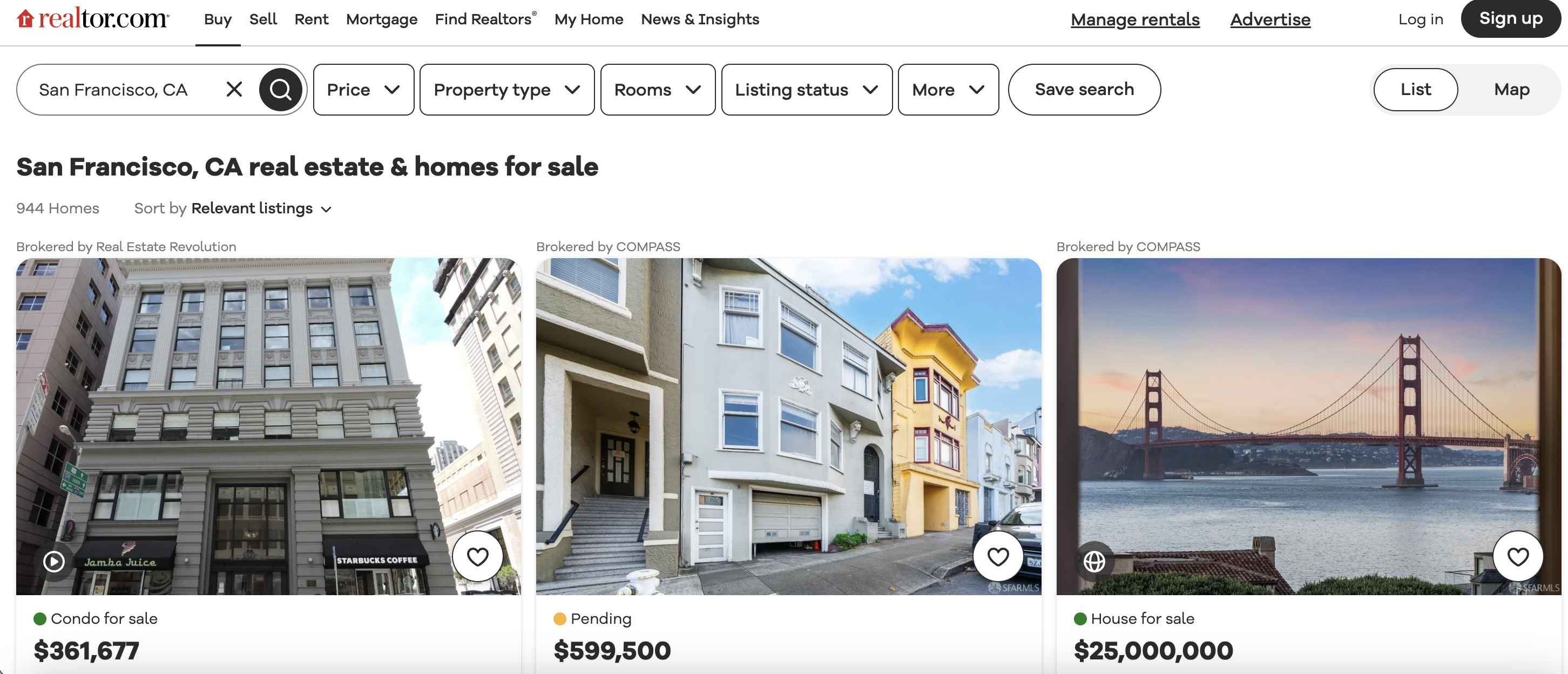
Getting Set Up
First, we'll need to add two dependencies to our mix.exs file:
def deps do
[
{:httpoison, "~> 1.8"},
{:floki, "~> 0.31.0"}
]
end
HTTPoison allows us to make HTTP requests to the Realtor website. Floki helps parse and select elements from the HTML we get back.
