Have you ever wanted to analyze real estate listing data from sites like Realtor.com? Web scraping using tools like Jsoup provide a powerful way to automatically extract that data for custom analysis.
This is the listings page we are talking about…
In this comprehensive guide for beginners, you'll learn step-by-step how to use Jsoup to scrape key details from Realtor listings in Kotlin. Follow along to get hands-on practice with core scraping concepts like:
We'll go extremely in-depth on the most complex part - the CSS selectors - since that's what allows extracting the right data points.
By the end, you'll understand how each piece of this scraper works to extract details like:
...and more from any result on a Realtor.com search page!
The code can work as-is to scrape listings for any city, while what you learn will apply to building scrapers for virtually any site.
Let's dig in!
Scraping Overview
First, what exactly happens in this program?
At a high level, it:
- Sends a GET request to retrieve the HTML from a Realtor search URL
- Parses the HTML
- Uses CSS selectors to pinpoint specific elements
- Extracts text from those elements 5.Outputs the extracted details
That's web scraping in a nutshell! It allows gathering structured data from sites even if they don't have public APIs.
Now let's break down the process for this specific scraper...
Importing Jsoup
Jsoup handles most of the heavy lifting for us. To start, we import it:
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
This gives access to all the scraping functionality.
We'll see examples later of how these work together.
Defining the Target URL
The first step is choosing what page to scrape. In this case, we want results from a Realtor search:
val url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>"
This URL will contain many individual property listings we want to extract details from.
Good to Know Tip: You can tweak the location in the URL to scrape other cities!
Creating a User Agent Header
Websites detect programmatic access like scrapers by looking for missing browser characteristics like user agent strings.
To mimic a real browser, we pass a user agent header:
val userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
This spoofed string matches Chrome on Windows 10.
Pro Tip: I recommend services like https://www.whatismybrowser.com to get your actual browser's user agent string for scraping to better blend in!
Fetching the Page HTML
With the target URL and user agent defined, Jsoup can now grab the page HTML:
val doc = Jsoup.connect(url).userAgent(userAgent).get()
Breaking this down:
The returned
We can check
Lightbulb Moment: The user agent header tricks Realtor.com into thinking the request came from a real browser!
Selecting Elements to Scrape
Here's where the real magic happens - using CSS selectors to pinpoint parts of the page to extract.
Understanding CSS Selectors
CSS selectors allow targeting HTML elements by their id, class, tag name, attributes, hierarchy in the DOM tree and more.
Some examples:
/* Target element with id property matching "myId" */
#myId
/* Target elements with class name matching "myClass" */
.myClass
/* Target h1 elements */
h1
/* Target elements with attribute name="value" */
[name="value"]
Jsoup translates these selectors into matching Java Element objects from the HTML.
The full syntax and possibilities get complex, but as you'll see, just a few selector types cover most scraping cases!
Selecting Realtor Listing Blocks
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
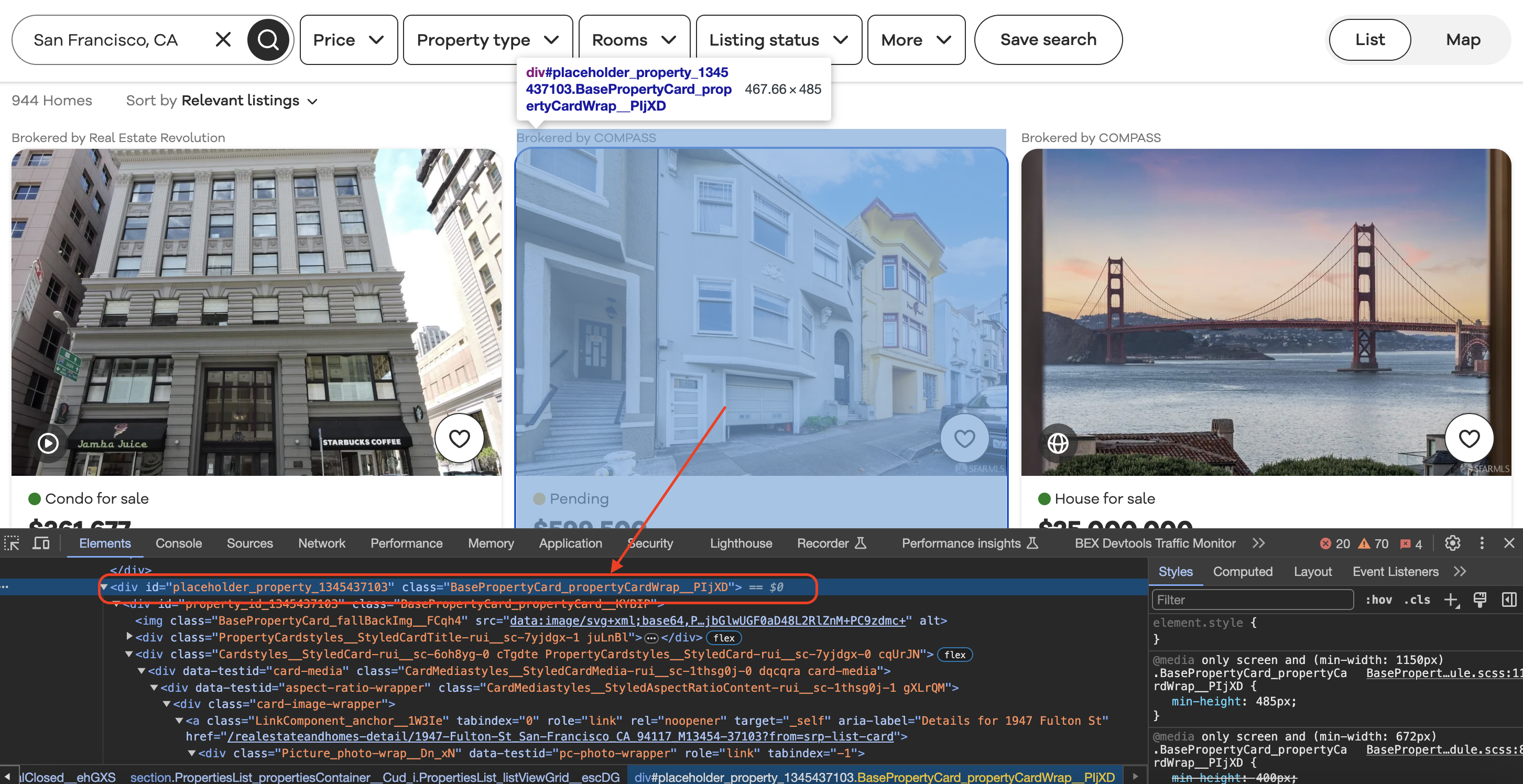
Now back to our program...
