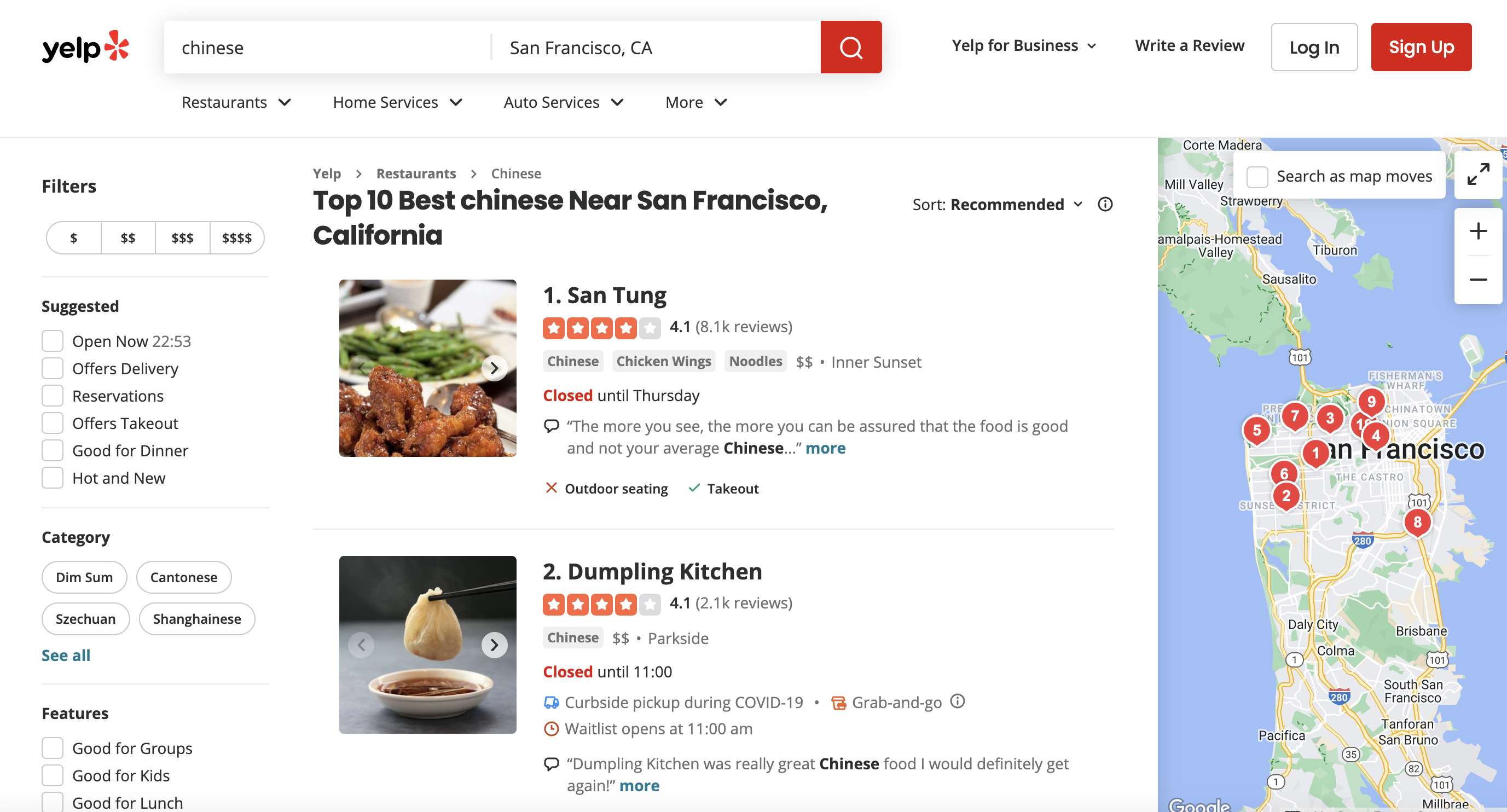
Scenario
Imagine you're a business analyst who wants to collect data on Chinese restaurants in San Francisco from Yelp. You want to extract information such as the business name, rating, number of reviews, price range, and location. This data can be used for market research, competitor analysis, or other business insights.
