This article will provide a step-by-step walkthrough of code to scrape real estate listings from Realtor.com. The goal is to explain the key concepts and code structure to help beginners understand how to extract data from websites using web scraping.
This is the listings page we are talking about…
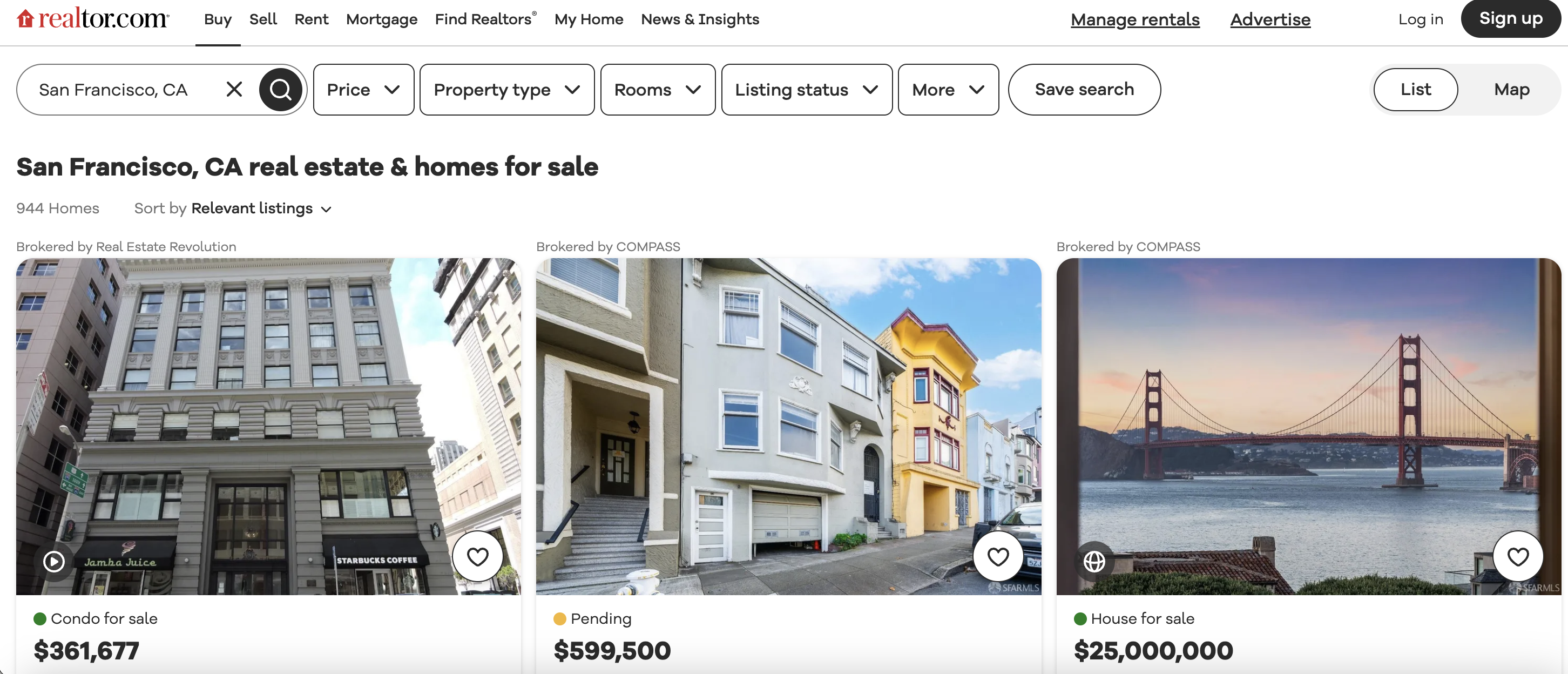
Introduction
Below is full Perl code to scrape details about property listings from Realtor.com for the San Francisco area. This includes information like the listing broker, price, number of beds/baths, square footage, etc.
We'll break down exactly how this works, focusing especially on the XPath selectors used to extract the data. This article won't get into debates around the ethics of web scraping - the purpose is solely to understand the code.
Required Modules
The code starts by importing a few key modules:
use LWP::UserAgent;
use HTML::TreeBuilder::XPath;
Briefly:
No need to fully understand these now, just know they provide critical web scraping functionality.
