Yelp is one of the largest crowdsourced review sites, with over 200 million reviews of local businesses around the world. The depth of data on Yelp (ratings, price levels, photos etc.) makes it an attractive target for scraping. You may want to gather and analyze Yelp data for market research, lead generation, competitor analysis, or a custom business directory.
This is the page we are talking about
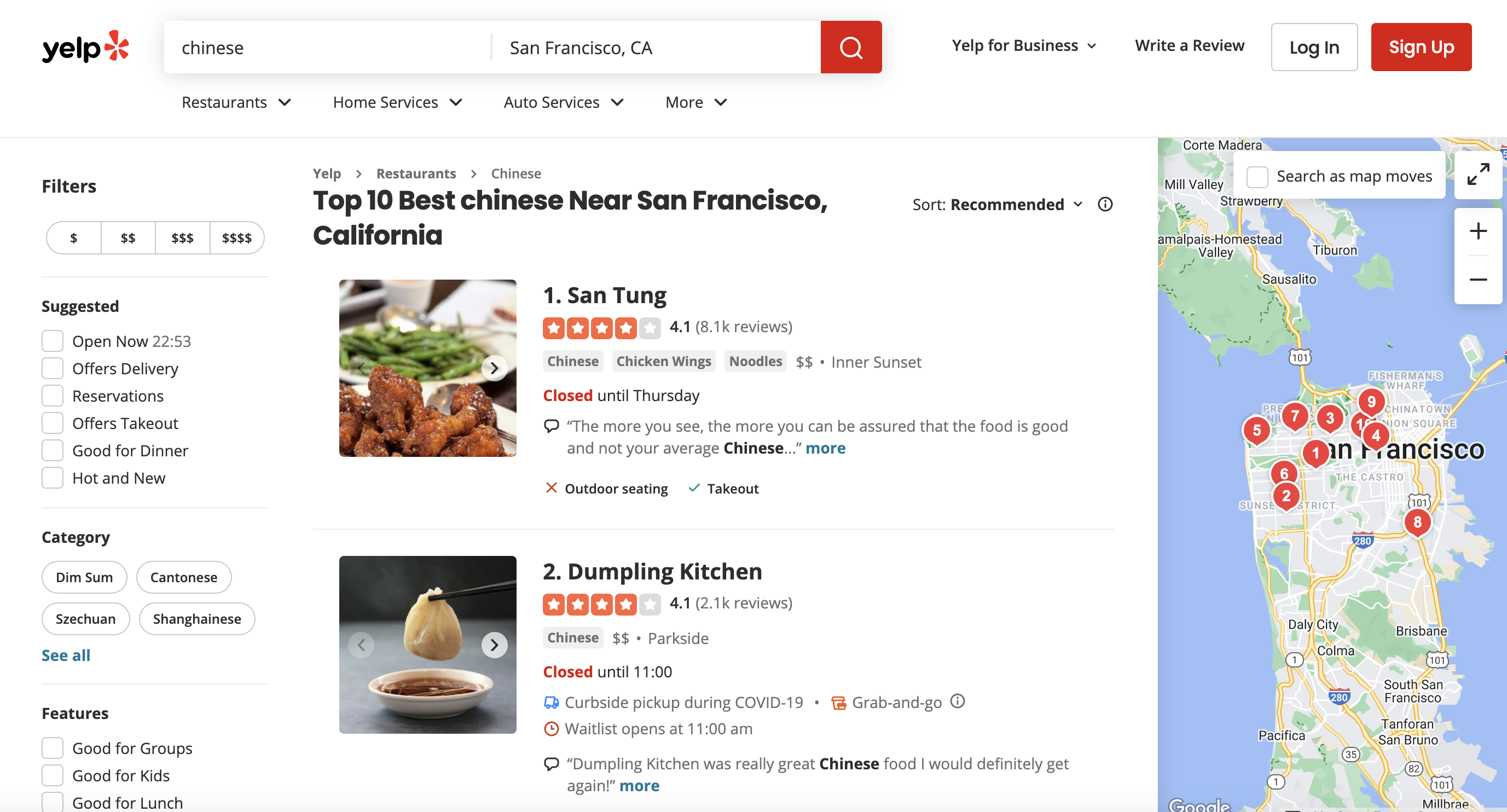
However, consumer sites like Yelp actively block scraping bots to prevent data theft. That's where premium proxies come in handy...
