Web scraping refers to automatically extracting data from websites. It can be useful for gathering large datasets for analysis or automation purposes. In this article, we'll go through code to scrape real estate listing data from Realtor.com using the Objective-C language.
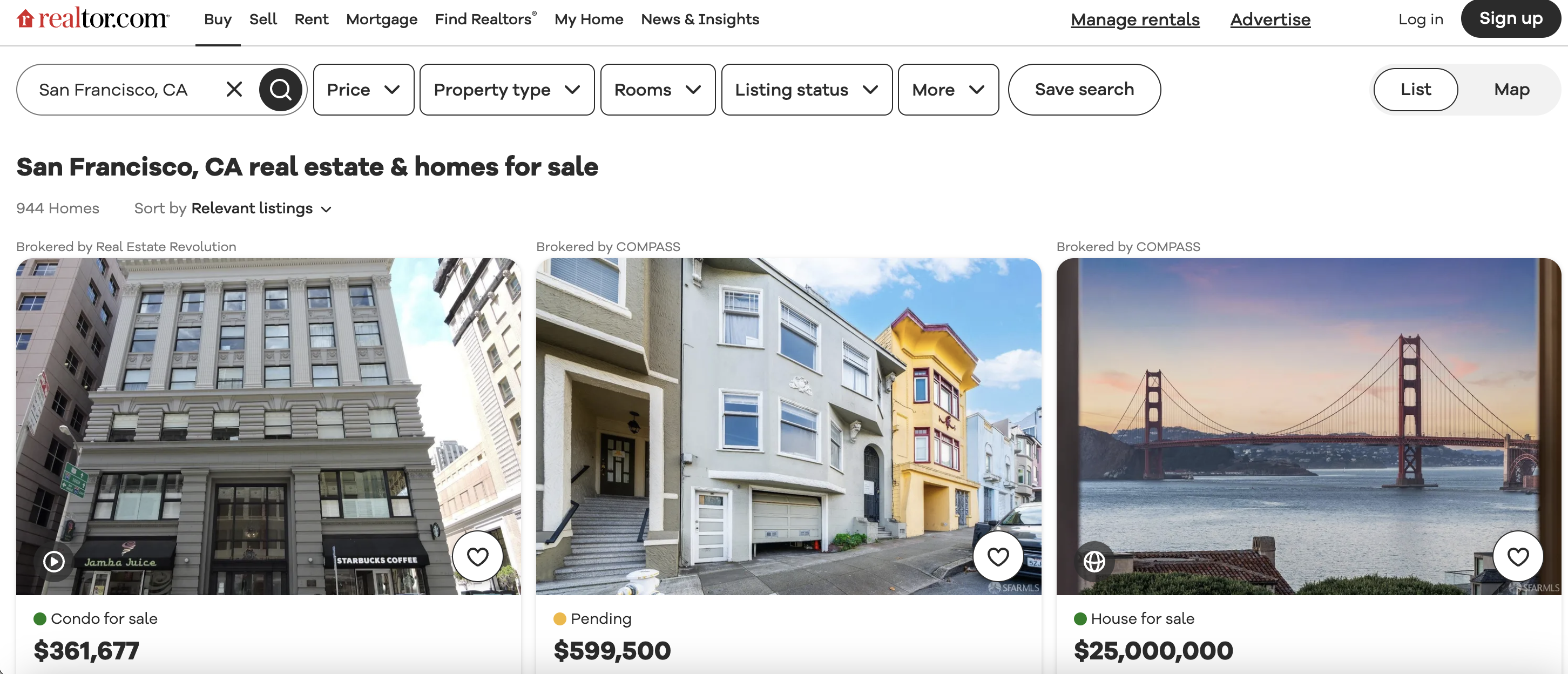
This is the listings page we are talking about…
Overview of the Scraper Code
Below is the full code we'll be walking through. Don't worry about understanding it yet - we'll explore section-by-section next.
[FULL CODE PROVIDED]
We won't dive into the ethics of web scraping here. Instead, our goal is to practically understand how each part of this scraper works so you can adapt the concepts for your own projects.
There are a few key components:
- Defining models to store the scraped data
- Making the HTTP request to download the page content
- Parsing the HTML content
- Extracting data using selectors
Let's look at each section.
