While debates around the ethics of web scraping continue, the practice remains a useful way for developers to extract data from websites. In this beginner-focused tutorial, we'll walk through a full code example for scraping key details from real estate listings on Realtor.com using a Java library called Jsoup.
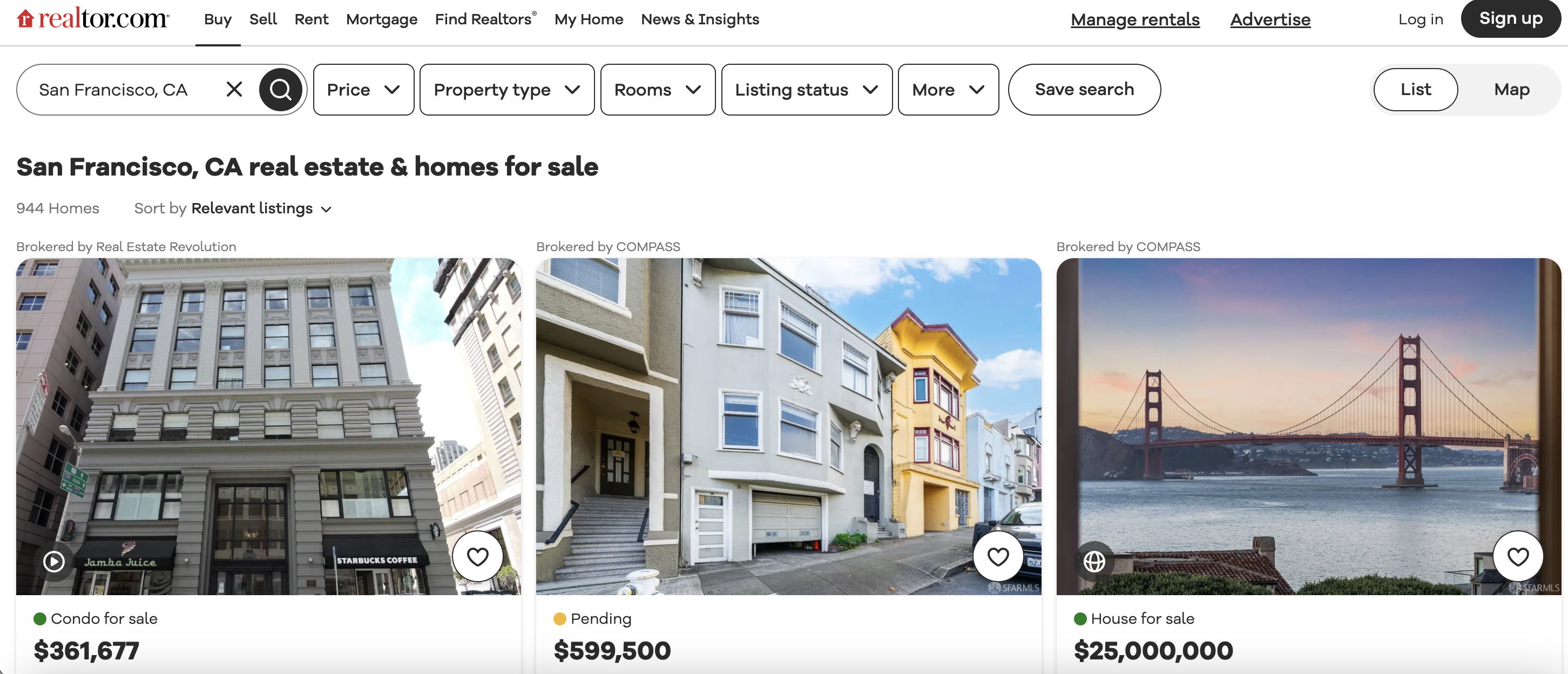
This is the listings page we are talking about…
Getting Set Up
Before we dive into the code, you'll need to install Jsoup if you don't already have it. You can add this dependency in your project's build tool, such as Gradle or Maven. Here's an example for Gradle:
implementation 'org.jsoup:jsoup:1.14.3'
And for Maven:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.14.3</version>
</dependency>
Now we're ready to scrape!
