Web scraping is the process of automatically extracting data from websites. This handy PHP script scrapes post data from Reddit by fetching the HTML content of a Reddit page and then using DOM parsing and CSS selectors to extract information like titles, scores, authors, etc.
here is the page we are talking about
Let's walk through it step-by-step.
Prerequisites
To run this code, you'll need:
First make sure you have PHP cli:
php -v
Then you can install simple_html_dom by downloading it from Sourceforge or via Composer:
composer require sunra/php-simple-html-dom-parser
Importing Libraries
We start by including the simple_html_dom library which will handle parsing and searching the HTML:
require('simple_html_dom.php');
Defining URLs and Headers
Next we define the Reddit URL we want to scrape, and a User-Agent header to send with the requests:
$reddit_url = "<https://www.reddit.com>";
$headers = array(
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"
);
It's best practice to identify your scraper instead of faking a browser User-Agent. But some sites block scraping bots so this helps bypass that.
Initializing cURL
We use cURL to make the HTTP requests in PHP. So we initialize a cURL session:
$ch = curl_init();
And configure the options:
curl_setopt($ch, CURLOPT_URL, $reddit_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
Here we set the URL to fetch, enable return transfer to get the response directly, and add our custom User-Agent header.
Making the Request
With cURL configured, we use
$response = curl_exec($ch);
We also check that it was successful by verifying the response code is 200 OK:
if (curl_getinfo($ch, CURLINFO_HTTP_CODE) == 200) {
// Request succeeded!
} else {
// Request failed
}
And save the HTML content to a file:
$html_content = $response;
$filename = "reddit_page.html";
file_put_contents($filename, $html_content);
This saves the raw HTML we'll parse next.
Parsing HTML
With simple_html_dom, parsing HTML is easy. We just initialize a new DOM object and load the HTML content:
$html = new simple_html_dom();
$html->load($response);
Now we have tons of helpful DOM traversal methods to extract data!
Extracting Data with Selectors
Inspecting the elements
Upon inspecting the HTML in Chrome, you will see that each of the posts have a particular element shreddit-post and class descriptors specific to them…
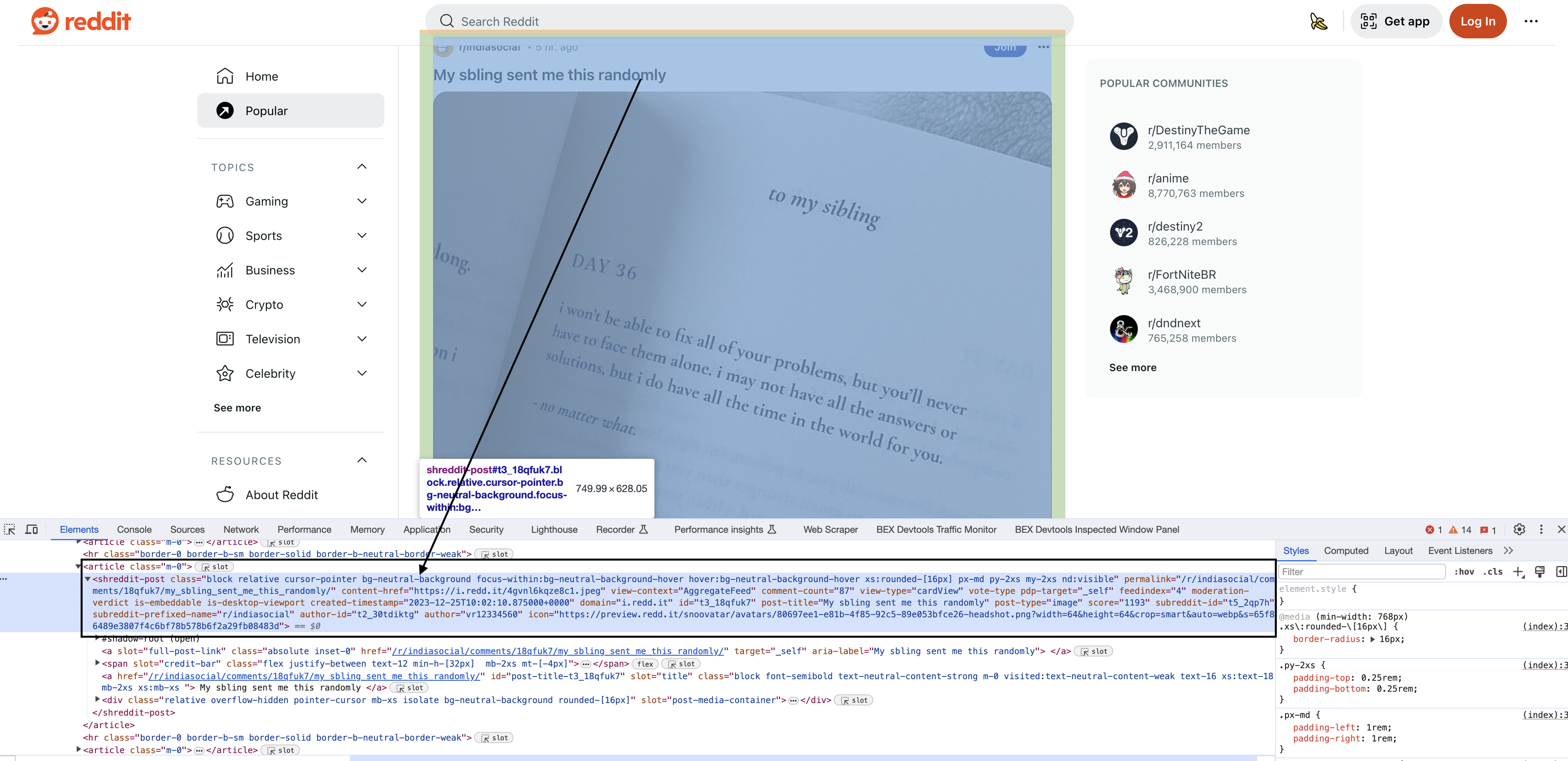
This is where most people struggle with web scraping - how to write the CSS selectors to actually match the content you want.
Let's break this down:
$blocks = $html->find('shreddit-post[class=block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px] p-md my-2xs nd:visible]');