This is the page we are talking about
Step-by-Step Guide
Step 1: Introduction to Web Scraping and Yelp
Web scraping is the process of extracting data from websites. It's valuable for various purposes, including research, analysis, and data collection. Yelp is a popular platform for finding information about businesses, making it a prime candidate for scraping data like business listings.
To scrape Yelp, we'll use Node.js, Axios for making HTTP requests, and Cheerio for parsing HTML. However, scraping Yelp directly can be challenging due to anti-bot mechanisms in place. This is where premium proxies come in.
Why Premium Proxies?
Yelp employs anti-bot measures to prevent automated scraping. These measures can include IP blocking, CAPTCHAs, and rate limiting. Premium proxies provide a way to bypass these restrictions by routing your requests through different IP addresses, making it harder for Yelp to detect and block your scraping activities.
In the provided code, we'll utilize premium proxies from ProxiesAPI to access Yelp data without interruptions.
Step 2: Setting Up Your Environment
Before diving into the code, you need to set up your environment. Here are the steps:
Installation:
- Node.js: If you haven't already, install Node.js from the official website (https://nodejs.org/). This will allow you to run JavaScript code on your machine.
- Axios: Install Axios, a library for making HTTP requests, by running the following command in your terminal:
- Cheerio: Install Cheerio, a library for parsing HTML, using the following command:
Obtaining a ProxiesAPI Key:
- ProxiesAPI Key: Go to the ProxiesAPI website (https://proxiesapi.com/) and sign up for an account. Once registered, you'll receive an API key, which is essential for using premium proxies.
With your environment set up and the API key in hand, you're ready to proceed with the code.
Step 3: Understanding the Code
Now, let's break down the code provided in the beginning. We'll go through it step by step, explaining its purpose and functionality.
Importing Libraries:
The code starts by importing the necessary libraries: Axios for making HTTP requests and Cheerio for parsing HTML.
const axios = require('axios');
const cheerio = require('cheerio');
Defining the Yelp URL:
Next, we define the URL of the Yelp search page for Chinese restaurants in San Francisco:
const url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
Encoding the URL:
To ensure the URL is properly formatted for use in an HTTP request, we encode it:
const encodedUrl = encodeURIComponent(url
);
Constructing the API URL:
We construct the API URL for ProxiesAPI by combining the encoded Yelp URL and your API key:
const apiKey = "YOUR_API_KEY";
const apiURL = `http://api.proxiesapi.com/?premium=true&auth_key=${apiKey}&url=${encodedUrl}`;
Simulating a Browser Request:
To mimic a browser request, we define user-agent headers that include details like the browser's user agent, accepted languages, and more:
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "<https://www.google.com/>", // Simulate a referrer
};
Sending an HTTP GET Request:
The core of the code is an HTTP GET request to the ProxiesAPI URL with the headers we defined:
axios.get(apiURL, { headers })
.then(response => {
// Check if the request was successful (status code 200)
if (response.status === 200) {
// ... (Code for parsing and extracting data)
} else {
console.log(`Failed to retrieve data. Status Code: ${response.status}`);
}
})
.catch(error => {
console.error(error);
});
At this point, we have successfully set up our environment and prepared the code to make requests to Yelp through premium proxies. In the next steps, we'll dive into how the code extracts business listings from Yelp.
Step 4: Extracting Business Listings
The code uses Cheerio to parse the HTML content of the Yelp page and extract information from business listings. Let's explore how this works.
