Web scraping can be a valuable skill for extracting publicly available data from websites. This article will explain how to use Ruby and the Nokogiri and HTTParty gems to scrape real estate listing data from Realtor.com.
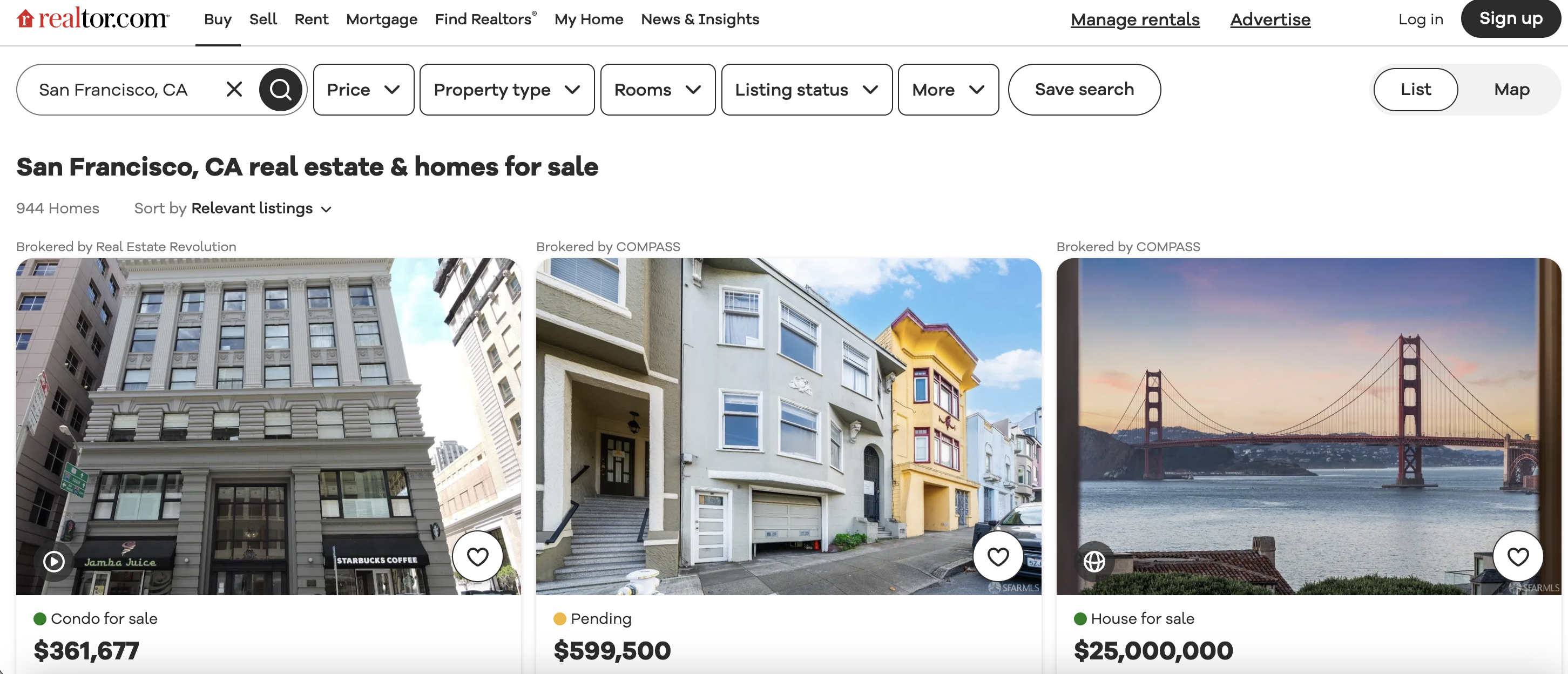
This is the listings page we are talking about…
Installation
Before running the code, you'll need to install Ruby, Nokogiri, and HTTParty:
# Install Ruby
$ sudo apt install ruby-full
# Install bundler
$ gem install bundler
# Install Nokogiri
$ gem install nokogiri
# Install HTTParty
$ gem install httparty
When installed correctly, you should see version information when checking:
$ ruby -v
ruby 2.7.1p83
$ gem list | grep nokogiri
nokogiri (1.13.10)
$ gem list | grep httparty
httparty (0.20.0)
Now we're ready to run the scraper!
