Gathering data by scraping websites sounds advanced, but is easy to pick up. We'll extract a table from Wikipedia in Objective-C with just 34 lines of code! No need to feel overwhelmed - I'll walk you through it step-by-step.
Here's what you'll learn:
Let's get scraping!
Our Goal
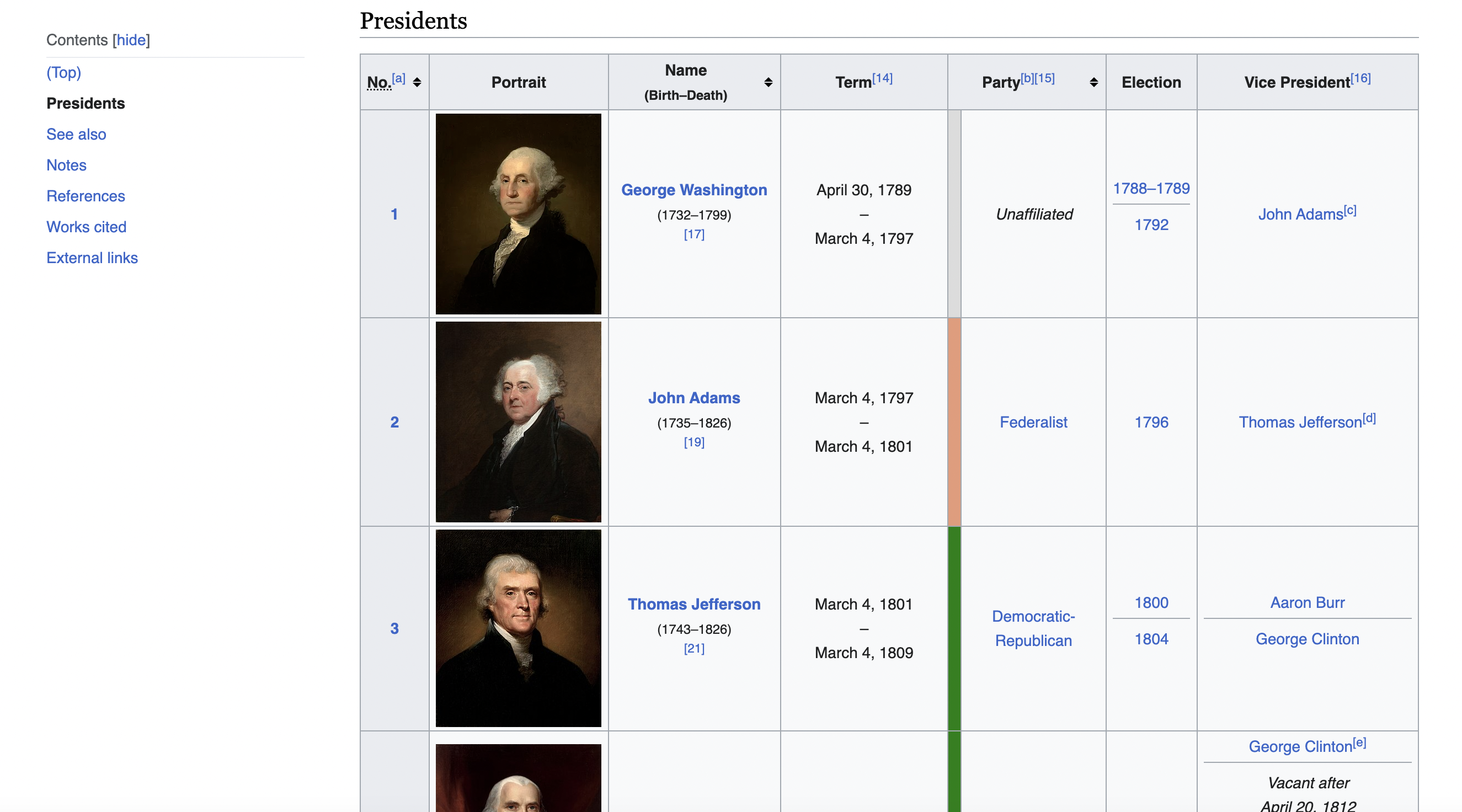
We want to get data on all the Presidents of the United States from this Wikipedia page.
It has a nicely formatted HTML table that serves our purpose. We'll use Objective-C and a nifty library called TFHpple to scrape it.
This is the table we are talking about
Key Concepts
Before we jump into the code, let's understand at a high-level what's going on behind the scenes:
We're essentally asking Wikipedia for data and processing the response - pretty cool!
The Code
Time to scrape. I'll break the full code down section-by-section. Don't worry if something is unclear at first, I'll explain everything.
Imports & Setup
#import <Foundation/Foundation.h>
#import "TFHpple.h"
int main(int argc, const char * argv[]) {
@autoreleasepool {
We import Foundation to use Apple's frameworks and the TFHpple parser library. The rest sets up the main function.
Pro Tip: Importing useful libraries upfront saves headaches later!
Define URL
NSString *urlString = @"<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>";
NSURL *url = [NSURL URLWithString:urlString];
We initialize a NSString with the URL of the Wikipedia page we want to scrape.
Then create a NSURL object from that string to represent the target URL. All web pages have a unique address - this is ours.
Set User Agent Header
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
};
We set a custom User-Agent header that mimics a Chrome browser request.
Pro Tip: Websites treat programs differently from browsers. Faking the header helps avoid blocks.
Create and Send Request
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
[request setAllHTTPHeaderFields:headers];
NSURLSession *session = [NSURLSession sharedSession];
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
First we initialize a mutable request object with our target NSURL.
We attach the headers dictionary to it containing the User-Agent.
