Web scraping is the process of automatically collecting information from websites. This is done by writing code to connect to websites, request data, and parse through the HTML to extract the desired information.
In this article, we'll explore a full code example for scraping real estate listing data from Realtor.com using the Rust programming language.
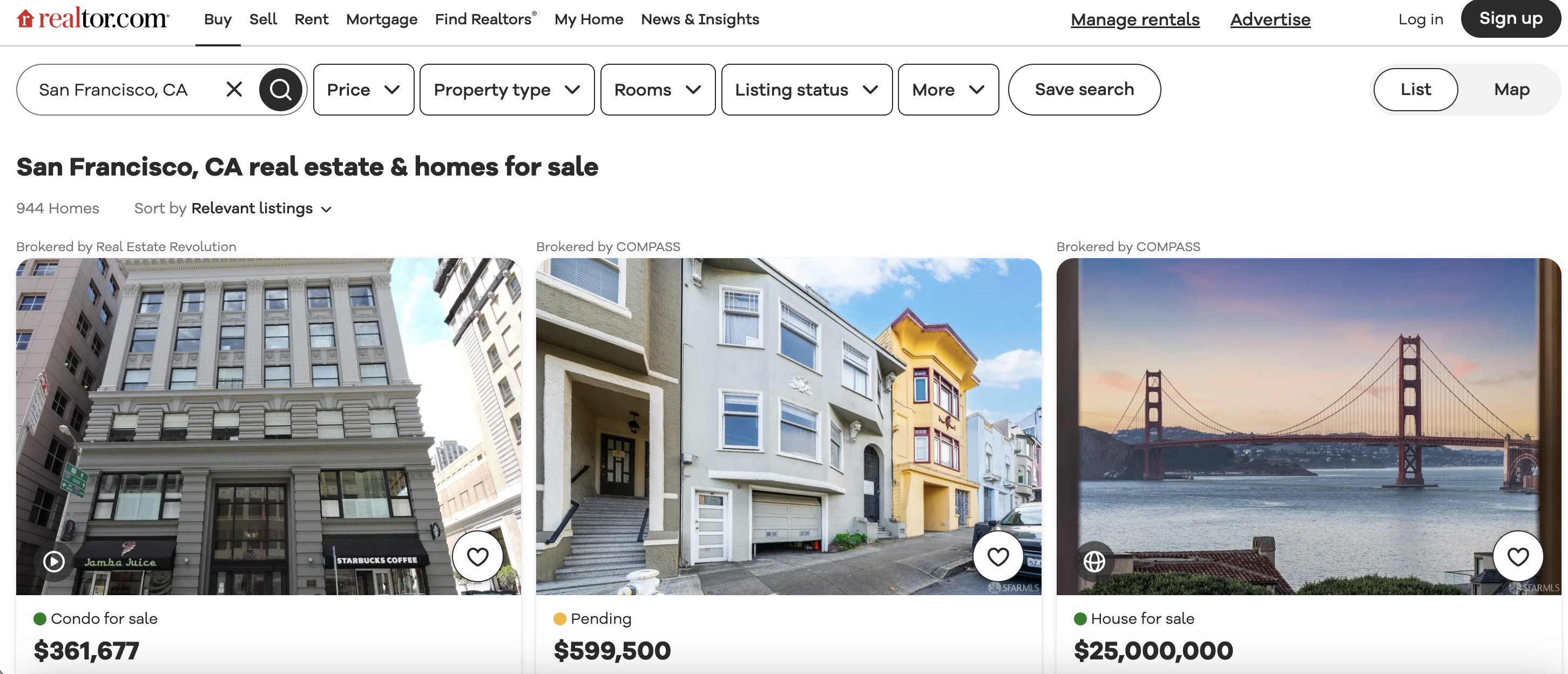
This is the listings page we are talking about…
Imports and Setup
Let's take a look at the initial imports and setup:
use reqwest;
use select::document::Document;
use select::node::Node;
use select::predicate::Attr;
use select::predicate::Class;
use select::predicate::Name;
This brings in the
There's also a
Make sure to have both
$ cargo add reqwest
$ cargo add select
Making the HTTP Request
Next we construct the URL to scrape - a Realtor.com listings page for San Francisco:
let url = "<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
And define a custom
let headers = reqwest::header::HeaderMap::new()
.insert(
reqwest::header::USER_AGENT,
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
);
We can then make the GET request with the
let response = reqwest::Client::new()
.get(url)
.headers(headers)
.send()
.await?;
This asynchronously sends the request and stores the response when it completes.