Understanding the Script Flow
Let's break down what the script is doing at a high level:
- Require the
nokogiri andhttparty libraries we installed - Define the target URL to scrape (
https://www.realtor.com/... ) - Set a user agent header to look like a real web browser
- Make an HTTP GET request to fetch the page content
- Check if the request succeeded (status code 200)
- If successful, parse the HTML content using Nokogiri
- Find all listing blocks by their CSS class name
- Loop through each listing block
- Extract data like price, beds, broker name etc. by CSS selector
- Print out the extracted data
The key thing to understand is that first we fetch the page HTML, then we use CSS selectors to pinpoint specific data elements in that HTML and extract their text.
Next let's see exactly how the data extraction works.
Extracting Data from Listing Blocks
Inspecting the element
When we inspect element in Chrome we can see that each of the listing blocks is wrapped in a div with a class value as shown below…
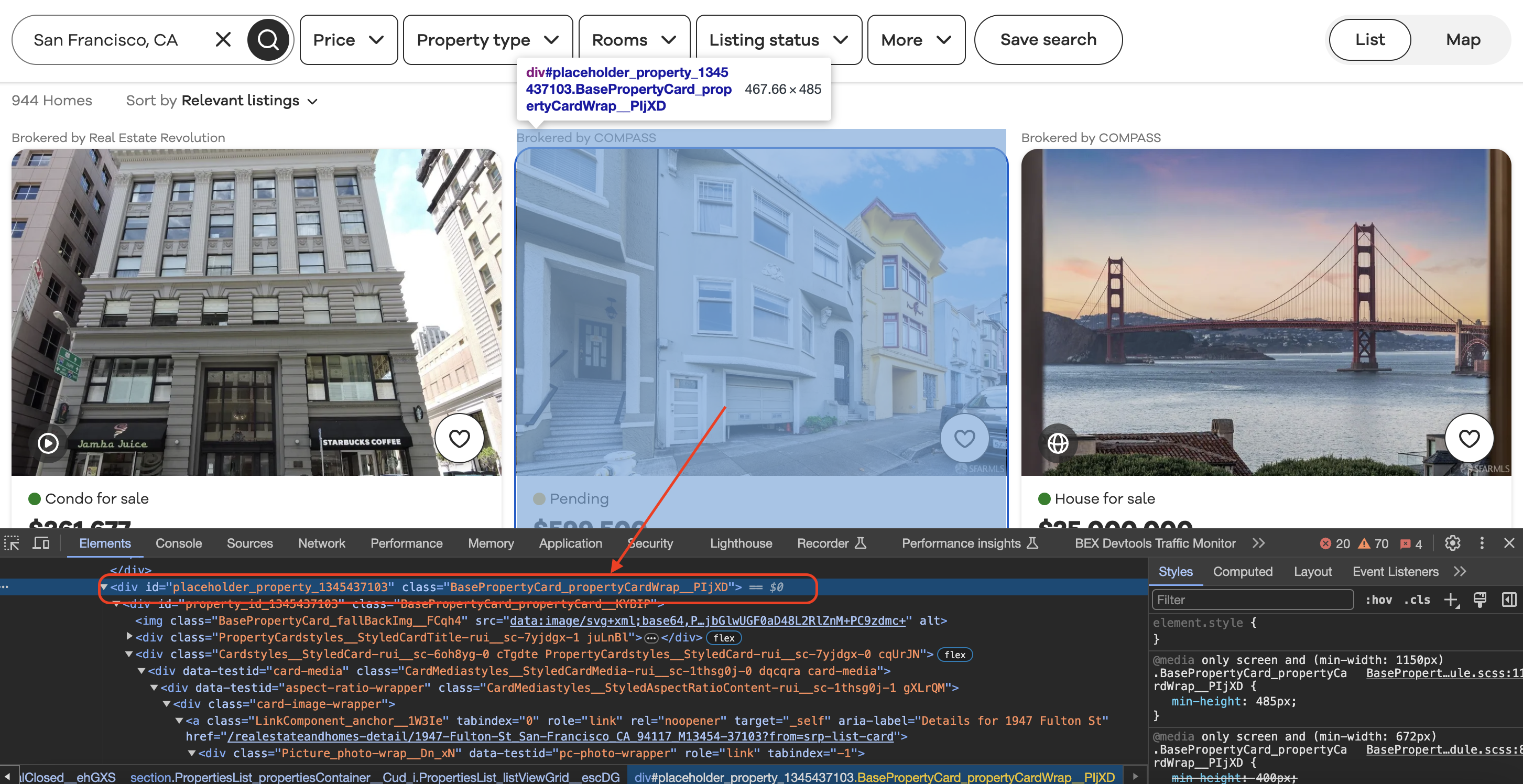
The most complex part of this scraper is extracting multiple data fields from each listing block.