Connecting to the Page
Let's explore what's happening section-by-section:
// Define the URL of the Realtor.com search page
val url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>"
We specify the exact Realtor URL that we want to scrape. This will contain the listings for San Francisco when visited in a browser.
// Set the User-Agent header
val userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
Next we set the User-Agent header to mimic a Chrome browser visit. Many sites check this header to determine if the visitor is a real browser or an automated program.
// Fetch the HTML content of the page
val doc: Document = Jsoup.connect(url).userAgent(userAgent).get()
We use Jsoup to connect to the Realtor URL, passing in that User-Agent string we set. Jsoup downloads (or "fetches") the full HTML content from that page and stores it for us to work with in the
Tip: I find it helpful to think of this like browsing to the page and doing "View Source" to see all the underlying HTML. Jsoup handles that part for us programmatically.
Now let's move on to the most critical part - actually extracting information from that HTML using CSS selectors!
Extracting Data with Selectors
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
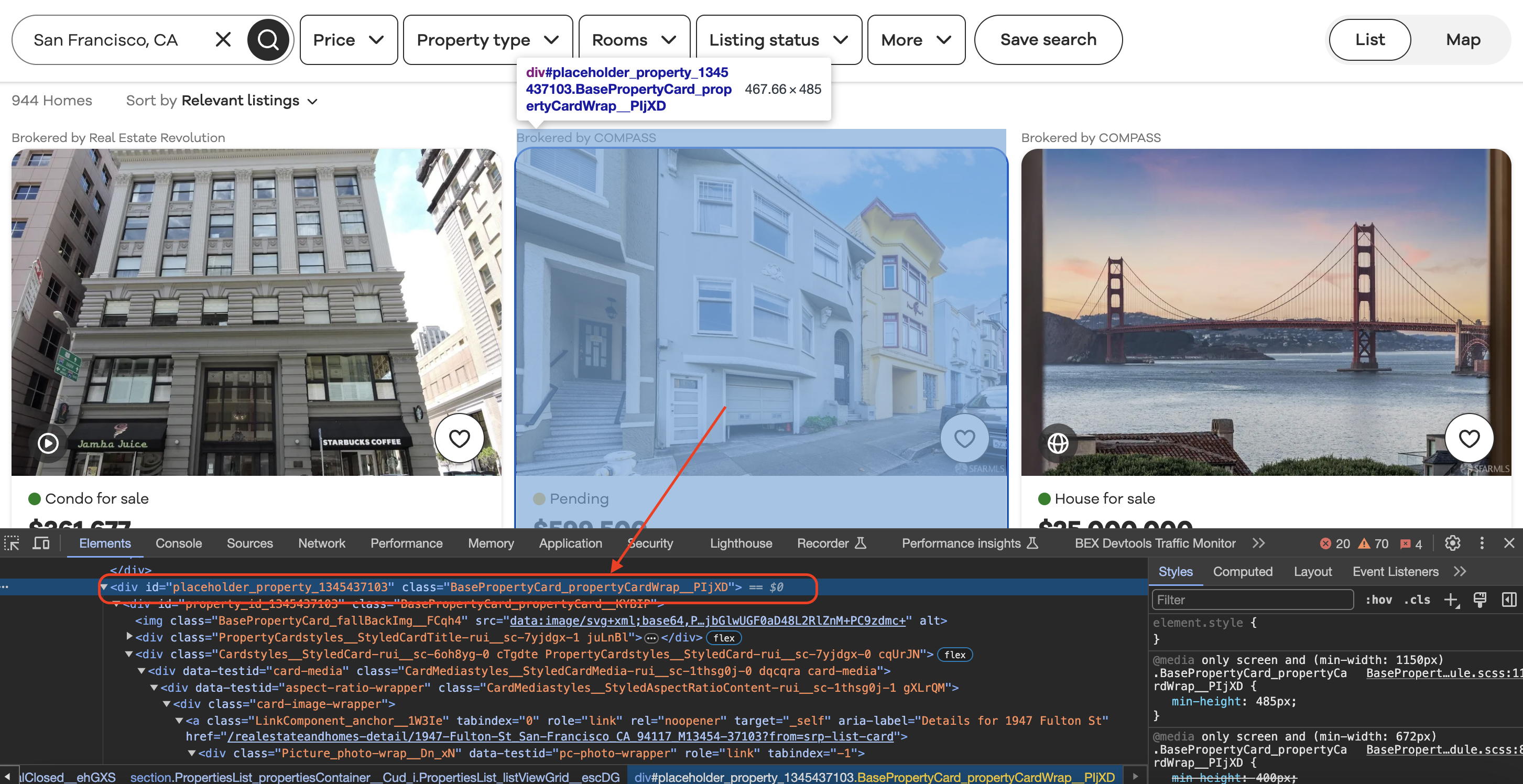
// Find all the listing blocks using the provided class name
val listingBlocks: Seq[Element] = doc.select("div.BasePropertyCard_propertyCardWrap__J0xUj")
The main listings on Realtor.com are contained in
We use Jsoup's
Tip: You can discover class names to target by inspecting elements in your browser's dev tools. The styles and classes applied to each element are visible there.