Loading HTML with Cheerio:
Inside the
const $ = cheerio.load(response.data);
Finding Listings:
Yelp's listings are contained within specific HTML elements. We use Cheerio to find all the listings and store them in the
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
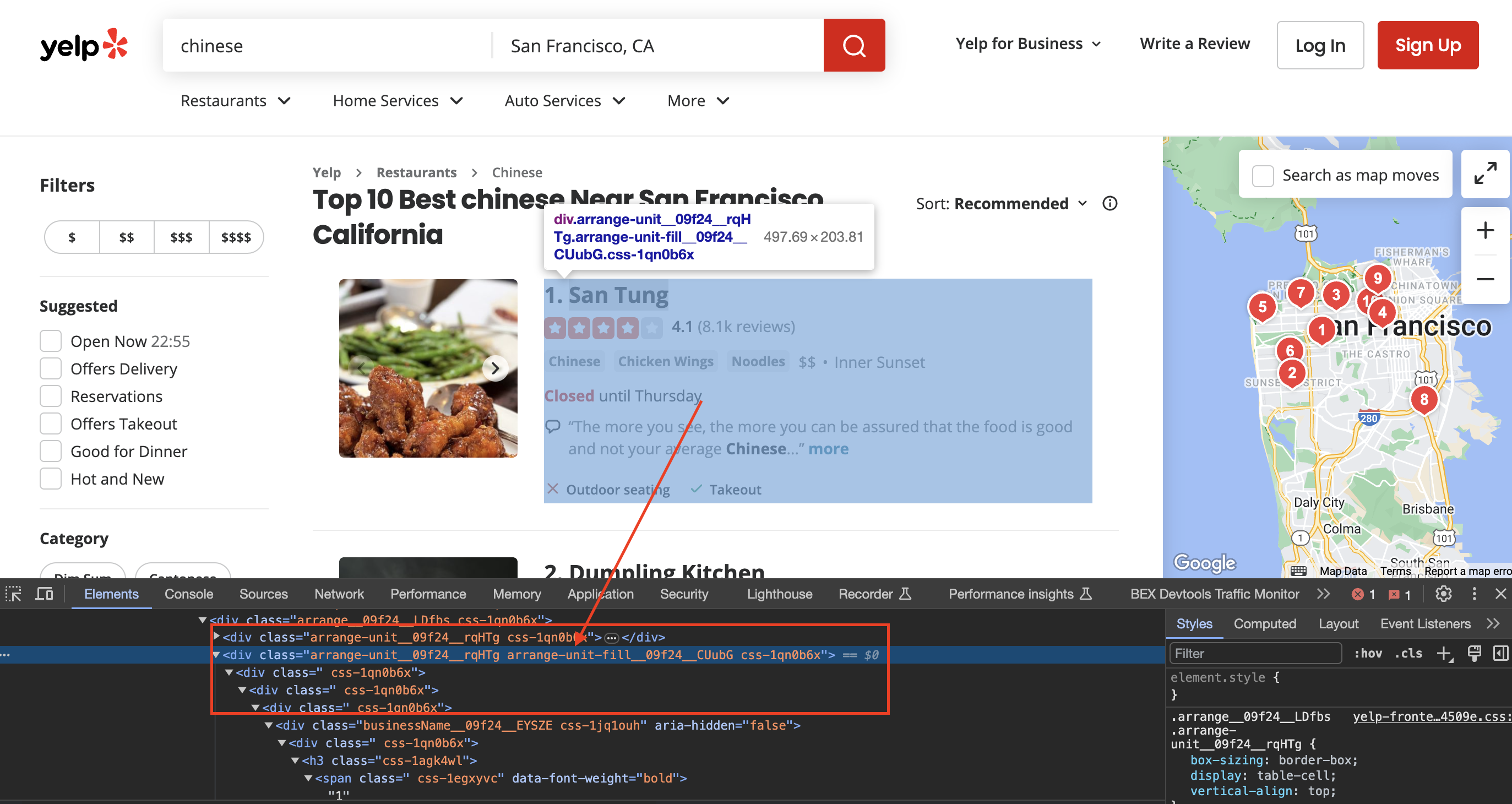
const listings = $('div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x');
Looping Through Listings:
We then loop through each listing using the
listings.each((index, element) => {
// ... (Code for extracting and printing information)
});
Extracting Information:
Inside the loop, we extract information such as the business name, rating, price range, number of reviews, and location from each listing:
const businessNameElem = $(element).find('a.css-19v1rkv');
const businessName = businessNameElem.text().trim() || "N/A";
// Similar code for extracting rating, price range, number of reviews, and location
Printing Information:
Finally, we print the extracted information for each business listing:
console.log("Business Name:", businessName);
console.log("Rating:", rating);
console.log("Number of Reviews:", numReviews);
console.log("Price Range:", priceRange);
console.log("Location:", location);
console.log("===============================");
The code continues to loop through all the listings, extracting and printing information until it processes all the listings on the Yelp page.