Using Premium Proxies to Bypass Yelp Blocks
Like most large sites, Yelp utilizes advanced anti-scraping mechanisms to detect bots and block IP addresses making too many requests. Trying to scrape Yelp straight from your own IP would fail pretty quickly.
ProxiesAPI offers constantly rotating premium residential IPs from around the world. By routing our requests through ProxiesAPI instead of your own IP, we can imitate organic human traffic patterns and bypass blocks. It's an essential technique for successfully scraping guarded sites like Yelp at scale.
Okay, with that primer out of the way, let's dive into the code...
Importing Required Packages
We'll utilize HtmlAgilityPack to parse HTML and pull data from page elements:
using System;
using System.Net.Http;
using System.Threading.Tasks;
using HtmlAgilityPack;
HttpClient handles our web requests. We create a static instance to reuse across requests:
static readonly HttpClient client = new HttpClient();
Crafting Our Yelp Search URL
We want to scrape Chinese restaurants in San Francisco. Yelp makes this easy with search filters:
string url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco,+CA>";
To leverage ProxiesAPI, we pass our Yelp URL into the API and get back a proxied URL:
string api_url = $"<http://api.proxiesapi.com/?premium=true&auth_key=YOUR AUTH KEY&url={Uri.EscapeDataString(url)}>";
Make sure to use your own key. We URI-encode the Yelp URL to handle special characters properly.
Configuring Request Headers
Yelp will spot a basic bot, so we spoof a Chrome browser visit by setting valid user-agent, language and other headers:
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0...");
client.DefaultRequestHeaders.Add("Accept-Language", "en-US,en;q=0.5");
client.DefaultRequestHeaders.Add("Accept-Encoding", "gzip, deflate, br");
client.DefaultRequestHeaders.Add("Referer", "<https://www.google.com/>");
This tricks Yelp into serving us actual site content instead of error pages.
