What is Httpbin?
Httpbin is a popular online service that provides a simple HTTP request & response service for testing and debugging HTTP libraries and clients. Some key things you can do with httpbin:
It is used by developers testing HTTP client code, those experimenting with API requests, and anyone wanting a quick public HTTP service to interact with.
Here are some of the key scenarios where httpbin is useful:
Testing HTTP Client Code
Since httpbin provides a simple HTTP service, it's extremely useful for testing code that makes HTTP requests like:
You can test making GET, POST requests, custom headers, status codes etc.
Experimenting with APIs
httpbin allows you to prototype and experiment with APIs quickly without needing to set up a server. You can shape any JSON response, get common status codes, test auth easily. Helpful when exploring integrations or trying things out.
Learning HTTP
httpbin exposes all major features of HTTP protocol like methods, headers, redirection, caching etc. So its a great tool when learning core HTTP concepts or tools like cURL and requests modules in various languages. Lets you try things easily.
Debugging Issues
If you face an issues with HTTP requests in your application like headers not reaching, redirects looping, auth failures etc, httpbin can help debug and identify the root cause quickly.
Documentation Samples
When writing docs for an API client/library, httpbin provides great sample requests and responses to demonstrate usage. Saves having to mock things up.
CI/Testing
httpbin endpoints can be leveraged in CI pipelines and test suits to validate HTTP connectivity and perform protocol level integration tests.
So basically anytime you need a freely hosted HTTP test server, httpbin delivers that and helps test and debug all components related to HTTP clients and servers.
How is it useful in web scraping/ web crawling?
httpbin is extremely helpful when working on web scraping projects. Here are some specific use cases:
Testing Crawlers & Parsers
Since httpbin provides endpoints that return HTML, XML, JSON responses - you can leverage it to unit test scrapers, parsers, DOM traversal code without needing a live site. Allows testing core scraping logic in isolation.
response = requests.get('<http://httpbin.org/html>')
html = response.text
# parse and extract data from html

Experimenting with Target Sites
You can shape mock responses similar to the target site you want to scrape using custom headers, status codes, response formats. Helps build robust scrapers.
headers = {'Content-Type': 'text/html; charset=utf-8'}
response = requests.get('<http://httpbin.org/response-headers>',
headers=headers)
html = response.text
for example, my Chrome produces this…
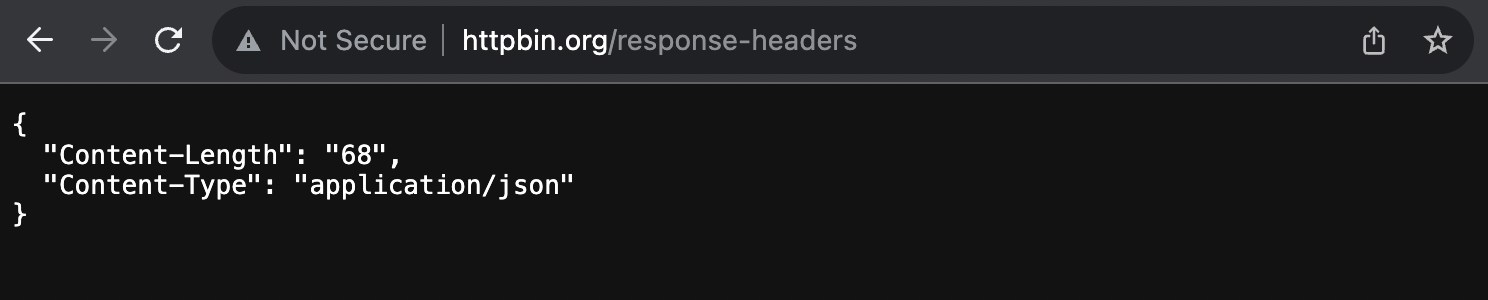
Testing Proxy Configurations
httpbin provides an endpoint /ip that returns Origin IP address. Useful for testing scraping through different proxies to validate they are configured correctly:
response = requests.get('<http://httpbin.org/ip>', proxies=proxy)
origin_ip = response.json()['origin']
print(origin_ip)
Debugging Intermittent Issues
Web scrapers often face intermittent issues like blocked IPs, connectivity issues etc. httpbin provides endpoints to help replicate and tests these scenarios in a controlled way during development.
