Wikipedia contains a wealth of structured data on almost any topic imaginable. However, that data is embedded in HTML designed for human readers rather than machines. This is where web scraping comes in handy.
Let's imagine we want to collect some facts on all the US presidents - their names, terms, parties, vice presidents, etc. Rather than manually copying that information out of Wikipedia, we can write a script to extract it automatically.
The page we'll scrape is:
<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>
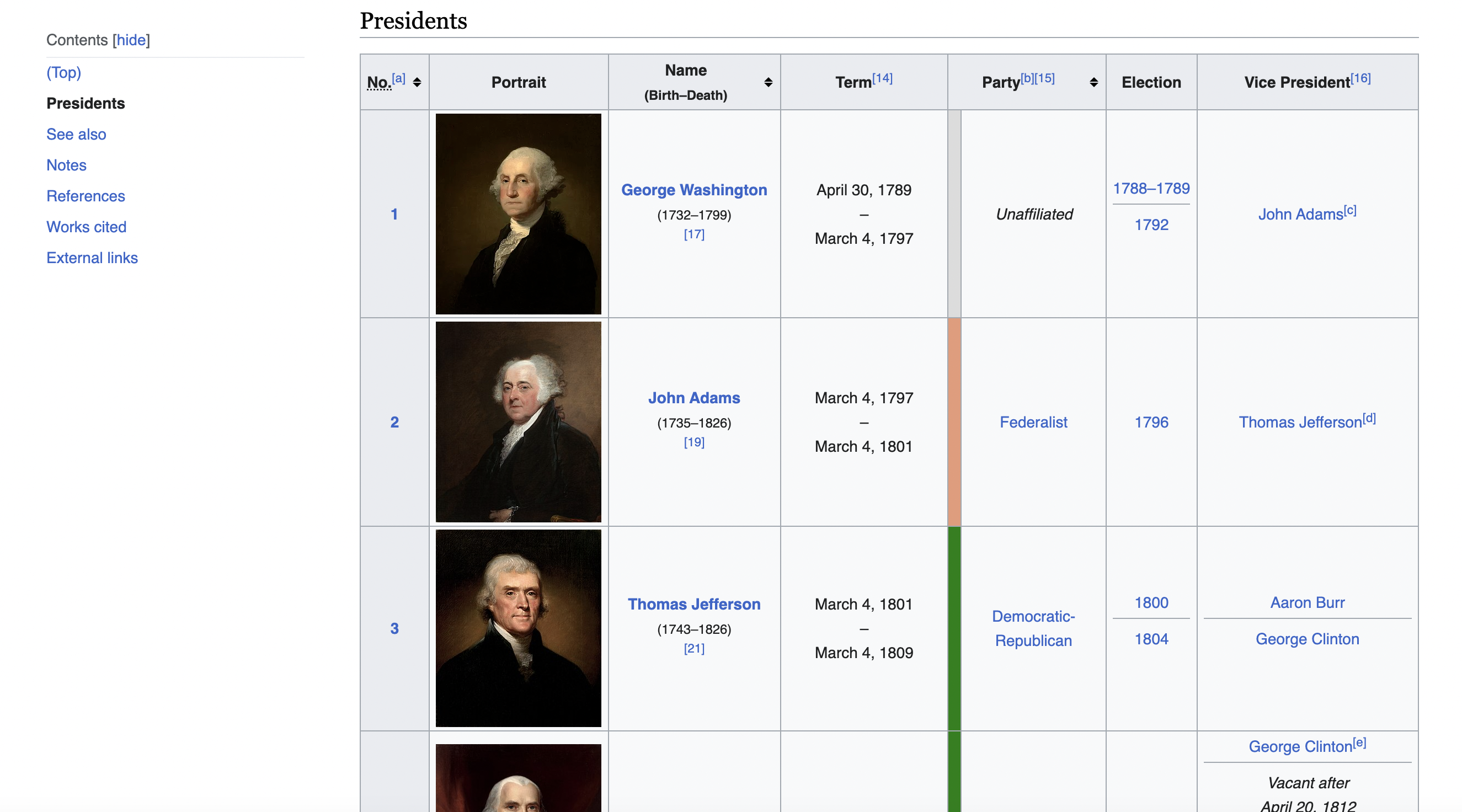
It contains a nice structured HTML table perfect for scraping.