Define URL and User Agent
Next we set up the URL to scrape and configure a User-Agent header:
my $url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
my $ua = LWP::UserAgent->new;
$ua->agent("Mozilla/5.0..."); // Full browser user agent
This URL points to Realtor.com results for San Francisco. The User-Agent makes our requests look like they came from a real browser.
Send Request and Parse Response
We send a GET request to fetch the page content:
my $response = $ua->get($url);
Then we check that it succeeded with a 200 status code before parsing the HTML:
if ($response->is_success) {
my $tree = HTML::TreeBuilder::XPath->new_from_content($response->content);
// ... extract data here ...
}
The
Extracting Listing Data with XPath
Now we arrive at the key part - using XPath expressions to extract details about each property listing on the results page.
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
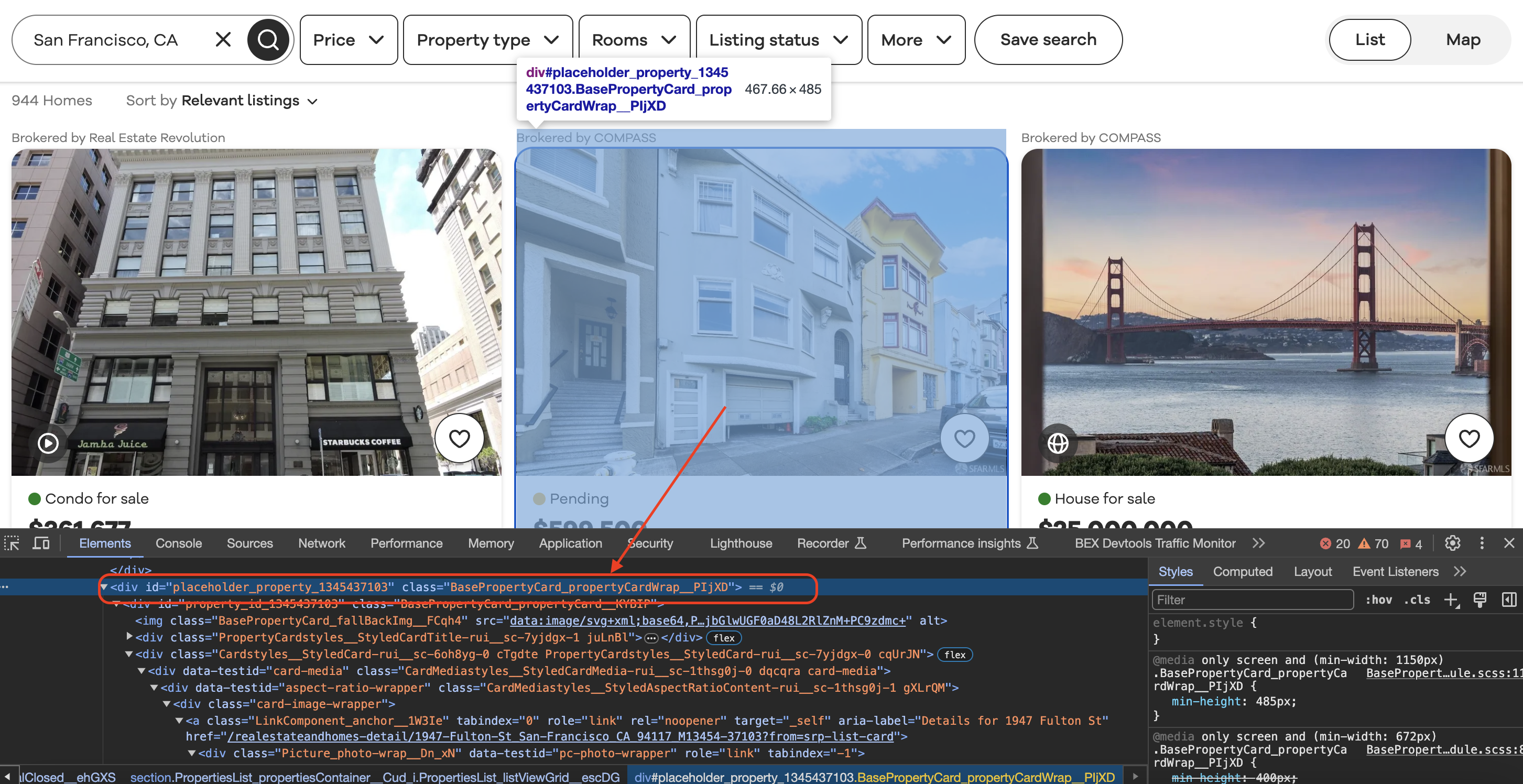
The listings are contained in
<div class="BasePropertyCard_propertyCardWrap__J0xUj">
We grab all of them with this XPath selector:
my @listing_blocks = $tree->findnodes('//div[contains(@class,"BasePropertyCard_propertyCardWrap__J0xUj")]');
Let's break this down:
We'll loop through each listing block and extract details using more XPath queries...