Step 5: Handling Data
At this point, you have successfully scraped business information from Yelp. Depending on your needs, you can handle the data in various ways:
Step 6: Challenges and Considerations
Web scraping can present challenges, and it's important to be aware of them:
Step 7: Conclusion
In this article, we've walked you through the process of scraping Yelp business listings, from setting up your environment and understanding the code to extracting and handling data. Web scraping can be a powerful tool for gathering information, but it's important to use it responsibly and ethically.
Remember that websites may have terms of service that prohibit or restrict scraping, so always check and adhere to their policies. Additionally, be prepared to adapt your code as websites evolve.
Happy scraping, and may your data analysis endeavors be fruitful!
Full Code
const axios = require('axios');
const cheerio = require('cheerio');
// URL of the Yelp search page
const url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
// Encode the URL
const encodedUrl = encodeURIComponent(url);
// Define your API key
const apiKey = "YOUR_API_KEY";
// Construct the API URL with the encoded Walmart URL
const apiURL = `http://api.proxiesapi.com/?premium=true&auth_key=${apiKey}&url=${encodedUrl}`;
// Define a user-agent header to simulate a browser request
const headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language": "en-US,en;q=0.5",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.google.com/", // Simulate a referrer
};
// Send an HTTP GET request to the API URL with the headers
axios.get(apiURL, { headers })
.then(response => {
if (response.status === 200) {
// Load the HTML content into cheerio
const $ = cheerio.load(response.data);
// Find all the listings
const listings = $('div.arrange-unit__09f24__rqHTg.arrange-unit-fill__09f24__CUubG.css-1qn0b6x');
console.log(listings.length);
// Loop through each listing and extract information
listings.each((index, element) => {
// Extract business name
const businessNameElem = $(element).find('a.css-19v1rkv');
const businessName = businessNameElem.text().trim() || "N/A";
// If business name is not "N/A," then print the information
if (businessName !== "N/A") {
// Extract rating
const ratingElem = $(element).find('span.css-gutk1c');
const rating = ratingElem.text().trim() || "N/A";
// Extract price range
const priceRangeElem = $(element).find('span.priceRange__09f24__mmOuH');
const priceRange = priceRangeElem.text().trim() || "N/A";
// Extract number of reviews and location
const spanElements = $(element).find('span.css-chan6m');
let numReviews = "N/A";
let location = "N/A";
// Check if there are at least two span elements
if (spanElements.length >= 2) {
numReviews = $(spanElements[0]).text().trim();
location = $(spanElements[1]).text().trim();
} else if (spanElements.length === 1) {
// If there's only one span element, check if it's for Number of Reviews or Location
const text = $(spanElements[0]).text().trim();
if (!isNaN(text)) {
numReviews = text;
} else {
location = text;
}
}
// Print the extracted information
console.log(`Business Name: ${businessName}`);
console.log(`Rating: ${rating}`);
console.log(`Number of Reviews: ${numReviews}`);
console.log(`Price Range: ${priceRange}`);
console.log(`Location: ${location}`);
console.log("===============================");
}
});
} else {
console.log(`Failed to retrieve data. Status Code: ${response.status}`);
}
})
.catch(error => {
console.error(error);
});