Web scraping can be a powerful tool for extracting data from websites. This guide will walk you through scraping Yelp business listings using PHP, with a focus on understanding each part of the code, especially the scraping logic using XPath.
This is the page we are talking about
Setup and Initial Code
First, ensure PHP and cURL are installed on your system. You'll also need a ProxiesAPI service account to bypass Yelp's anti-bot measures.
Let's start with the first part of the code:
// Function to URL-encode the URL
function encodeUrl($url) {
return urlencode($url);
}
// URL of the Yelp search page
$url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
// URL-encode the URL
$encoded_url = encodeUrl($url);
This code defines a function
Next, we prepare for the web request:
// API URL with the encoded Yelp URL
$api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=>" . $encoded_url;
// Initialize cURL session
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $api_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"Referer: <https://www.google.com/>"
));
This segment initializes a cURL session to make a request to the ProxiesAPI service. The HTTP headers simulate a browser request, helping to avoid detection by Yelp's anti-bot mechanisms.
Now, let's execute the request and handle the response:
// Execute cURL session
$response = curl_exec($ch);
$httpcode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
// Check if the request was successful (status code 200)
if ($httpcode == 200) {
// Save the response to a file
file_put_contents("yelp_html.html", $response);
...
} else {
echo "Failed to retrieve data. Status Code: " . $httpcode . PHP_EOL;
}
Here, the script executes the cURL request, checks the response's HTTP status code, and saves the successful response to a file.
Extracting Data with XPath
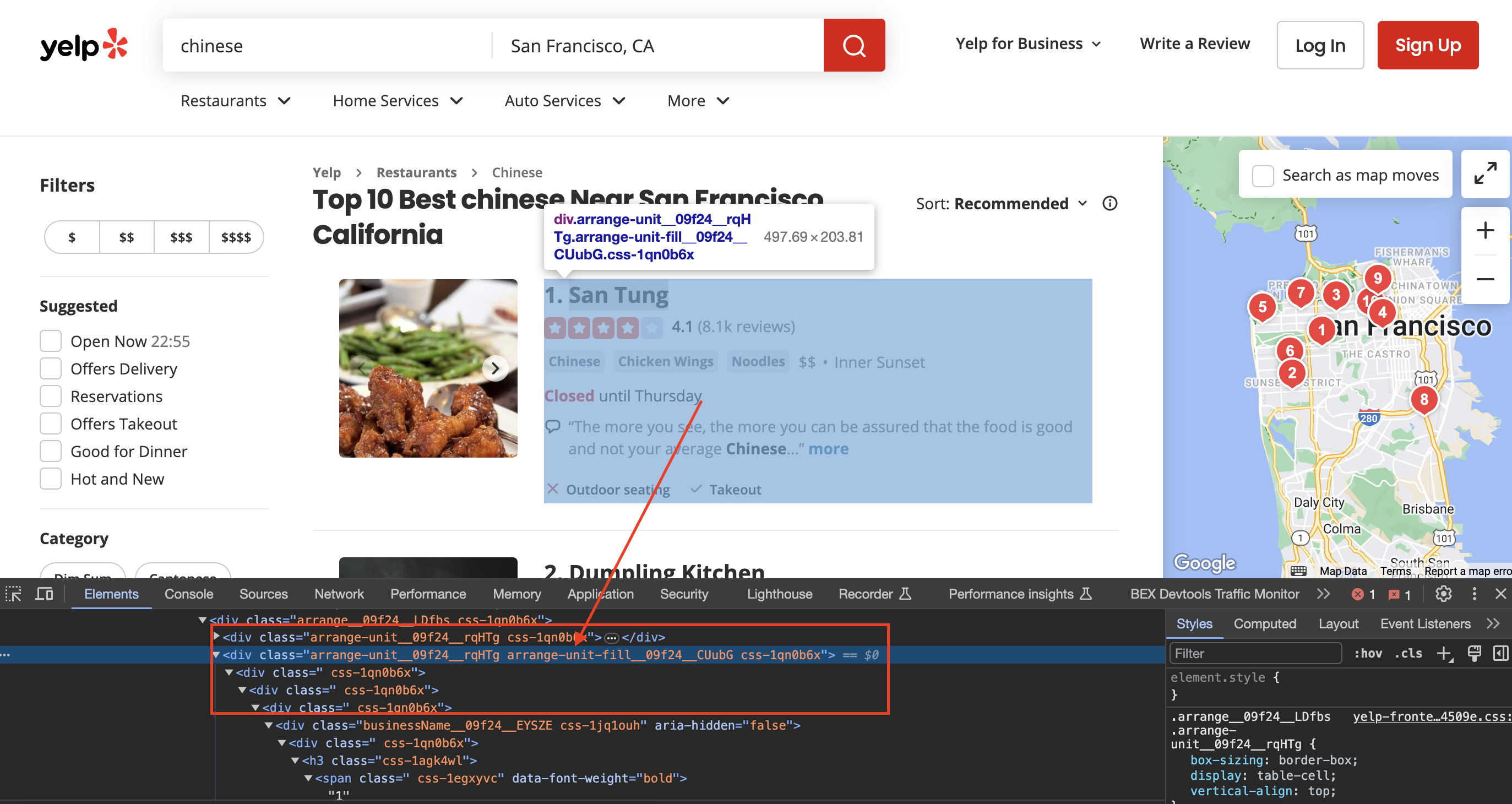
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x
The most crucial part of the script is extracting data using XPath. Let's break down this part:
// Create a new DOMDocument instance and load the HTML content
$dom = new DOMDocument;
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
// Find all the listings
$listings = $xpath->query("//div[contains(@class, 'arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x')]");
echo "Listings found: " . count($listings) . PHP_EOL;
This segment loads the HTML content into a
Next, we loop through each listing:
foreach ($listings as $listing) {
// Extracting business name
$businessNameNodes = $xpath->query(".//a[contains(@class, 'css-19v1rkv')]", $listing);
$businessName = $businessNameNodes->length > 0 ? trim($businessNameNodes->item(0)->nodeValue) : "N/A";
// Extracting rating
$ratingNodes = $xpath->query(".//span[contains(@class, 'css-gutk1c')]", $listing);
$rating = $ratingNodes->length > 0 ? trim($ratingNodes->item(0)->nodeValue) : "N/A";
...