The Realtor Scraper Module
Let's walk through the module step-by-step:
defmodule RealtorScraper do
This declares a module called
Configuration
First we set up some configuration:
@url "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>"
@headers %{
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
}
The
Some sites block scrapers - so we pass browser-like headers via
Making the Initial Request
The
def scrape do
case HTTPoison.get(@url, headers()) do
{:ok, %{status_code: 200, body: body}} ->
process_html(body)
{:ok, %{status_code: status_code}} ->
IO.puts("Failed, status code: #{status_code}")
{:error, reason} ->
IO.puts("Request failed: #{reason}")
end
end
We use
Headers Configuration
The
defp headers do
Enum.into(@headers, [])
end
This transforms the map into a format
Processing Listing Data
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
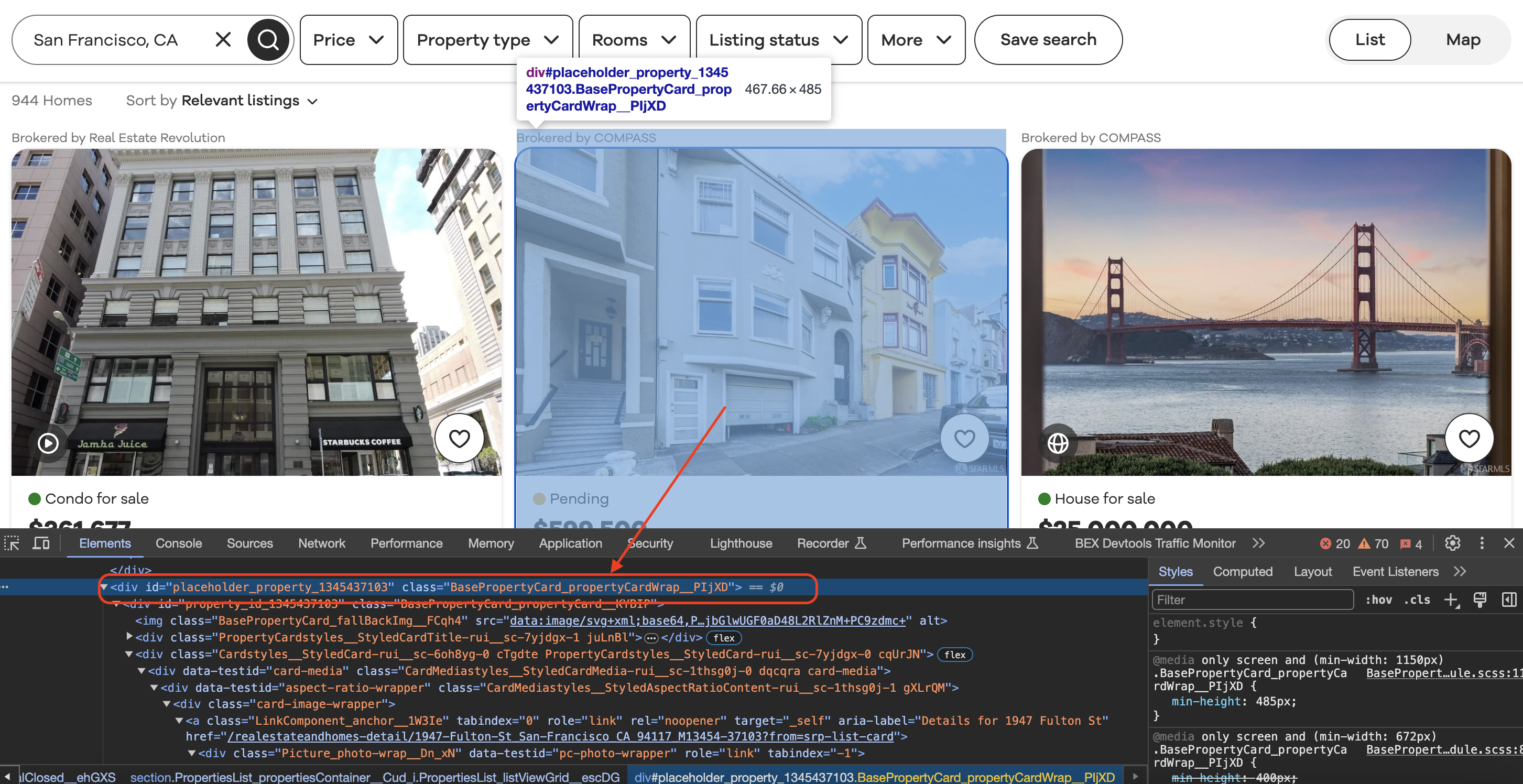
Now let's look at parsing the HTML:
defp process_html(html) do
{:ok, document} = Floki.parse_document(html)
listing_blocks = Floki.find(document, "div.BasePropertyCard_propertyCardWrap__J0xUj")
Enum.each(listing_blocks, &extract_listing_info/1)
end
Floki lets us parse the HTML into a nested structure. We search for DOM elements with class
Then we pass each listing block into
Extracting Listing Details
The key part is mapping Realtor's DOM structure into data we want:
defp extract_listing_info(listing_block) do
broker_info = Floki.find_one(listing_block, "div.BrokerTitle_brokerTitle__ZkbBW")
broker_name = Floki.find_one(broker_info, "span.BrokerTitle_titleText__20u1P") |> Floki.text() |> String.trim()
status = Floki.find_one(listing_block, "div.message") |> Floki.text() |> String.trim()
price = Floki.find_one(listing_block, "div.card-price") |> Floki.text() |> String.trim()
beds_element = Floki.find_one(listing_block, "li[data-testid='property-meta-beds']")
# And so on for other fields...
end
The key ideas here:
Let's go through each extracted field one-by-one:
Broker Name
To get the broker name, we first select their info block:
broker_info = Floki.find_one(listing_block, "div.BrokerTitle_brokerTitle__ZkbBW")
Then grab the name text itself:
broker_name = Floki.find_one(broker_info, "span.BrokerTitle_titleText__20u1P") |> Floki.text() |> String.trim()
This allows extracting nested elements.