Defining Models to Store Data
The
Later in our parser code, we'll instantiate
The
Making the HTTP Request
This code forms the HTTP request to download the Realtor.com listing page:
// Define URL
NSString *urlString = @"<https://www.realtor.com/realestateandhomes-search/San-Francisco_CA>";
NSURL *url = [NSURL URLWithString:urlString];
// Set custom user agent header
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
};
// Initialize URL session
NSURLSessionConfiguration *config = [NSURLSessionConfiguration defaultSessionConfiguration];
[config setHTTPAdditionalHeaders:headers];
NSURLSession *session = [NSURLSession sessionWithConfiguration:config];
// Create data task
NSURLSessionDataTask *dataTask = [session dataTaskWithURL:url
completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
// Check for errors
// Parse data
}];
// Execute request
[dataTask resume];
Key aspects:
This is a common pattern for initiating web scrapes. Let's move on to parsing the HTML.
Parsing the Page Content with NSXMLParser
With the raw HTML content downloaded, we can use NSXMLParser to analyze it:
// Initialize parser
NSXMLParser *parser = [[NSXMLParser alloc] initWithData:data];
// Our delegate will handle parse events
ParserDelegate *parserDelegate = [[ParserDelegate alloc] init];
[parser setDelegate:parserDelegate];
// Start parsing
[parser parse];
NSXMLParser offers a SAX-style API - the parser progressively walks through the HTML and fires events as it encounters tags and text content.
Our
Extracting Listing Data Field-by-Field
Now we arrive at the most complex part - selectively pulling relevant data from the raw HTML dump.
Our strategy is to identify patterns in the HTML that surround each data field we want. When we match a pattern, we can extract the nearby text and assign it to a listing attribute.
For example, the broker name always appears after "Broker: " in the HTML:
<div>Broker: Realty360 Premier Properties</div>
By matching this pattern, we can extract "Realty360 Premier Properties".
Let's walk through each data field extraction one-by-one.
Initializing ListingData Objects
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…

When the parser first encounters a listing card div, we initialize a new
if ([elementName isEqualToString:@"div"] &&
[attributeDict[@"class"] isEqualToString:@"BasePropertyCard_propertyCardWrap__J0xUj"]) {
self.currentListingData = [[ListingData alloc] init];
}
This ensures each listing gets its own model object.
Extracting Broker Name
Here is how the broker name field is parsed:
if ([elementName isEqualToString:@"div"] &&
[self.currentElementValue containsString:@"Broker: "]) {
self.currentListingData.brokerName =
[self.currentElementValue stringByReplacingOccurrencesOfString:@"Broker: "
withString:@""];
}
We check if the closed tag is a div AND it contains the text "Broker: ". When a match occurs, we strip away the label and store the raw broker name into the current ListingData object.
And so on for each other attribute:
Extracting Listing Status
Do the same pattern match for the status label:
} else if ([elementName isEqualToString:@"div"] &&
[self.currentElementValue containsString:@"Status: "]) {
self.currentListingData.status =
[self.currentElementValue stringByReplacingOccurrencesOfString:@"Status: "
withString:@""];
}
Extracting Price
You get the idea now - find the targeted element + label pattern and selectively save the text:
} else if ([elementName isEqualToString:@"div"] &&
[self.currentElementValue containsString:@"Price: "]) {
self.currentListingData.price =
[self.currentElementValue stringByReplacingOccurrencesOfString:@"Price: "
withString:@""];
}
And so on for beds, baths, address, etc...
Once all attributes are populated, we add the
[self.listingDataArray addObject:self.currentListingData];
Later, we can iterate through this array to print or process all listings.
And that covers the key concepts of how this scraper selectively extracts fields!
Full Code
Now you've seen how web scraping can automate data extraction from sites like Realtor.com.