The first thing we want is each overall listing block from the page. Realtor conveniently marks these with a class name:
val listingBlocks = doc.select("div.BasePropertyCard\\_propertyCardWrap\\_\\_J0xUj")
Breaking this selector down:
This matches all Jsoup returns a list of Element objects representing each matching block. Pro Tip: Most scrapers start by identifying these wrapper containers around the actual target data. Within each listing block lies the useful info like price and broker details. To extract those values, the selectors dig deeper into the block's hierarchy: Here's what's happening: This drills down multiple levels to get the desired text! It follows a similar pattern for all fields: Finding the right selectors takes experimentation - viewing the page HTML and trial and error. Tools like the browser Developer Tools help speed this up too! But the patterns are consistent: Practice Tip: Try tweaking the selectors in this code and observe the impact! Finally, with all the key details extracted, we simply print them out: The end result shows all listings, neatly formatted with the scraped information. And there you have it - from connecting to the page to extracting each field, that's everything this scraper is doing under the hood! Let's recap some key lessons around Jsoup and web scraping: The concepts apply the same whether scraping listings, articles or any other site content. While it takes practice, scraping opens up countless possibilities to utilize web data in your programs! For reference, here is the complete code once more:
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html>Extracting Listing Details
Broker Info
val brokerInfo = listingBlock.selectFirst("div.BrokerTitle\\_brokerTitle\\_\\_ZkbBW")
val brokerName = brokerInfo?.selectFirst("span.BrokerTitle\\_titleText\\_\\_20u1P")?.text()?.trim() ?: "N/A"
Other Examples
val status = listingBlock.selectFirst("div.message")?.text()?.trim() ?: "N/A"
val price = listingBlock.selectFirst("div.card-price")?.text()?.trim() ?: "N/A"
val bedsElement = listingBlock.selectFirst("li\\[data-testid=property-meta-beds\\]")
// ...get text from bedsElement
Outputting Scraped Data
println("Broker: $brokerName")
println("Status: $status")
println("Price: $price")
// ...
Key Takeways
Full Code
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
fun main() {
// Define the URL of the Realtor.com search page
val url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
// Define a User-Agent header
val userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
// Send a GET request to the URL with the User-Agent header
val doc = Jsoup.connect(url).userAgent(userAgent).get()
// Check if the request was successful (status code 200)
if (doc != null) {
// Find all the listing blocks using the provided class name
val listingBlocks = doc.select("div.BasePropertyCard_propertyCardWrap__J0xUj")
// Loop through each listing block and extract information
for (listingBlock in listingBlocks) {
// Extract the broker information
val brokerInfo = listingBlock.selectFirst("div.BrokerTitle_brokerTitle__ZkbBW")
val brokerName = brokerInfo?.selectFirst("span.BrokerTitle_titleText__20u1P")?.text()?.trim() ?: "N/A"
// Extract the status (e.g., For Sale)
val status = listingBlock.selectFirst("div.message")?.text()?.trim() ?: "N/A"
// Extract the price
val price = listingBlock.selectFirst("div.card-price")?.text()?.trim() ?: "N/A"
// Extract other details like beds, baths, sqft, and lot size
val bedsElement = listingBlock.selectFirst("li[data-testid=property-meta-beds]")
val bathsElement = listingBlock.selectFirst("li[data-testid=property-meta-baths]")
val sqftElement = listingBlock.selectFirst("li[data-testid=property-meta-sqft]")
val lotSizeElement = listingBlock.selectFirst("li[data-testid=property-meta-lot-size]")
// Check if the elements exist before extracting their text
val beds = bedsElement?.text()?.trim() ?: "N/A"
val baths = bathsElement?.text()?.trim() ?: "N/A"
val sqft = sqftElement?.text()?.trim() ?: "N/A"
val lotSize = lotSizeElement?.text()?.trim() ?: "N/A"
// Extract the address
val address = listingBlock.selectFirst("div.card-address")?.text()?.trim() ?: "N/A"
// Print the extracted information
println("Broker: $brokerName")
println("Status: $status")
println("Price: $price")
println("Beds: $beds")
println("Baths: $baths")
println("Sqft: $sqft")
println("Lot Size: $lotSize")
println("Address: $address")
println("-".repeat(50)) // Separating listings
}
} else {
println("Failed to retrieve the page.")
}
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...