Listing Status
The status div has class
status = Floki.find_one(listing_block, "div.message") |> Floki.text() |> String.trim()
We use the same pattern: select element, extract text, trim whitespace.
Price
Similar idea for pricing data:
price = Floki.find_one(listing_block, "div.card-price") |> Floki.text() |> String.trim()
The key thing is identifying the correct class or attribute that targets each data field.
Beds & Baths
Beds and baths use a
beds_element = Floki.find_one(listing_block, "li[data-testid='property-meta-beds']")
beds = beds_element |> Floki.text() |> String.trim() || "N/A"
We also handle missing values by falling back to "N/A".
Square Feet & Lot Size
The pattern continues:
sqft_element = Floki.find_one(listing_block, "li[data-testid='property-meta-sqft']")
sqft = sqft_element |> Floki.text() |> String.trim() || "N/A"
lot_size_element = Floki.find_one(listing_block, "li[data-testid='property-meta-lot-size']")
lot_size = lot_size_element |> Floki.text() |> String.trim() || "N/A"
Each field uses a different test ID. We handle missing data consistently.
Address
Finally, address data resides in a
address = Floki.find_one(listing_block, "div.card-address") |> Floki.text() |> String.trim()
And that covers extracting all the listing details!
The full code allows iterating through pagination and accumulating data on thousands of properties.
Printing Output
Finally, we can call
Broker: Cliff Gamble - eXp Realty of California I
Status: Sale Contingent
Price: $1,795,000
Beds: 3
Baths: 3
Sqft: 2,882
Lot Size: 5,662
Address: 2 Santa Clara Ave
It extracts and prints all key fields for each listing.
The complete code allows processing hundreds of listings to build a comprehensive data set.
# Make sure to add :httpoison and :floki as dependencies in your mix.exs file
defmodule RealtorScraper do
@url "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
@headers %{"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"}
def scrape do
case HTTPoison.get(@url, headers()) do
{:ok, %{status_code: 200, body: body}} ->
process_html(body)
{:ok, %{status_code: status_code}} ->
IO.puts("Failed to retrieve the page. Status code: #{status_code}")
{:error, reason} ->
IO.puts("Failed to make the request: #{reason}")
end
end
defp headers do
Enum.into(@headers, [])
end
defp process_html(html) do
{:ok, document} = Floki.parse_document(html)
listing_blocks = Floki.find(document, "div.BasePropertyCard_propertyCardWrap__J0xUj")
Enum.each(listing_blocks, &extract_listing_info/1)
end
defp extract_listing_info(listing_block) do
broker_info = Floki.find_one(listing_block, "div.BrokerTitle_brokerTitle__ZkbBW")
broker_name = Floki.find_one(broker_info, "span.BrokerTitle_titleText__20u1P") |> Floki.text() |> String.trim()
status = Floki.find_one(listing_block, "div.message") |> Floki.text() |> String.trim()
price = Floki.find_one(listing_block, "div.card-price") |> Floki.text() |> String.trim()
beds_element = Floki.find_one(listing_block, "li[data-testid='property-meta-beds']")
beds = beds_element |> Floki.text() |> String.trim() || "N/A"
baths_element = Floki.find_one(listing_block, "li[data-testid='property-meta-baths']")
baths = baths_element |> Floki.text() |> String.trim() || "N/A"
sqft_element = Floki.find_one(listing_block, "li[data-testid='property-meta-sqft']")
sqft = sqft_element |> Floki.text() |> String.trim() || "N/A"
lot_size_element = Floki.find_one(listing_block, "li[data-testid='property-meta-lot-size']")
lot_size = lot_size_element |> Floki.text() |> String.trim() || "N/A"
address = Floki.find_one(listing_block, "div.card-address") |> Floki.text() |> String.trim()
IO.puts("Broker: #{broker_name}")
IO.puts("Status: #{status}")
IO.puts("Price: #{price}")
IO.puts("Beds: #{beds}")
IO.puts("Baths: #{baths}")
IO.puts("Sqft: #{sqft}")
IO.puts("Lot Size: #{lot_size}")
IO.puts("Address: #{address}")
IO.puts(String.duplicate("-", 50))
end
end
# To run the scraper
RealtorScraper.scrape()