Web scraping is the technique of automatically extracting data from websites through code. In this article, we will go through a C++ program that scrapes post data from Reddit, a popular social news aggregation site.
here is the page we are talking about
This code sends a request to Reddit, downloads the HTML content, saves it to a file, parses the HTML to find relevant blocks of code, and extracts information like title, author, scores for each Reddit post.
Overview of Code
At a high level, the code does the following:
- Initializes cURL and sets options to send GET request to a Reddit URL
- Adds a user agent header to mimic a browser
- Saves returned HTML content to a string
- Writes HTML content to a file
- Parses HTML and finds all div blocks containing posts
- Extracts post data like title, author, score for each block
- Prints extracted information
Prerequisites and Setup
To run this C++ program, you need:
- C++ compiler like g++
- cURL library installed
To install cURL on Linux:
sudo apt install libcurl4-openssl-dev
On Mac:
brew install curl
On Windows, download binaries from curl.se/windows/
To build the program:
g++ program.cpp -o program -lcurl
This will compile the code and link the cURL library.
Let's now understand the code section-by-section.
Sending GET Request
First we construct a URL pointing to reddit.com:
const std::string reddit_url = "<https://www.reddit.com>";
We need to spoof a browser's user agent, so the server thinks the request is coming from a real browser:
struct curl_slist *headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36");
This adds a header that mimics Chrome browser on Windows. We initialize a curl handle:
CURL* curl = curl_easy_init();
And set options on it - set URL to fetch:
curl_easy_setopt(curl, CURLOPT_URL, reddit_url.c_str());
Set the user agent header:
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
Finally, make the request with
CURLcode res = curl_easy_perform(curl);
Saving HTML Response
The HTML text returned is saved into a string variable:
std::string html_content;
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html_content);
We then write this content into a file called reddit_page.html:
const std::string filename = "reddit_page.html";
std::ofstream file(filename);
file << html_content;
file.close();
Parsing Content and Extracting Data
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
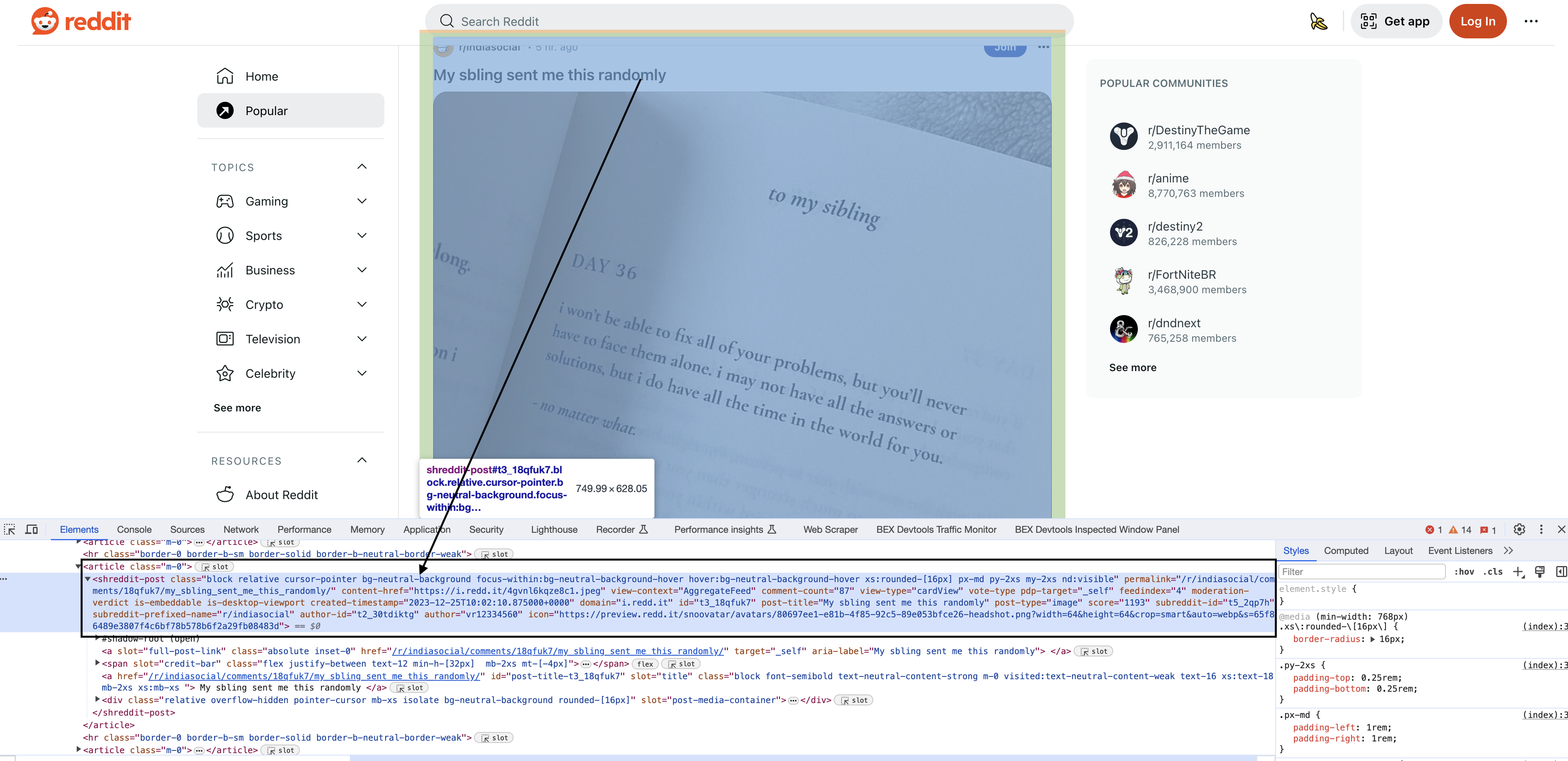
To extract information from HTML, we need to parse it programmatically. This can be done using DOM parsers like Xerces or Pugixml.