Broker Name
The broker name is stored nested like:
<div class="BrokerTitle_brokerTitle__ZkbBW">
<span class="BrokerTitle_titleText__20u1P">Keller Williams</span>
</div>
We handle this with:
my $broker_info = $listing_block->findvalue('.//div[contains(@class,"BrokerTitle_brokerTitle__ZkbBW")]');
my ($broker_name) = $broker_info =~ /<span[^>]+class="BrokerTitle_titleText__20u1P"[^>]*>(.+?)<\\/span>/;
Breaking this down:
Listing Status
The status text (e.g. "For Sale") resides in:
<div class="message">For Sale</div>
We grab it through:
my $status = $listing_block->findvalue('.//div[contains(@class,"message")]');
Price
Similarly, the price element looks like:
<div class="card-price">$699,000</div>
Extract with:
my $price = $listing_block->findvalue('.//div[contains(@class,"card-price")]');
And so on for other fields like beds, baths, square footage, etc. Each has a
Output Results
Finally, a few
print("Broker: $broker\\_name\\n");
print("Status: $status\\n");
print("Price: $price\\n");
// ...
And that's the key functionality covered! The full code can be found in the next section.
While long, this ultimately shows how we can traverse HTML structures and pull data with XPath selectors. With some practice, you'll get the hang of common patterns.
Full Code
Here is the complete code example for reference:
use strict;
use warnings;
use LWP::UserAgent;
use HTML::TreeBuilder::XPath;
# Define the URL of the Realtor.com search page
my $url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
# Define a User-Agent header
my $ua = LWP::UserAgent->new;
$ua->agent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36");
# Send a GET request to the URL with the User-Agent header
my $response = $ua->get($url);
# Check if the request was successful (status code 200)
if ($response->is_success) {
# Parse the HTML content of the page using HTML::TreeBuilder::XPath
my $tree = HTML::TreeBuilder::XPath->new_from_content($response->content);
# Find all the listing blocks using the provided class name
my @listing_blocks = $tree->findnodes('//div[contains(@class,"BasePropertyCard_propertyCardWrap__J0xUj")]');
# Loop through each listing block and extract information
foreach my $listing_block (@listing_blocks) {
# Extract the broker information
my $broker_info = $listing_block->findvalue('.//div[contains(@class,"BrokerTitle_brokerTitle__ZkbBW")]');
my ($broker_name) = $broker_info =~ /<span[^>]*class="BrokerTitle_titleText__20u1P"[^>]*>(.*?)<\/span>/;
# Extract the status (e.g., For Sale)
my $status = $listing_block->findvalue('.//div[contains(@class,"message")]');
# Extract the price
my $price = $listing_block->findvalue('.//div[contains(@class,"card-price")]');
# Extract other details like beds, baths, sqft, and lot size
my $beds_element = $listing_block->findvalue('.//li[@data-testid="property-meta-beds"]');
my $baths_element = $listing_block->findvalue('.//li[@data-testid="property-meta-baths"]');
my $sqft_element = $listing_block->findvalue('.//li[@data-testid="property-meta-sqft"]');
my $lot_size_element = $listing_block->findvalue('.//li[@data-testid="property-meta-lot-size"]');
# Check if the elements exist before extracting their text
my $beds = $beds_element || "N/A";
my $baths = $baths_element || "N/A";
my $sqft = $sqft_element || "N/A";
my $lot_size = $lot_size_element || "N/A";
# Extract the address
my $address = $listing_block->findvalue('.//div[contains(@class,"card-address")]');
# Print the extracted information
print("Broker: $broker_name\n");
print("Status: $status\n");
print("Price: $price\n");
print("Beds: $beds\n");
print("Baths: $baths\n");
print("Sqft: $sqft\n");
print("Lot Size: $lot_size\n");
print("Address: $address\n");
print("-" x 50 . "\n"); # Separating listings
}
} else {
print("Failed to retrieve the page. Status code: " . $response->code . "\n");
}Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
Try ProxiesAPI for free
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...