The key things to understand are:
This gives us all the post block elements.
Extracting Post Data
Inside the loop, we use other DOM methods to get attributes and values:
foreach ($blocks as $block) {
$permalink = $block->getAttribute('permalink');
$content_href = $block->getAttribute('content-href');
$comment_count = $block->getAttribute('comment-count');
$post_title = $block->find('div[slot=title]', 0)->plaintext;
$author = $block->getAttribute('author');
$score = $block->getAttribute('score');
// Print post data
}
And we print out all the extracted fields!
Full Code
Here is the complete script for reference:
<?php
// Include the simple_html_dom library for HTML parsing
require('simple_html_dom.php');
// Define the Reddit URL you want to download
$reddit_url = "https://www.reddit.com";
// Define a User-Agent header
$headers = array(
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36" // Replace with your User-Agent string
);
// Initialize a cURL session
$ch = curl_init();
// Set the cURL options
curl_setopt($ch, CURLOPT_URL, $reddit_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
// Send the GET request to the URL
$response = curl_exec($ch);
// Check if the request was successful (status code 200)
if (curl_getinfo($ch, CURLINFO_HTTP_CODE) == 200) {
// Get the HTML content of the page
$html_content = $response;
// Specify the filename to save the HTML content
$filename = "reddit_page.html";
// Save the HTML content to a file
file_put_contents($filename, $html_content);
echo "Reddit page saved to $filename\n";
} else {
echo "Failed to download Reddit page (status code " . curl_getinfo($ch, CURLINFO_HTTP_CODE) . ")\n";
}
// Create a DOM object
$html = new simple_html_dom();
$html->load($response);
// Find all blocks with the specified tag and class
$blocks = $html->find('shreddit-post[class=block relative cursor-pointer bg-neutral-background focus-within:bg-neutral-background-hover hover:bg-neutral-background-hover xs:rounded-[16px] p-md my-2xs nd:visible]');
// Iterate through the blocks and extract information from each one
foreach ($blocks as $block) {
$permalink = $block->getAttribute('permalink');
$content_href = $block->getAttribute('content-href');
$comment_count = $block->getAttribute('comment-count');
$post_title = $block->find('div[slot=title]', 0)->plaintext;
$author = $block->getAttribute('author');
$score = $block->getAttribute('score');
// Print the extracted information for each block
echo "Permalink: $permalink\n";
echo "Content Href: $content_href\n";
echo "Comment Count: $comment_count\n";
echo "Post Title: $post_title\n";
echo "Author: $author\n";
echo "Score: $score\n\n";
}
// Close the cURL session
curl_close($ch);