Here is the complete runnable code sample again for reference:
#import <Foundation/Foundation.h>
@interface ListingData : NSObject
@property (nonatomic, strong) NSString *brokerName;
@property (nonatomic, strong) NSString *status;
@property (nonatomic, strong) NSString *price;
@property (nonatomic, strong) NSString *beds;
@property (nonatomic, strong) NSString *baths;
@property (nonatomic, strong) NSString *sqft;
@property (nonatomic, strong) NSString *lotSize;
@property (nonatomic, strong) NSString *address;
@end
@implementation ListingData
@end
@interface ParserDelegate : NSObject <NSXMLParserDelegate>
@property (nonatomic, strong) NSMutableArray<ListingData *> *listingDataArray;
@property (nonatomic, strong) NSMutableString *currentElementValue;
@property (nonatomic, strong) ListingData *currentListingData;
@end
@implementation ParserDelegate
- (void)parserDidStartDocument:(NSXMLParser *)parser {
self.listingDataArray = [NSMutableArray array];
}
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName attributes:(NSDictionary<NSString *, NSString *> *)attributeDict {
if ([elementName isEqualToString:@"div"] && [attributeDict[@"class"] isEqualToString:@"BasePropertyCard_propertyCardWrap__J0xUj"]) {
self.currentListingData = [[ListingData alloc] init];
}
if (self.currentListingData) {
self.currentElementValue = [NSMutableString string];
}
}
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string {
[self.currentElementValue appendString:string];
}
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(NSString *)namespaceURI qualifiedName:(NSString *)qName {
if ([elementName isEqualToString:@"div"] && [self.currentElementValue containsString:@"Broker: "]) {
self.currentListingData.brokerName = [self.currentElementValue stringByReplacingOccurrencesOfString:@"Broker: " withString:@""];
} else if ([elementName isEqualToString:@"div"] && [self.currentElementValue containsString:@"Status: "]) {
self.currentListingData.status = [self.currentElementValue stringByReplacingOccurrencesOfString:@"Status: " withString:@""];
} else if ([elementName isEqualToString:@"div"] && [self.currentElementValue containsString:@"Price: "]) {
self.currentListingData.price = [self.currentElementValue stringByReplacingOccurrencesOfString:@"Price: " withString:@""];
} else if ([elementName isEqualToString:@"li"] && [self.currentElementValue containsString:@"Beds"]) {
self.currentListingData.beds = self.currentElementValue;
} else if ([elementName isEqualToString:@"li"] && [self.currentElementValue containsString:@"Baths"]) {
self.currentListingData.baths = self.currentElementValue;
} else if ([elementName isEqualToString:@"li"] && [self.currentElementValue containsString:@"Sqft"]) {
self.currentListingData.sqft = self.currentElementValue;
} else if ([elementName isEqualToString:@"li"] && [self.currentElementValue containsString:@"Lot Size"]) {
self.currentListingData.lotSize = self.currentElementValue;
} else if ([elementName isEqualToString:@"div"] && [self.currentElementValue containsString:@"Address: "]) {
self.currentListingData.address = [self.currentElementValue stringByReplacingOccurrencesOfString:@"Address: " withString:@""];
}
if ([elementName isEqualToString:@"div"] && self.currentListingData) {
[self.listingDataArray addObject:self.currentListingData];
self.currentListingData = nil;
}
self.currentElementValue = nil;
}
- (void)parser:(NSXMLParser *)parser parseErrorOccurred:(NSError *)parseError {
NSLog(@"Parsing error: %@", parseError.localizedDescription);
}
- (void)parserDidEndDocument:(NSXMLParser *)parser {
// Print the extracted information
for (ListingData *listingData in self.listingDataArray) {
NSLog(@"Broker: %@", listingData.brokerName);
NSLog(@"Status: %@", listingData.status);
NSLog(@"Price: %@", listingData.price);
NSLog(@"Beds: %@", listingData.beds);
NSLog(@"Baths: %@", listingData.baths);
NSLog(@"Sqft: %@", listingData.sqft);
NSLog(@"Lot Size: %@", listingData.lotSize);
NSLog(@"Address: %@", listingData.address);
NSLog(@"----------------------------------------------------");
}
}
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Define the URL of the Realtor.com search page
NSString *urlString = @"https://www.realtor.com/realestateandhomes-search/San-Francisco_CA";
NSURL *url = [NSURL URLWithString:urlString];
// Define a User-Agent header
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
};
// Initialize NSURLSession configuration
NSURLSessionConfiguration *config = [NSURLSessionConfiguration defaultSessionConfiguration];
[config setHTTPAdditionalHeaders:headers];
// Initialize NSURLSession with the configuration
NSURLSession *session = [NSURLSession sessionWithConfiguration:config];
// Create a data task to send a GET request to the URL with the User-Agent header
NSURLSessionDataTask *dataTask = [session dataTaskWithURL:url completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
if (error) {
NSLog(@"Failed to retrieve the page. Error: %@", error);
return;
}
// Check if the response was successful (HTTP status code 200)
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode == 200) {
// Parse the HTML content of the page using NSXMLParser
NSXMLParser *parser = [[NSXMLParser alloc] initWithData:data];
ParserDelegate *parserDelegate = [[ParserDelegate alloc] init];
[parser setDelegate:parserDelegate];
[parser parse];
} else {
NSLog(@"Failed to retrieve the page. Status code: %ld", (long)httpResponse.statusCode);
}
}];
// Start the data task
[dataTask resume];
// Run the run loop to keep the program alive while the data task is executing
[[NSRunLoop currentRunLoop] run];
}
return 0;
}The key libraries needed are Foundation and UIKit. Make sure to include these frameworks if reusing or adapting this code.