Overview
We will write code to extract real estate listing data from Realtor.com for properties in San Francisco. Our code will make a request to the Realtor.com website, loads the HTML content of the search result page, then uses Cheerio to target specific elements in the HTML to extract useful information about each listed property.
This is the listings page we are talking about…
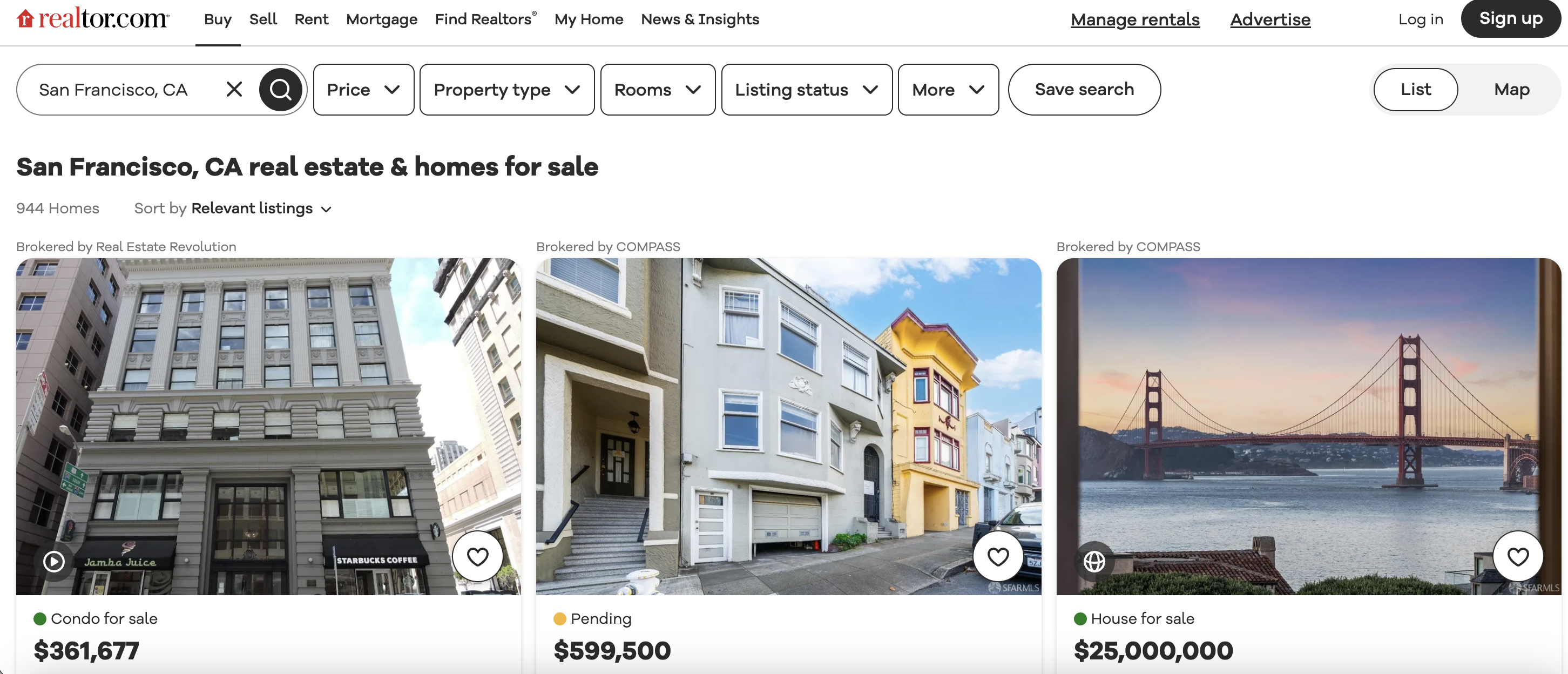
Some key things it will extract for every listing:
Let's dive into the details and see how it works!
Importing Libraries
const axios = require('axios');
const cheerio = require('cheerio');
First, we import Axios and Cheerio using require.
Axios allows us to make HTTP requests to load content from websites.
Cheerio allows us to parse and target parts of the loaded HTML using jQuery style selectors.