Now we can iterate through each listing:
for (listingBlock <- listingBlocks) {
// Extract data from each listingBlock
}
And inside that loop, we use additional selectors to pull text from specific tags:
val brokerName: String = listingBlock.selectFirst("span.BrokerTitle_titleText__20u1P").text()
This selector finds the
Let's break down that selector:
We use very similar selectors to extract other data points like status, price, beds, baths etc.:
val status: String = listingBlock.selectFirst("div.message").text()
val price: String = listingBlock.selectFirst("div.card-price").text()
// And so on...
Notice how on some we look for a
Here a few key advantages of using selectors:
Now you have a high-level look at how Jsoup connects to pages and uses CSS selector queries to extract key listings details! Let's look at the full code for reference...
Full Code
import org.jsoup.Jsoup
import org.jsoup.nodes.Document
import org.jsoup.nodes.Element
object RealtorScraper {
def main(args: Array[String]): Unit = {
// Define the URL of the Realtor.com search page
val url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
// Set the User-Agent header
val userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
try {
// Fetch the HTML content of the page
val doc: Document = Jsoup.connect(url).userAgent(userAgent).get()
// Find all the listing blocks using the provided class name
val listingBlocks: Seq[Element] = doc.select("div.BasePropertyCard_propertyCardWrap__J0xUj")
// Loop through each listing block and extract information
for (listingBlock <- listingBlocks) {
// Extract the broker information
val brokerInfo: Element = listingBlock.selectFirst("div.BrokerTitle_brokerTitle__ZkbBW")
val brokerName: String = brokerInfo.selectFirst("span.BrokerTitle_titleText__20u1P").text()
// Extract the status (e.g., For Sale)
val status: String = listingBlock.selectFirst("div.message").text()
// Extract the price
val price: String = listingBlock.selectFirst("div.card-price").text()
// Extract other details like beds, baths, sqft, and lot size
val beds: String = listingBlock.selectFirst("li[data-testid=property-meta-beds]").text()
val baths: String = listingBlock.selectFirst("li[data-testid=property-meta-baths]").text()
val sqft: String = listingBlock.selectFirst("li[data-testid=property-meta-sqft]").text()
val lotSize: String = listingBlock.selectFirst("li[data-testid=property-meta-lot-size]").text()
// Extract the address
val address: String = listingBlock.selectFirst("div.card-address").text()
// Print the extracted information
println(s"Broker: $brokerName")
println(s"Status: $status")
println(s"Price: $price")
println(s"Beds: $beds")
println(s"Baths: $baths")
println(s"Sqft: $sqft")
println(s"Lot Size: $lotSize")
println(s"Address: $address")
println("-" * 50) // Separating listings
}
} catch {
case e: Exception =>
println(s"Failed to retrieve the page. Error: ${e.getMessage}")
}
}
}As you work on more scrapers, the process will become second-nature - connect, select elements, extract data. But it takes examples like this walkthrough to fully demystify what's happening behind the scenes.
Hopefully as a beginner you now feel equipped to start writing scrapers using Jsoup and CSS selectors!