In this guide, we'll walk you through a script for scraping image URLs from a Reddit page using Node.js. The script downloads the Reddit page content by sending an HTTP request, saves the HTML locally, and then employs the jsdom module to parse the page and extract information.
Our focus will be on identifying and extracting the post blocks that contain images, along with key data such as image URLs and metadata.
here is the page we are talking about
Installing the Required Modules
We'll use the following Node.js modules:
axios - for sending HTTP requests
npm install axios
fs - for saving files
npm install fs
jsdom - for parsing HTML and DOM manipulation
npm install jsdom
Walkthrough of the Code
First we require the installed modules:
const axios = require('axios');
const fs = require('fs');
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
Next we define the Reddit URL we want to scrape and a User-Agent header:
// Define the Reddit URL you want to download
const reddit_url = "<https://www.reddit.com>";
// Define a User-Agent header
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
};
The User-Agent header identifies us to the web server, avoiding blocks as an anonymous scraper.
We send a GET request using axios to download the page content:
// Send a GET request to the URL with the User-Agent header
axios.get(reddit_url, { headers })
.then(async (response) => {
// Page download code here
})
.catch((error) => {
console.error(error);
});
Inside the .then(), we check if the request succeeded with a 200 status, then save the HTML content to a local file:
if (response.status === 200) {
// Get the HTML content of the page
const html_content = response.data;
// Specify the filename to save the HTML content
const filename = "reddit_page.html";
// Save the HTML content to a file
fs.writeFileSync(filename, html_content, 'utf-8');
console.log(`Reddit page saved to ${filename}`);
} else {
console.log(`Failed to download Reddit page (status code ${response.status})`);
}
Now we have the page content saved locally as html_content. We use JSDOM to parse it into a manipulatable DOM:
// Parse the HTML content using JSDOM
const dom = new JSDOM(html_content);
This dom object contains the entire structured document.
Identifying and Extracting the Image Blocks
Now for the most crucial part - finding and looping through the post blocks to extract images and metadata.
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
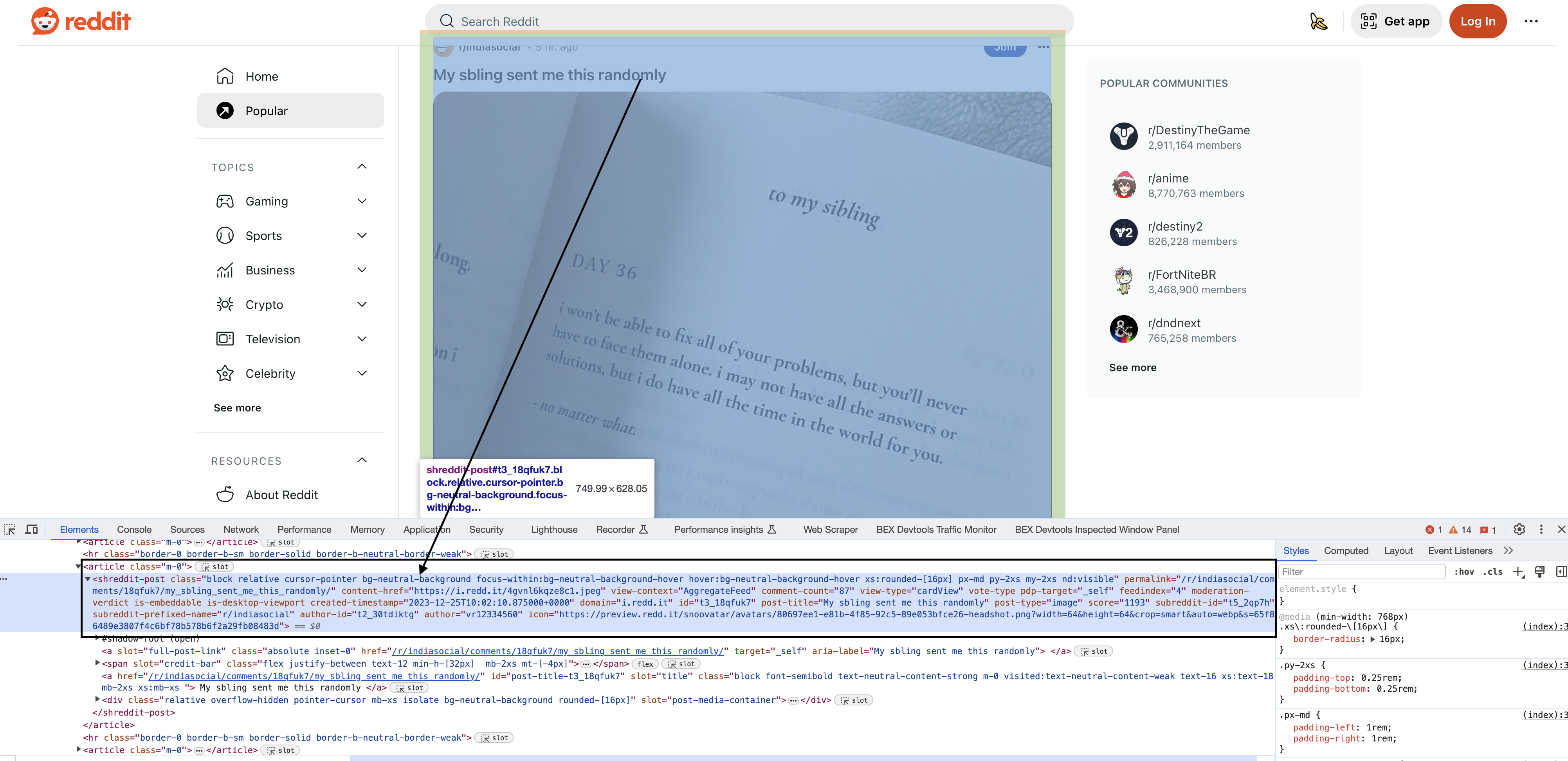
We use document.querySelectorAll() to find all post blocks matching the selector:
// Find all blocks with the specified tag and class
const blocks = dom.window.document.querySelectorAll('shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible');
This gives us all the post blocks in an array-like object called
We loop through them with forEach:
// Iterate through the blocks and extract information from each one
