Web scraping allows you to extract data from websites programmatically. In this comprehensive tutorial, we'll walk through Elixir code to scrape post information from Reddit.
here is the page we are talking about
We'll cover:
By the end, you'll understand how to build your own Reddit scraper in Elixir.
Install Dependencies
We'll use two packages:
HTTPoison - Makes HTTP requests
Floki - HTML parsing
Install Elixir if needed, then run:
mix escript.install hex httpoison
mix escript.install hex floki
This downloads the libraries. Let's look at the code.
Make the HTTP Request
First we define a module and variables:
defmodule RedditScraper do
@reddit_url "<https://www.reddit.com>"
@user_agent "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
end
The
Next we make the HTTP request:
def scrape do
headers = [{"User-Agent", @user_agent}]
case HTTPoison.get(@reddit_url, headers) do
{:ok, %{status_code: 200, body: html_content}} ->
# Request succeeded
{:ok, %{status_code: status_code}} ->
# Request failed
{:error, reason} ->
# Request error
end
end
We pass headers to disguise the scraping bot as a browser. The function returns the HTML body on success which we'll parse next.
Parse the HTML
We use the Floki library to parse:
defp parse_html(html_content) do
doc = Floki.parse_document(html_content)
end
This converts the HTML into a nested Elixir map we can query just like the original DOM!
Use CSS Selectors in Floki
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
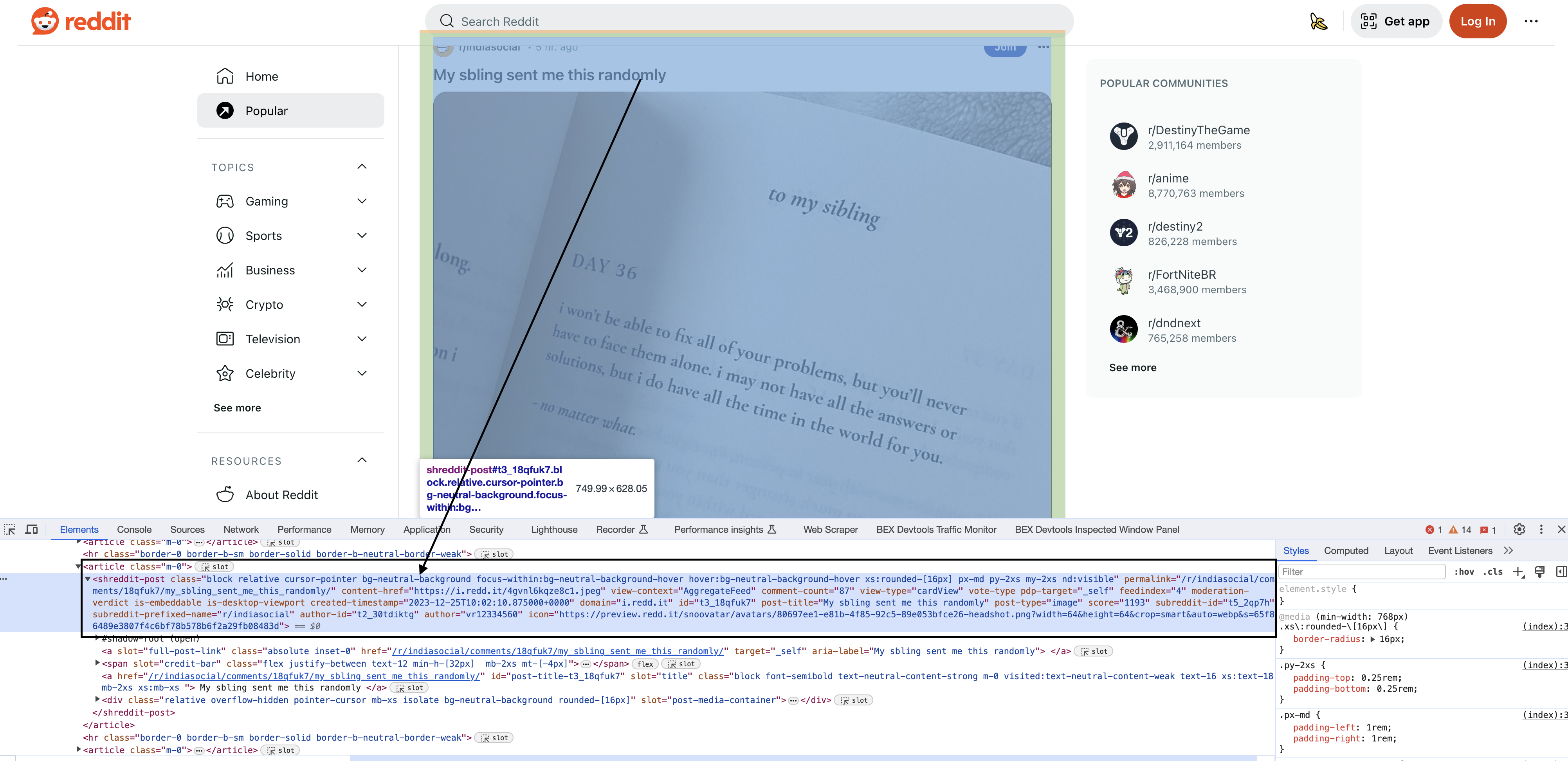
Floki finds DOM elements using CSS selectors. Let's break down the key ones used:
blocks = Floki.find(doc, "shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
This mouthful targets Reddit's structured post blocks. Let's unpack it:
"shreddit-post" - Targets elements with this specific class
.block - Chain multiple classes with dots
.relative - Matches any element with both these classes
focus-within:bg-neutral-background-hover - Special hover syntax
This specifically locates post block containers. We'll extract data from them next.
Extract Post Data
We loop through each block:
Enum.each(blocks, fn block ->