Making the Initial Request
With our proxied API URL and mimicked browser headers, we can send the GET request:
HttpResponseMessage response = await client.GetAsync(api_url);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
We confirm we get a 2XX status code before reading the full HTML response body.
Parsing Listings with XPath
Now the fun part - extracting data! HtmlAgilityPack allows us to query elements using XPath syntax.
First we load the HTML:
var doc = new HtmlDocument();
doc.LoadHtml(responseBody);
Then we grab all listing nodes, using the key CSS class names:
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
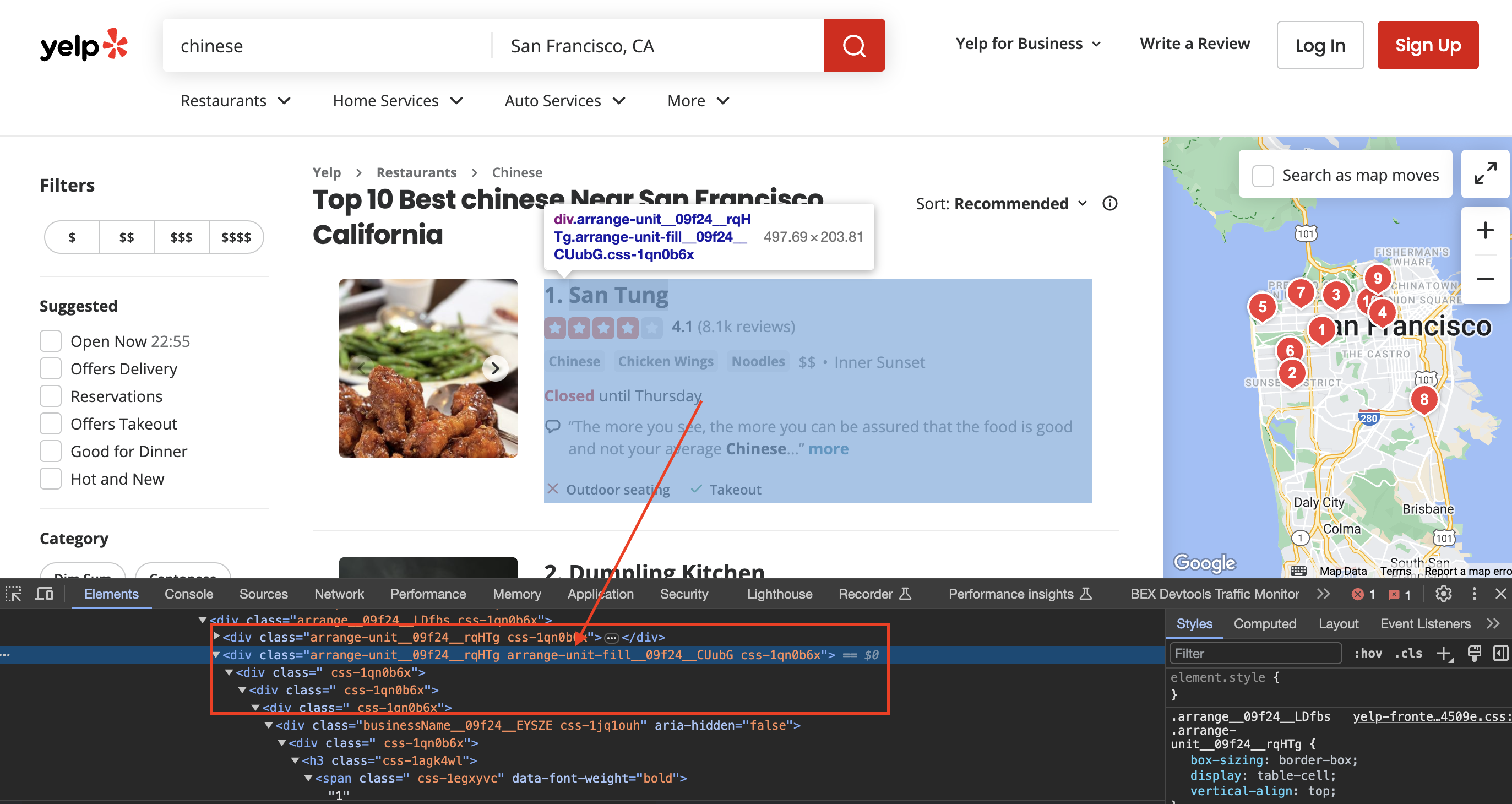
var listings = doc.DocumentNode.SelectNodes("//div[contains(@class, 'arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x')]");
Console.WriteLine(listings?.Count ?? 0);
XPath Axes like //div let us search the entire DOM for nodes matching our class query. The ?. operator avoids null reference errors.
We print the number of listings found to confirm it works.
Extracting Listing Data
With a list of DOM nodes in hand, we iterate through to extract info:
foreach (var listing in listings)
{
// Get business name
var businessNameNode = listing.SelectSingleNode(".//a[contains(@class, 'css-19v1rkv')]");
string businessName = businessNameNode != null ? businessNameNode.InnerText.Trim() : "N/A";
// Get rating
var ratingNode = listing.SelectSingleNode(".//span[contains(@class, 'css-gutk1c')]");
string rating = ratingNode != null ? ratingNode.InnerText.Trim() : "N/A";
// Get price range
var priceRangeNode = listing.SelectSingleNode(".//span[contains(@class, 'priceRange__09f24__mmOuH')]");
string priceRange = priceRangeNode != null ? priceRangeNode.InnerText.Trim() : "N/A";
// Get review count and location
string numReviews = "N/A";
string location = "N/A";
var spanElements = listing.SelectNodes(".//span[contains(@class, 'css-chan6m')]");
if (spanElements != null)
{
// Logic to handle multiple layouts
...