Checking the Response
It's good practice to verify that the request was successful before trying to parse the response content:
if response.status().is_success() {
// parsing logic here...
} else {
eprintln!("Failed to retrieve page. Status code: {:?}", response.status());
}
This checks for a 2XX status code before proceeding.
Parsing the Page with Selectors
Now that we have the page HTML content, we can use the
First we convert the response body to a parseable
let body = response.text().await?;
let document = Document::from(body);
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
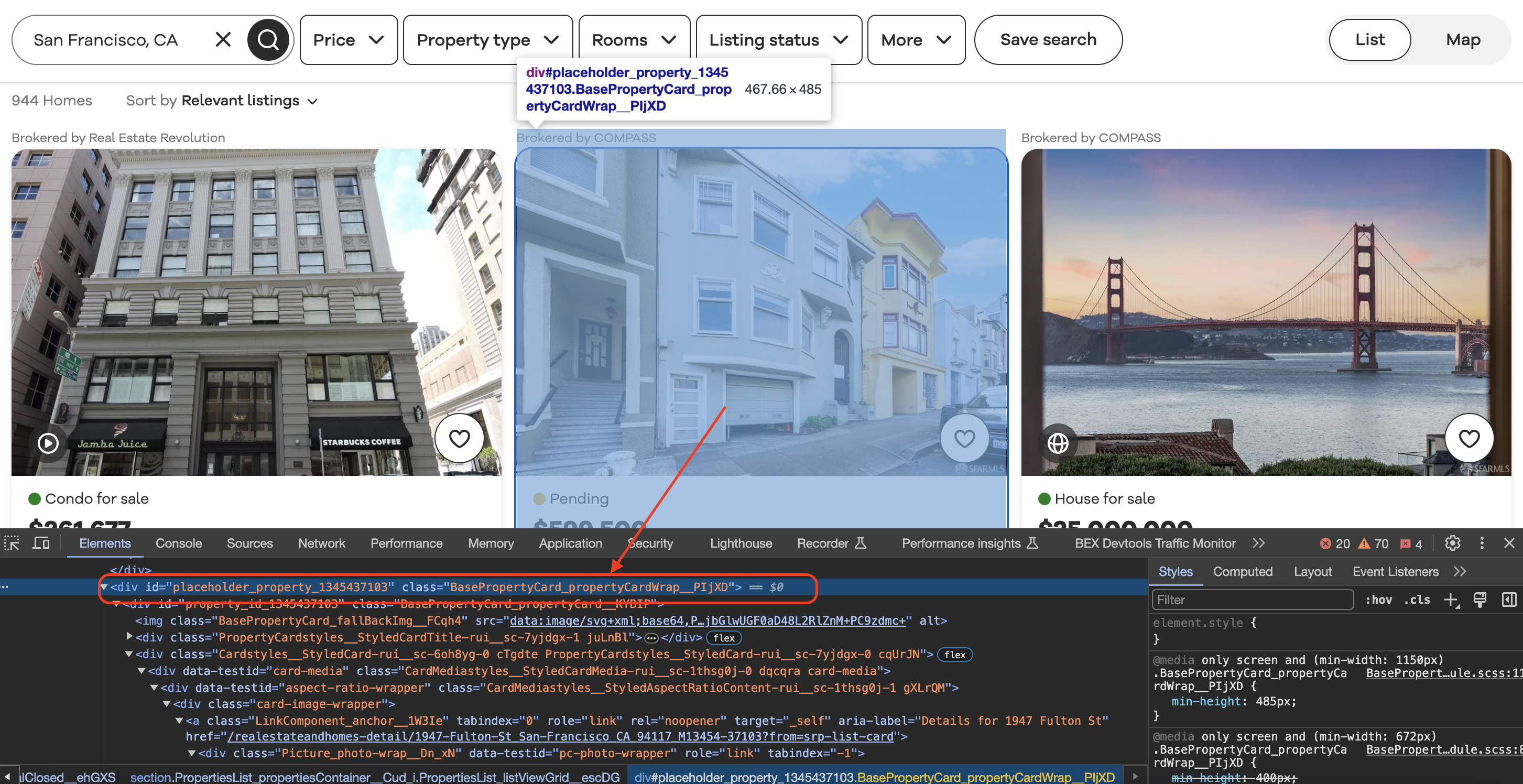
Then we find all listing blocks on the page using a CSS selector, looping through the results:
for listing_block in document.find(Class("BasePropertyCard_propertyCardWrap__J0xUj")) {
// Extract listing data...