Defining the URL
const url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
The URL is defined for the Realtor.com page that will be scraped. We are targeting the San Francisco real estate listings specifically.
Setting User Agent
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
};
We set a User-Agent header that identifies the client making the requests as a Chrome browser. This helps avoid blocked requests.
Making GET Request with Axios
axios.get(url, {headers})
.then(response => {
// Process response
});
This axios GET request fetches the content of the defined Realtor.com URL.
The headers are passed in to include the User-Agent string.
Loading HTML and Using Cheerio
const $ = cheerio.load(response.data);
On a successful response, we load the HTML content from response.data into Cheerio using the
This allows us to then use Cheerio to target elements on the page using CSS selectors.
Finding Listing Blocks
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
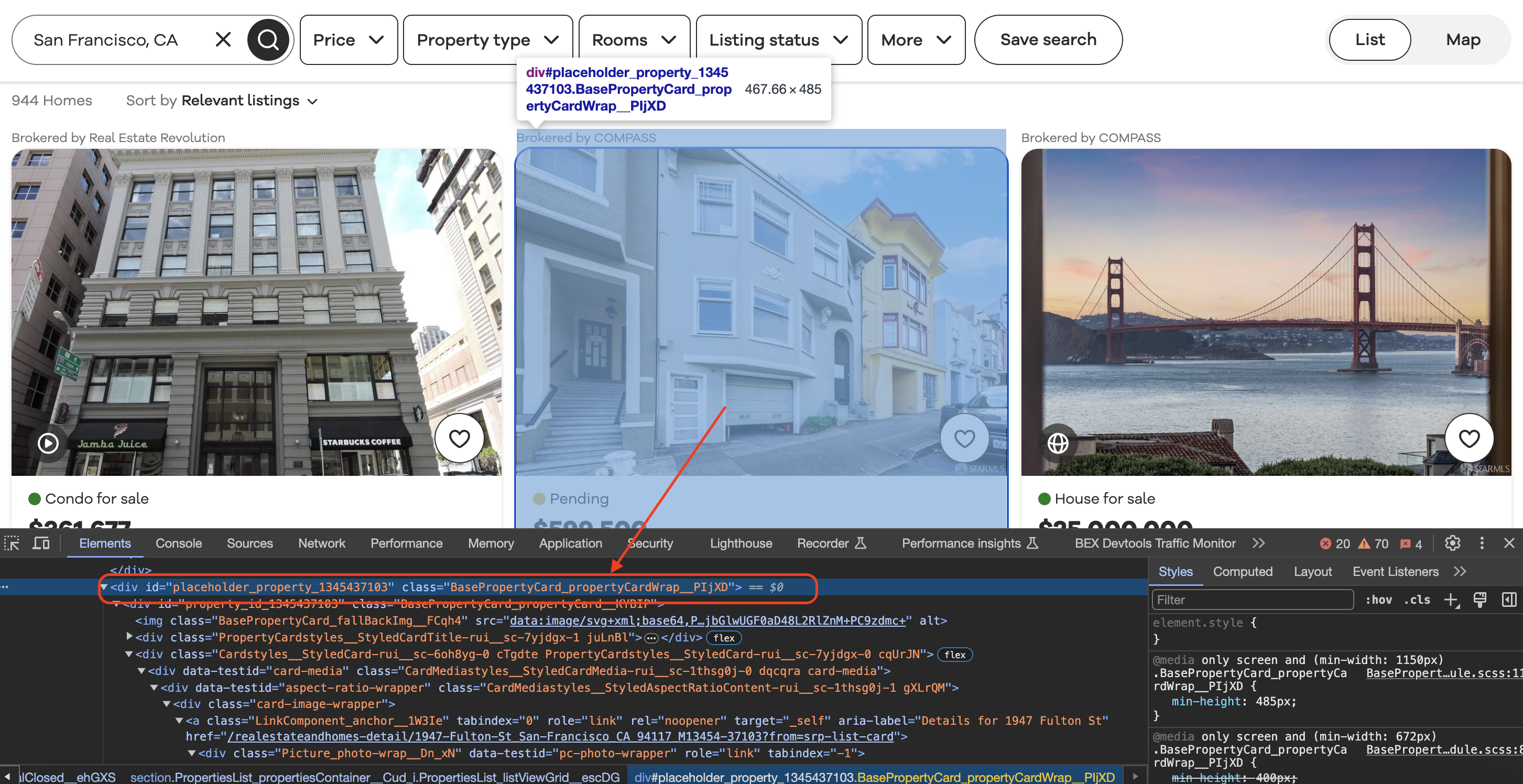
const listing_blocks = $("div.BasePropertyCard_propertyCardWrap__J0xUj");
Here we target all the This allows us to isolate listing content from the rest of the page. Next, we loop through each listing block and use selectors to extract details: Breaking down one example for beds: Refers to the current listing block element in the loop Finally The || "N/A" sets a fallback value if no beds data exists for that listing And the const beds saves this value for usage The process is similar for every other bit of data extracted. This allows us to pull all the relevant data for each individual property listing on the page. At the end, the code logs everything extracted to the console, listing by listing: So the final output will show broker name, beds, baths, pricing, address etc. for every property listing extracted from the page. That covers the key functionality of how this code is able to scrape multiple real estate listing details from Realtor.com leveraging Axios to load page content and Cheerio to parse and target specific HTML elements on the page. The key patterns allow it to structurally isolate listing blocks and then individually extract different data points for each listing. Full code:
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html>Extracting Listing Data
listing_blocks.each((index, element) => {
// Extract broker name
const broker_name = $(element).find("span.BrokerTitle_titleText__20u1P").text().trim();
// Extract status
const status = $(element).find("div.message").text().trim();
// Extract price
const price = $(element).find("div.card-price").text().trim();
// Extract beds, baths, sqft, lot size
const beds = $(element).find("li[data-testid='property-meta-beds']").text().trim() || "N/A";