}
// Print extracted data
Console.WriteLine($"Name: {businessName}");
Console.WriteLine($"Rating: {rating}");
...
}
The key is crafting XPath queries specific to each data field, handling when nodes don't exist, dealing with multiple potential markup layouts, and printing the scraped attributes.
I've omitted some code for brevity, see the full sample below.
Dealing with Errors
We wrap our request in a try/catch block to handle issues:
try {
// Request code
}
catch (HttpRequestException e)
{
Console.WriteLine($"Error: {e.Message}");
}
This lets us print the error message without breaking runtime.
Recommended Next Steps
And that's the basics of scraping Yelp listings! Here are some ideas for leveling up:
Whether you want to collect data for research or business purposes, I hope this gives you a blueprint to start scraping powerful sites like Yelp. Never hesitate to reach out with questions!
Full Code Sample
Here is the complete code sample from the article for your reference:
using System;
using System.Net.Http;
using System.Threading.Tasks;
using HtmlAgilityPack;
class Program
{
static readonly HttpClient client = new HttpClient();
static async Task Main()
{
// URL of the Yelp search page
string url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
// API URL with the encoded Yelp URL
string api_url = $"http://api.proxiesapi.com/?premium=true&auth_key=c0f0dcf86c434ca0ec8ddae676599a19_sr98766_ooPq87&url={Uri.EscapeDataString(url)}";
try
{
// Set the necessary headers
client.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
client.DefaultRequestHeaders.Add("Accept-Language", "en-US,en;q=0.5");
client.DefaultRequestHeaders.Add("Accept-Encoding", "gzip, deflate, br");
client.DefaultRequestHeaders.Add("Referer", "https://www.google.com/");
// Send an HTTP GET request to the URL
HttpResponseMessage response = await client.GetAsync(api_url);
response.EnsureSuccessStatusCode();
string responseBody = await response.Content.ReadAsStringAsync();
// Parse the HTML content of the page
var doc = new HtmlDocument();
doc.LoadHtml(responseBody);
// Find all the listings
var listings = doc.DocumentNode.SelectNodes("//div[contains(@class, 'arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x')]");
Console.WriteLine(listings?.Count ?? 0);
// Loop through each listing and extract information
foreach (var listing in listings)
{
// Extract business name
var businessNameNode = listing.SelectSingleNode(".//a[contains(@class, 'css-19v1rkv')]");
string businessName = businessNameNode != null ? businessNameNode.InnerText.Trim() : "N/A";
if (businessName != "N/A")
{
// Extract rating
var ratingNode = listing.SelectSingleNode(".//span[contains(@class, 'css-gutk1c')]");
string rating = ratingNode != null ? ratingNode.InnerText.Trim() : "N/A";
// Extract price range
var priceRangeNode = listing.SelectSingleNode(".//span[contains(@class, 'priceRange__09f24__mmOuH')]");
string priceRange = priceRangeNode != null ? priceRangeNode.InnerText.Trim() : "N/A";
// Initialize num_reviews and location
string numReviews = "N/A";
string location = "N/A";
var spanElements = listing.SelectNodes(".//span[contains(@class, 'css-chan6m')]");
if (spanElements != null)
{
if (spanElements.Count >= 2)
{
numReviews = spanElements[0].InnerText.Trim();
location = spanElements[1].InnerText.Trim();
}
else if (spanElements.Count == 1)
{
var text = spanElements[0].InnerText.Trim();
if (int.TryParse(text, out _))
{
numReviews = text;
}
else
{
location = text;
}
}
}
// Print the extracted information
Console.WriteLine($"Business Name: {businessName}");
Console.WriteLine($"Rating: {rating}");
Console.WriteLine($"Number of Reviews: {numReviews}");
Console.WriteLine($"Price Range: {priceRange}");
Console.WriteLine($"Location: {location}");
Console.WriteLine(new string('=', 30));
}
}
}
catch (HttpRequestException e)
{
Console.WriteLine($"Error: {e.Message}");
}
}
}