}
Extracting Listing Details
Within the listing loop, we can use additional selectors to extract details from each block:
// Broker info
let broker_info = listing_block
.find(Class("BrokerTitle_brokerTitle__ZkbBW"))
.next()
.unwrap();
let broker_name = broker_info
.find(Class("BrokerTitle_titleText__20u1P"))
.next()
.unwrap()
.text();
// Status
let status = listing_block.find(Class("message"))
.next()
.unwrap()
.text();
// Price
let price = listing_block.find(Class("card-price"))
.next()
.unwrap()
.text();
And so on for other fields like beds, baths, square footage, etc. Each field has a CSS class or attribute selector that identifies the data to extract.
Some key points:
So these chained selector calls allow us to hone in on the exact data pieces we want.
While this example targets Realtor specifically, the concepts are the same across different sites. Identify selector patterns that uniquely identify the data fields, then extract the text values.
Printing the Results
Finally, we can print the listing details extracted from each block:
println!("Broker: {}", broker_name);
println!("Status: {}", status);
println!("Price: {}", price);
// ...
println!("-".repeat(50)); // separator
This outputs each listing's details, with a dashed line separator between listings.
The full code can be seen here:
use reqwest;
use select::document::Document;
use select::node::Node;
use select::predicate::Attr;
use select::predicate::Class;
use select::predicate::Name;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
// Define the URL of the Realtor.com search page
let url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
// Define a User-Agent header
let headers = reqwest::header::HeaderMap::new()
.insert(
reqwest::header::USER_AGENT,
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36",
);
// Send a GET request to the URL with the User-Agent header
let response = reqwest::Client::new()
.get(url)
.headers(headers)
.send()
.await?;
// Check if the request was successful (status code 200)
if response.status().is_success() {
// Parse the HTML content of the page using select
let body = response.text().await?;
let document = Document::from(body);
// Find all the listing blocks using the provided class name
for listing_block in document.find(Class("BasePropertyCard_propertyCardWrap__J0xUj")) {
// Extract the broker information
let broker_info = listing_block
.find(Class("BrokerTitle_brokerTitle__ZkbBW"))
.next()
.unwrap();
let broker_name = broker_info
.find(Class("BrokerTitle_titleText__20u1P"))
.next()
.unwrap()
.text();
// Extract the status (e.g., For Sale)
let status = listing_block.find(Class("message")).next().unwrap().text();
// Extract the price
let price = listing_block.find(Class("card-price")).next().unwrap().text();
// Extract other details like beds, baths, sqft, and lot size
let beds_element = listing_block
.find(Attr("data-testid", "property-meta-beds"))
.next();
let baths_element = listing_block
.find(Attr("data-testid", "property-meta-baths"))
.next();
let sqft_element = listing_block
.find(Attr("data-testid", "property-meta-sqft"))
.next();
let lot_size_element = listing_block
.find(Attr("data-testid", "property-meta-lot-size"))
.next();
// Check if the elements exist before extracting their text
let beds = beds_element.map(|e| e.text()).unwrap_or("N/A".to_string());
let baths = baths_element.map(|e| e.text()).unwrap_or("N/A".to_string());
let sqft = sqft_element.map(|e| e.text()).unwrap_or("N/A".to_string());
let lot_size = lot_size_element.map(|e| e.text()).unwrap_or("N/A".to_string());
// Extract the address
let address = listing_block.find(Class("card-address")).next().unwrap().text();
// Print the extracted information
println!("Broker: {}", broker_name);
println!("Status: {}", status);
println!("Price: {}", price);
println!("Beds: {}", beds);
println!("Baths: {}", baths);
println!("Sqft: {}", sqft);
println!("Lot Size: {}", lot_size);
println!("Address: {}", address);
println!("-".repeat(50)); // Separating listings
}
} else {
eprintln!("Failed to retrieve the page. Status code: {:?}", response.status());
}
Ok(())
}This implemented a full web scraper to extract Realtor listings data into structured fields that could be saved to a database, output to a CSV, or used in other programs.