}
In this part, XPath queries are used to extract specific details like business name and rating from each listing. The
Extracting Price Range
// Extracting price range
$priceRangeNodes = $xpath->query(".//span[contains(@class, 'priceRange__09f24__mmOuH')]", $listing);
$priceRange = $priceRangeNodes->length > 0 ? trim($priceRangeNodes->item(0)->nodeValue) : "N/A";
In this code block, we use XPath to locate the span element containing the price range. The
Extracting Number of Reviews and Location
The script then handles extracting the number of reviews and location, which can be slightly more complex due to the variability in the data format.
// Extracting number of reviews and location
$spanElements = $xpath->query(".//span[contains(@class, 'css-chan6m')]", $listing);
$numReviews = "N/A";
$location = "N/A";
if ($spanElements->length >= 2) {
$numReviews = trim($spanElements->item(0)->nodeValue);
$location = trim($spanElements->item(1)->nodeValue);
} elseif ($spanElements->length == 1) {
$text = trim($spanElements->item(0)->nodeValue);
if (is_numeric($text)) {
$numReviews = $text;
} else {
$location = $text;
}
}
In this section, the script looks for
This logic demonstrates how to handle different scenarios where the number of elements found can vary, and the data can have different formats or structures.
Conclusion
The latter part of the script showcases the flexibility required in web scraping. It demonstrates the need to write adaptable and robust code to accommodate various data formats and structures. Understanding and handling these nuances is key to successful data extraction in web scraping projects.
Full code:
<?php
// Function to URL-encode the URL
function encodeUrl($url) {
return urlencode($url);
}
// URL of the Yelp search page
$url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
// URL-encode the URL
$encoded_url = encodeUrl($url);
// API URL with the encoded Yelp URL
$api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=" . $encoded_url;
// Initialize cURL session
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $api_url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, array(
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"Referer: https://www.google.com/"
));
// Execute cURL session
$response = curl_exec($ch);
$httpcode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
// Check if the request was successful (status code 200)
if ($httpcode == 200) {
// Save the response to a file
file_put_contents("yelp_html.html", $response);
// Create a new DOMDocument instance and load the HTML content
$dom = new DOMDocument;
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
// Find all the listings
$listings = $xpath->query("//div[contains(@class, 'arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x')]");
echo "Listings found: " . count($listings) . PHP_EOL;
// Loop through each listing and extract information
foreach ($listings as $listing) {
// Extracting business name
$businessNameNodes = $xpath->query(".//a[contains(@class, 'css-19v1rkv')]", $listing);
$businessName = $businessNameNodes->length > 0 ? trim($businessNameNodes->item(0)->nodeValue) : "N/A";
// Extracting rating
$ratingNodes = $xpath->query(".//span[contains(@class, 'css-gutk1c')]", $listing);
$rating = $ratingNodes->length > 0 ? trim($ratingNodes->item(0)->nodeValue) : "N/A";
// Extracting price range
$priceRangeNodes = $xpath->query(".//span[contains(@class, 'priceRange__09f24__mmOuH')]", $listing);
$priceRange = $priceRangeNodes->length > 0 ? trim($priceRangeNodes->item(0)->nodeValue) : "N/A";
// Extracting number of reviews and location
$spanElements = $xpath->query(".//span[contains(@class, 'css-chan6m')]", $listing);
$numReviews = "N/A";
$location = "N/A";
if ($spanElements->length >= 2) {
$numReviews = trim($spanElements->item(0)->nodeValue);
$location = trim($spanElements->item(1)->nodeValue);
} elseif ($spanElements->length == 1) {
$text = trim($spanElements->item(0)->nodeValue);
if (is_numeric($text)) {
$numReviews = $text;
} else {
$location = $text;
}
}
// Output extracted information
echo "Business Name: $businessName" . PHP_EOL;
echo "Rating: $rating" . PHP_EOL;
echo "Number of Reviews: $numReviews" . PHP_EOL;
echo "Price Range: $priceRange" . PHP_EOL;
echo "Location: $location" . PHP_EOL;
echo str_repeat("=", 30) . PHP_EOL;
}
} else {
echo "Failed to retrieve data. Status Code: " . $httpcode . PHP_EOL;
}
?>