const baths = $(element).find("li[data-testid='property-meta-baths']").text().trim() || "N/A";
// Extract address
const address = $(element).find("div.card-address").text().trim();
});
$(element)
Console Output
Console.log("Broker:", broker_name);
Console.log("Beds:", beds);
Console.log("Address:", address);
Conclusion
const axios = require('axios');
const cheerio = require('cheerio');
// Define the URL of the Realtor.com search page
const url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
// Define a User-Agent header
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" // Replace with your User-Agent string
};
// Send a GET request to the URL with the User-Agent header using axios
axios.get(url, { headers })
.then(response => {
// Check if the request was successful (status code 200)
if (response.status === 200) {
// Load the HTML content of the page using Cheerio
const $ = cheerio.load(response.data);
// Find all the listing blocks using the provided class name
const listing_blocks = $("div.BasePropertyCard_propertyCardWrap__J0xUj");
// Loop through each listing block and extract information
listing_blocks.each((index, element) => {
// Extract the broker information
const broker_info = $(element).find("div.BrokerTitle_brokerTitle__ZkbBW");
const broker_name = broker_info.find("span.BrokerTitle_titleText__20u1P").text().trim();
// Extract the status (e.g., For Sale)
const status = $(element).find("div.message").text().trim();
// Extract the price
const price = $(element).find("div.card-price").text().trim();
// Extract other details like beds, baths, sqft, and lot size
const beds_element = $(element).find("li[data-testid='property-meta-beds']");
const baths_element = $(element).find("li[data-testid='property-meta-baths']");
const sqft_element = $(element).find("li[data-testid='property-meta-sqft']");
const lot_size_element = $(element).find("li[data-testid='property-meta-lot-size']");
// Check if the elements exist before extracting their text
const beds = beds_element.text().trim() || "N/A";
const baths = baths_element.text().trim() || "N/A";
const sqft = sqft_element.text().trim() || "N/A";
const lot_size = lot_size_element.text().trim() || "N/A";
// Extract the address
const address = $(element).find("div.card-address").text().trim();
// Print the extracted information
console.log("Broker:", broker_name);
console.log("Status:", status);
console.log("Price:", price);
console.log("Beds:", beds);
console.log("Baths:", baths);
console.log("Sqft:", sqft);
console.log("Lot Size:", lot_size);
console.log("Address:", address);
console.log("-".repeat(50)); // Separating listings
});
} else {
console.log("Failed to retrieve the page. Status code:", response.status);
}
})
.catch(error => {
console.error("An error occurred:", error);
});Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...