permalink = Floki.attribute(block, "permalink")
post_title = Floki.text(block, "div[slot='title']") |> String.trim()
author = Floki.attribute(block, "author")
end)
Floki.attribute - Gets attribute values like "permalink"
Floki.text - Extracts textual content
String.trim - Cleans whitespace
We grab key data points into variables, eventually printing each post's info.
The complete code follows. Study the CSS selectors to customize your own scraper!
Full Code
defmodule RedditScraper do
@reddit_url "https://www.reddit.com"
@user_agent "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
def scrape do
headers = [{"User-Agent", @user_agent}]
# Send a GET request to the Reddit URL
case HTTPoison.get(@reddit_url, headers) do
{:ok, %{status_code: 200, body: html_content}} ->
# Save the HTML content to a file
File.write!("reddit_page.html", html_content)
IO.puts("Reddit page saved to reddit_page.html")
# Parse the HTML content
parse_html(html_content)
{:ok, %{status_code: status_code}} ->
IO.puts("Failed to download Reddit page (status code #{status_code})")
{:error, reason} ->
IO.puts("Failed to make the request: #{inspect(reason)}")
end
end
defp parse_html(html_content) do
# Parse the HTML content using Floki
doc = Floki.parse_document(html_content)
# Find all blocks with the specified tag and class
blocks = Floki.find(doc, "shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible")
# Iterate through the blocks and extract information from each one
Enum.each(blocks, fn block ->
permalink = Floki.attribute(block, "permalink")
content_href = Floki.attribute(block, "content-href")
comment_count = Floki.attribute(block, "comment-count")
post_title = Floki.text(block, "div[slot='title']") |> String.trim()
author = Floki.attribute(block, "author")
score = Floki.attribute(block, "score")
# Print the extracted information for each block
IO.puts("Permalink: #{permalink}")
IO.puts("Content Href: #{content_href}")
IO.puts("Comment Count: #{comment_count}")
IO.puts("Post Title: #{post_title}")
IO.puts("Author: #{author}")
IO.puts("Score: #{score}")
IO.puts("\n")
end)
end
end
RedditScraper.scrape()