Next we get a shared NSURLSession instance and call dataTaskWithRequest on it. This sends an asynchronous GET request to the URL when we resume the task.
The completion handler is the meat of our scraper...
Handle the Response
if (error) {
NSLog(@"Failed to retrieve the web page. Error: %@", error.localizedDescription);
return;
}
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse*) response;
if (httpResponse.statusCode == 200) {
We check if any errors occurred during the request. If so, we print it and return.
Otherwise, we access the HTTP status code to check it was successful. Status 200 means OK!
Inspecting the page
When we inspect the page we can see that the table has a class called wikitable and sortable
TFHpple *doc = [[TFHpple alloc] initWithHTMLData:data];
NSArray *tables = [doc searchWithXPathQuery:@"//table[@class='wikitable sortable']"];
if (tables.count > 0) {
TFHppleElement *table = tables[0];
NSMutableArray *data = [NSMutableArray array];
We initialize TFHpple by passing the raw HTML webpage data.
searchWithXPathQuery lets us find elements by their XPath. We target the presidential data table using its class name.
If found, we get the first matching table element then initialize a NSMutableArray to store our scraped data.
Extract Rows & Columns
NSArray *rows = [table childrenWithTagName:@"tr"];
for (int i = 1; i < rows.count; i++) {
TFHppleElement *row = rows[i];
NSArray *columns = [row children];
NSMutableArray *rowData = [NSMutableArray array];
We get all the For each row, find all columns using children again and initialize a rowData array. Inside this nested loop, we extract the text content of each cell stripping whitespace. We add this cleaned cell data into our rowData array and the full row into the main data array. Finally, we can iterate through our 2D array and access each piece of data we want to print! The full row and column position references were figured out through trial and error. And we're done - not so bad for a beginner, right? Let's recap what we learned: With just 34 lines of code! You could scrape bigger tables or multiple ones from the same site. Try removing boilerplate code with libraries like AFNetworking. Or queue requests asynchronously for efficiency. Hope this tutorial helped you grasp the basics. Web scraping isn't so daunting when taken one step at a time. Feel free to tweak the code and practice on other websites. Happy scraping! In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser! If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail. Overcoming IP Blocks Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works. Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. We have a running offer of 1000 API calls completely free. Register and get your free API Key here.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: row elements from our table. Loop through them skipping the first header row. for (TFHppleElement *col in columns) {
NSString *text = [col content];
[rowData addObject:[text stringByTrimmingCharactersInSet:[NSCharacterSet whitespaceAndNewlineCharacterSet]]];
}
[data addObject:rowData];
}
Print Scraped Data
for (NSArray *presidentData in data) {
NSLog(@"President Data:");
NSLog(@"Number: %@", presidentData[0]);
NSLog(@"Name: %@", presidentData[2]);
NSLog(@"Term: %@", presidentData[3]);
NSLog(@"Party: %@", presidentData[5]);
NSLog(@"Election: %@", presidentData[6]);
NSLog(@"Vice President: %@", presidentData[7]);
NSLog(@"\\n");
}
Key Takeaways
What Next?
#import <Foundation/Foundation.h>
#import "TFHpple.h"
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Define the URL of the Wikipedia page
NSString *urlString = @"https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States";
NSURL *url = [NSURL URLWithString:urlString];
// Define a user-agent header to simulate a browser request
NSDictionary *headers = @{
@"User-Agent": @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
};
// Create a request with headers
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
[request setAllHTTPHeaderFields:headers];
// Send an HTTP GET request to the URL
NSURLSession *session = [NSURLSession sharedSession];
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request completionHandler:^(NSData *data, NSURLResponse *response, NSError *error) {
if (error) {
NSLog(@"Failed to retrieve the web page. Error: %@", error.localizedDescription);
return;
}
NSHTTPURLResponse *httpResponse = (NSHTTPURLResponse *)response;
if (httpResponse.statusCode == 200) {
// Parse the HTML content of the page using TFHpple
TFHpple *doc = [[TFHpple alloc] initWithHTMLData:data];
// Find the table with the specified class name
NSArray *tables = [doc searchWithXPathQuery:@"//table[@class='wikitable sortable']"];
if (tables.count > 0) {
TFHppleElement *table = tables[0];
// Initialize an empty array to store the table data
NSMutableArray *data = [NSMutableArray array];
// Iterate through the rows of the table
NSArray *rows = [table childrenWithTagName:@"tr"];
for (int i = 1; i < rows.count; i++) { // Skip the header row
TFHppleElement *row = rows[i];
// Extract data from each column and append it to the data array
NSArray *columns = [row children];
NSMutableArray *rowData = [NSMutableArray array];
for (TFHppleElement *col in columns) {
NSString *text = [col content];
[rowData addObject:[text stringByTrimmingCharactersInSet:[NSCharacterSet whitespaceAndNewlineCharacterSet]]];
}
[data addObject:rowData];
}
// Print the scraped data for all presidents
for (NSArray *presidentData in data) {
NSLog(@"President Data:");
NSLog(@"Number: %@", presidentData[0]);
NSLog(@"Name: %@", presidentData[2]);
NSLog(@"Term: %@", presidentData[3]);
NSLog(@"Party: %@", presidentData[5]);
NSLog(@"Election: %@", presidentData[6]);
NSLog(@"Vice President: %@", presidentData[7]);
NSLog(@"\n");
}
} else {
NSLog(@"Table not found on the web page.");
}
} else {
NSLog(@"Failed to retrieve the web page. Status code: %ld", (long)httpResponse.statusCode);
}
}];
[dataTask resume];
[[NSRunLoop currentRunLoop] run];
}
return 0;
}curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!