Here is the loop that processes each listing:
listing_blocks.each do |listing_block|
# Extract the broker information
broker_info = listing_block.css(".BrokerTitle_brokerTitle__ZkbBW")
broker_name = broker_info.css(".BrokerTitle_titleText__20u1P").text.strip()
# Extract price
price = listing_block.css(".card-price").text.strip()
# Extract beds, baths
beds_element = listing_block.css("[data-testid='property-meta-beds']")
baths_element = listing_block.css("[data-testid='property-meta-baths']")
# Extract address
address = listing_block.css(".card-address").text.strip()
end
Let's look at how the broker name field is extracted:
broker_info = listing_block.css(".BrokerTitle_brokerTitle__ZkbBW")
broker_name = broker_info.css(".BrokerTitle_titleText__20u1P").text.strip()
First, we use the CSS selector
The price extraction follows the same approach:
price = listing_block.css(".card-price").text.strip()
We use the
One tricky part is handling fields like beds and baths that may be missing:
beds_element = listing_block.css("[data-testid='property-meta-beds']")
beds = beds_element.text.strip() unless beds_element.empty?
First we try to select the beds element. Then we check if that returned no results by calling
Full Code Example
Below is the full runnable script to scrape Realtor listings:
require 'nokogiri'
require 'httparty'
# Define the URL of the Realtor.com search page
url = "https://www.realtor.com/realestateandhomes-search/San-Francisco_CA"
# Define a User-Agent header
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" # Replace with your User-Agent string
}
# Send a GET request to the URL with the User-Agent header
response = HTTParty.get(url, headers: headers)
# Check if the request was successful (status code 200)
if response.code == 200
# Parse the HTML content of the page using Nokogiri
doc = Nokogiri::HTML(response.body)
# Find all the listing blocks using the provided class name
listing_blocks = doc.css(".BasePropertyCard_propertyCardWrap__J0xUj")
# Loop through each listing block and extract information
listing_blocks.each do |listing_block|
# Extract the broker information
broker_info = listing_block.css(".BrokerTitle_brokerTitle__ZkbBW")
broker_name = broker_info.css(".BrokerTitle_titleText__20u1P").text.strip()
# Extract the status (e.g., For Sale)
status = listing_block.css(".message").text.strip()
# Extract the price
price = listing_block.css(".card-price").text.strip()
# Extract other details like beds, baths, sqft, and lot size
beds_element = listing_block.css("[data-testid='property-meta-beds']")
baths_element = listing_block.css("[data-testid='property-meta-baths']")
sqft_element = listing_block.css("[data-testid='property-meta-sqft']")
lot_size_element = listing_block.css("[data-testid='property-meta-lot-size']")
# Check if the elements exist before extracting their text
beds = beds_element.text.strip() unless beds_element.empty?
baths = baths_element.text.strip() unless baths_element.empty?
sqft = sqft_element.text.strip() unless sqft_element.empty?
lot_size = lot_size_element.text.strip() unless lot_size_element.empty?
# Extract the address
address = listing_block.css(".card-address").text.strip()
# Print the extracted information
puts "Broker: #{broker_name}"
puts "Status: #{status}"
puts "Price: #{price}"
puts "Beds: #{beds || 'N/A'}"
puts "Baths: #{baths || 'N/A'}"
puts "Sqft: #{sqft || 'N/A'}"
puts "Lot Size: #{lot_size || 'N/A'}"
puts "Address: #{address}"
puts "-" * 50 # Separating listings
end
else
puts "Failed to retrieve the page. Status code: #{response.code}"
endThe key things to remember are:
With some debugging and tweaking, you can adapt this approach to build scrapers extracting all sorts of data!