This is the table we are talking about
Setting up the Tools
To scrape a web page, we need:
- A way to download the page content
- A way to parse the HTML content
For the first part, we'll use Ruby's built-in
For the second part, we'll use the popular Nokogiri library to parse and extract data out of the HTML. To install Nokogiri, run:
gem install nokogiri
Now let's look at the full scraper code:
require 'nokogiri'
require 'net/http'
# Define the URL of the Wikipedia page
url = "<https://en.wikipedia.org/wiki/List_of_presidents_of_the_United_States>"
# Define a user-agent header to simulate a browser request
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# Create an HTTP GET request with the headers
uri = URI(url)
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true if uri.scheme == 'https'
request = Net::HTTP::Get.new(uri.request_uri, headers)
# Send the request and check if it was successful (status code 200)
response = http.request(request)
if response.code.to_i == 200
# Parse the HTML content of the page using Nokogiri
doc = Nokogiri::HTML(response.body)
# Find the table with the specified class name
table = doc.at_css('table.wikitable.sortable')
# Initialize empty arrays to store the table data
data = []
# Iterate through the rows of the table
table.css('tr')[1..-1].each do |row| # Skip the header row
columns = row.css('td, th')
# Extract data from each column and append it to the data array
row_data = columns.map { |col| col.text.strip }
data.push(row_data)
end
# Print the scraped data for all presidents
data.each do |president_data|
puts "President Data:"
puts "Number: #{president_data[0]}"
puts "Name: #{president_data[2]}"
puts "Term: #{president_data[3]}"
puts "Party: #{president_data[5]}"
puts "Election: #{president_data[6]}"
puts "Vice President: #{president_data[7]}"
puts
end
else
puts "Failed to retrieve the web page. Status code: #{response.code}"
end
Let's break down what this code is doing step-by-step.
Making the HTTP Request
We first construct a GET request to fetch the Wikipedia page HTML:
uri = URI(url)
http = Net::HTTP.new(uri.host, uri.port)
http.use_ssl = true if uri.scheme == 'https'
request = Net::HTTP::Get.new(uri.request_uri, headers)
A couple things to notice here:
Once we have the request constructed, we can send it off:
response = http.request(request)
And check if it succeeded:
if response.code.to_i == 200
A status code of 200 means everything went well. Any other code likely means an error page.
Parsing the Page with Nokogiri
With the HTML in hand, we can start extracting the president data using Nokogiri:
doc = Nokogiri::HTML(response.body)
This parses the HTML into a structure Nokogiri can query.
Inspecting the page
When we inspect the page we can see that the table has a class called wikitable and sortable
table = doc.at_css('table.wikitable.sortable')
Then loop through the rows, skipping the header:
table.css('tr')[1..-1].each do |row|
And within each row, grab the text content of each cell:
columns = row.css('td, th')
row_data = columns.map { |col| col.text.strip }
The end result is a nice clean 2D array with data on each president.
Dealing with Changes
Here's an insider tip on dealing with changes - store an HTML snapshot of the page when you initially write the scraper. That way if the page format gets changed later, you can debug what broke more easily.
I once spent hours trying to figure out why a scraper broke before realizing the site had just added an extra navigation column that offset all my indexes!
Saving and Processing the Data
Once we've extracted the president data, there's many things we could do with it:
For now we just print it out:
data.each do |president_data|
puts "Number: #{president_data[0]}"
# etc...
end
But the ideas are endless!
Key Takeaways
The key steps of web scraping are:
- Downloading page content
- Parsing the content with a tool like Nokogiri
- Extracting the data you want
- Processing the scraped data further
The full code can be challenging for a beginner, but goes a long way in explaining how web scrapers really work under the hood.
Next Steps
To practice these concepts, try modifying the scraper:
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.