blocks.forEach((block) => {
// Extract data from each block
});
Inside the loop, we use block.getAttribute() to extract all the data we need:
const permalink = block.getAttribute('permalink');
const content_href = block.getAttribute('content-href');
const comment_count = block.getAttribute('comment-count');
const post_title = block.querySelector('div[slot="title"]').textContent.trim();
const author = block.getAttribute('author');
const score = block.getAttribute('score');
And we print out all the extracted data:
console.log(`Permalink: ${permalink}`);
// Other prints
This gives us everything we need! We loop through all shreddit-post blocks, extract the image URLs and other metadata, then print it.
The full code is below to scrape a Reddit page. To adapt it, update the reddit_url variable and tweak the selectors.
Full Code
const axios = require('axios');
const fs = require('fs');
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
// Define the Reddit URL you want to download
const reddit_url = "https://www.reddit.com";
// Define a User-Agent header
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" // Replace with your User-Agent string
};
// Send a GET request to the URL with the User-Agent header
axios.get(reddit_url, { headers })
.then(async (response) => {
if (response.status === 200) {
// Get the HTML content of the page
const html_content = response.data;
// Specify the filename to save the HTML content
const filename = "reddit_page.html";
// Save the HTML content to a file
fs.writeFileSync(filename, html_content, 'utf-8');
console.log(`Reddit page saved to ${filename}`);
// Parse the HTML content using JSDOM
const dom = new JSDOM(html_content);
// Find all blocks with the specified tag and class
const blocks = dom.window.document.querySelectorAll('shreddit-post.block.relative.cursor-pointer.bg-neutral-background.focus-within:bg-neutral-background-hover.hover:bg-neutral-background-hover.xs:rounded-[16px].p-md.my-2xs.nd:visible');
// Iterate through the blocks and extract information from each one
blocks.forEach((block) => {
const permalink = block.getAttribute('permalink');
const content_href = block.getAttribute('content-href');
const comment_count = block.getAttribute('comment-count');
const post_title = block.querySelector('div[slot="title"]').textContent.trim();
const author = block.getAttribute('author');
const score = block.getAttribute('score');
// Print the extracted information for each block
console.log(`Permalink: ${permalink}`);
console.log(`Content Href: ${content_href}`);
console.log(`Comment Count: ${comment_count}`);
console.log(`Post Title: ${post_title}`);
console.log(`Author: ${author}`);
console.log(`Score: ${score}`);
console.log("\n");
});
} else {
console.log(`Failed to download Reddit page (status code ${response.status})`);
}
})
.catch((error) => {
console.error(error);
});