Httpbin Functions CheatSheet
Making Requests
To make requests to httpbin endpoints, you need to use the
import requests
response = requests.get('<https://httpbin.org/get>')
print(response.text)
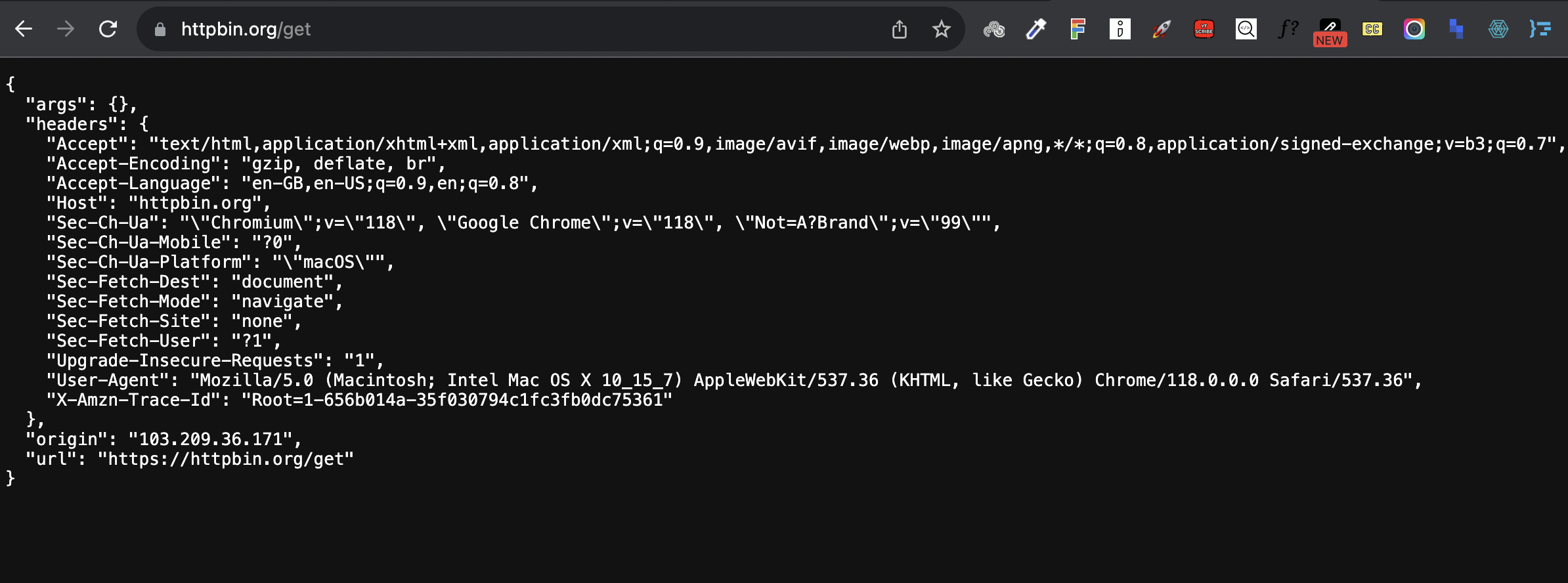
/get
The
import requests
data = {'key1': 'value1', 'key2': 'value2'}
response = requests.get('<https://httpbin.org/get>', params=data)
print(response.json())
# Response contains the data dictionary
You can test adding headers, authentication, proxies and more.