We locate div blocks with certain CSS classes that contain posts:
const std::vector<Node> blocks = FindBlocks("shreddit-post", "block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px\\] p-md my-2xs nd:visible");
The classes here match styling used on Reddit for post blocks. It is important not to change these string literals.
We iterate through each block:
for(const auto& block : blocks) {
}
And extract various attributes from it:
std::string permalink = block.GetAttribute("permalink");
std::string content_href = block.GetAttribute("content-href");
std::string comment_count = block.GetAttribute("comment-count");
The permalink points to the post URL, content_href links to the content, and comment_count shows the number of comments.
To get the title text, we find the title element and get inner text:
const Node title_node = block.FindFirst("div", {{"slot", "title"}});
std::string post_title = title_node.GetText();
Similarly, author name, score are also attributes on the block:
std::string author = block.GetAttribute("author");
std::string score = block.GetAttribute("score");
The key things to note are:
- Preserving the string literals used in selectors
- Extracting data from attributes and text appropriately
Conclusion
In this article, we went through a C++ program to scrape Reddit posts. We looked at the overall flow of sending a browser-spoofed request, parsing returned HTML content, and extracting post information through DOM traversal.
Special attention was paid to the selector syntax and data extraction logic, which tend to be confusing areas for beginners.
The full runnable code is provided below for reference.
#include <iostream>
#include <curl/curl.h>
#include <string>
// Define the Reddit URL you want to download
const std::string reddit_url = "https://www.reddit.com";
// Define a User-Agent header
struct curl_slist *headers = NULL;
headers = curl_slist_append(headers, "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36");
// Send a GET request to the URL with the User-Agent header
CURL* curl = curl_easy_init();
if(curl) {
curl_easy_setopt(curl, CURLOPT_URL, reddit_url.c_str());
curl_easy_setopt(curl, CURLOPT_HTTPHEADER, headers);
// Get the HTML content
std::string html_content;
curl_easy_setopt(curl, CURLOPT_WRITEFUNCTION, write_data);
curl_easy_setopt(curl, CURLOPT_WRITEDATA, &html_content);
CURLcode res = curl_easy_perform(curl);
if(res == CURLE_OK) {
// Specify filename to save HTML content
const std::string filename = "reddit_page.html";
// Save HTML content to file
std::ofstream file(filename);
file << html_content;
file.close();
std::cout << "Reddit page saved to " << filename << "\n";
} else {
std::cout << "Failed to download Reddit page" << "\n";
}
// Clean up
curl_easy_cleanup(curl);
curl_slist_free_all(headers);
}
// Parse HTML content
// Use html parser like Xerces or Pugixml
// Find all blocks with the specified tag and class
const std::vector<Node> blocks = FindBlocks("shreddit-post", "block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px] p-md my-2xs nd:visible");
// Iterate through the blocks and extract information
for(const auto& block : blocks) {
std::string permalink = block.GetAttribute("permalink");
std::string content_href = block.GetAttribute("content-href");
std::string comment_count = block.GetAttribute("comment-count");
const Node title_node = block.FindFirst("div", {{"slot", "title"}});
std::string post_title = title_node.GetText();
std::string author = block.GetAttribute("author");
std::string score = block.GetAttribute("score");
std::cout << "Permalink: " << permalink << "\n";
std::cout << "Content Href: " << content_href << "\n";
std::cout << "Comment Count: " << comment_count << "\n";
std::cout << "Post Title: " << post_title << "\n";
std::cout << "Author: " << author << "\n";
std::cout << "Score: " << score << "\n\n";
}