/post
The
import json
import requests
data = {'name': 'John'}
headers = {'Content-type': 'application/json'}
response = requests.post('<https://httpbin.org/post>',
data=json.dumps(data), headers=headers)
print(response.json())
/status
The
import requests
response = requests.get('<https://httpbin.org/status/201>')
print(response.status_code) # 201
print(response.json)
/response-headers
The
import requests
headers = {'custom': 'header'}
response = requests.get('<https://httpbin.org/response-headers>', headers=headers)
print(response.json()['headers']['Custom']) # 'header'
/basic-auth
The
import requests
response = requests.get('<https://httpbin.org/basic-auth/user/passwd>',
auth=('user', 'passwd'))
print(response.json())
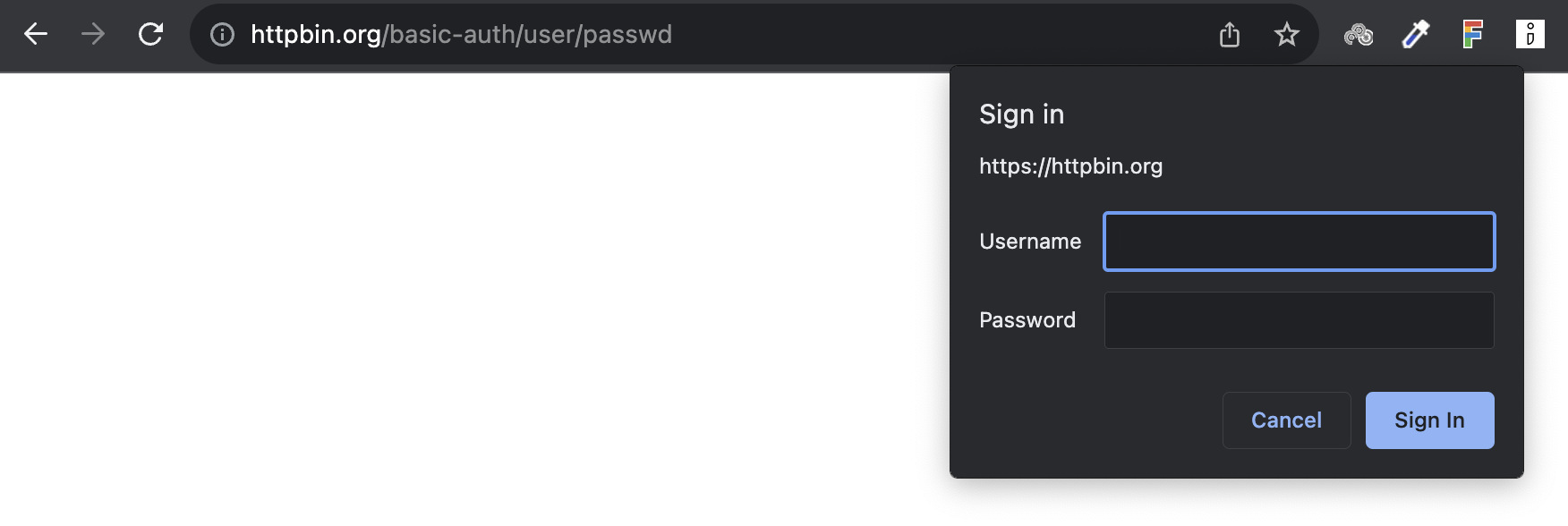
/digest-auth
The
import requests
from requests.auth import HTTPDigestAuth
response = requests.get('<https://httpbin.org/digest-auth/auth/user/passwd>',
auth=HTTPDigestAuth('user', 'passwd'))
print(response.status_code)
/delay
The
import requests
response = requests.get('<https://httpbin.org/delay/3>') # delays for 3 seconds
print(response.json())
/drip
The
import requests
response = requests.get('<https://httpbin.org/drip?duration=5&numbytes=100&code=200>')
for data in response.iter_content(100):
print(data) # prints 100 bytes every 5 seconds
This is fun to try in your browser. Notice how the download moves ahead every few seconds
/range
The
import requests
response = requests.get('<https://httpbin.org/range/10>', headers={'Range': 'bytes=0-9'})
print(response.text) # prints first 10 bytes
/deny
The
import requests
response = requests.get('<https://httpbin.org/deny>')
print(response.status_code) # 401 Unauthorized
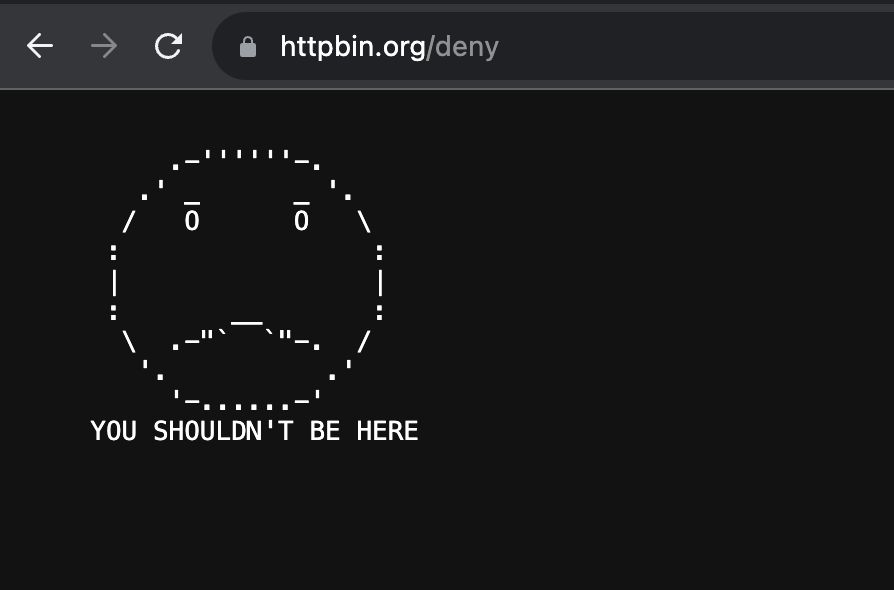
/redirect
The
import requests
response = requests.get('<https://httpbin.org/redirect/1>')
print(response.history[0].status_code) # 302 Found
print(response.url) # Redirected URL
/relative-redirect
The
import requests
response = requests.get('<https://httpbin.org/relative-redirect/6>')
print(response.history[0].status_code) # 302 Found
print(response.url) # Current URL after redirect
/cookies
The
import requests
cookies = {'test': 'cookie'}
response = requests.get('<https://httpbin.org/cookies>', cookies=cookies)
print(response.json()) # Contains cookie data
/set-cookie
The
import requests
response = requests.get('<https://httpbin.org/cookies/set?name=value>')
print(response.headers['Set-Cookie'])
/delete-cookies
The
import requests
cookies = {'test': 'cookie'}
response = requests.get('<https://httpbin.org/cookies>', cookies=cookies)
response = requests.get('<https://httpbin.org/cookies/delete?test>')
print(response.json()) # test cookie deleted
/headers
The
import requests
headers = {'user-agent': 'my-test-app'}
response = requests.get('<https://httpbin.org/headers>', headers=headers)
print(response.json()["headers"])
/user-agent
The
import requests
headers = {'user-agent': 'Mozilla/5.0 (Linux; Android 6)'}
response = requests.get('<https://httpbin.org/user-agent>', headers=headers)
print(response.json()["user-agent"]) # Details parsed from header

/gzip
The
import requests
response = requests.get('<https://httpbin.org/gzip>')
print(response.headers["Content-Encoding"]) # gzip
print(response.text) # Decompressed text
/deflate
The
import requests
response = requests.get('<https://httpbin.org/deflate>')
print(response.headers["Content-Encoding"]) # deflate
print(response.text) # Decompressed text
/brotli
The
import requests
response = requests.get('<https://httpbin.org/brotli>')
print(response.headers["Content-Encoding"]) # br
print(response.text) # Decompressed text
/stream
The
import requests
response = requests.get('<https://httpbin.org/stream/10>', stream=True)
for line in response.iter_lines():
print(line.decode('utf-8')) # Parses and prints json
/html
The
import requests
response = requests.get('<https://httpbin.org/html>')
print(response.text[:15]) # '<!DOCTYPE html>'
print(response.headers["Content-Type"]) # 'text/html'
/robots.txt
The
import requests
response = requests.get('<https://httpbin.org/robots.txt>')
print(response.text)
/deny
You can test various http response status codes:
import requests
response = requests.get('<https://httpbin.org/status/404>')
print(response.status_code) # 404
response = requests.get('<https://httpbin.org/status/403>')
print(response.status_code) # 403
response = requests.get('<https://httpbin.org/status/500>')
print(response.status_code) # 500
response = requests.get('<https://httpbin.org/status/504>')
print(response.status_code) # 504
Response Inspection
You can inspect the raw response including:
import requests
response = requests.get('<https://httpbin.org/get>')
print(response.content) # Raw bytes
print(response.encoding) # Encoding
print(response.is_redirect) # Is redirect response
print(response.is_permanent_redirect)
print(response.apparent_encoding) # Apparent encoding
print(response.history) # Redirect history
Advanced Usage
Authentication
Different auth protocols require dedicated code flows:
# Basic Auth
response = requests.get(url, auth=('user', 'pass'))
# Digest Auth
auth = HTTPDigestAuth('user', 'pass')
response = requests.get(url, auth=auth)
# OAuth 1.0
import oauthlib
from requests_oauthlib import OAuth1
oauth = OAuth1(client_key, client_secret, resource_owner_key, resource_owner_secret)
response = requests.get(url, auth=oauth)
Cookies, Sessions
Use a session to persist cookies across requests:
session = requests.Session()
session.get(url1) # cookies saved for url2
resp = session.get(url2)
Proxies
Specify HTTP, SOCKS proxies:
proxies = {'http': '<http://1.2.3.4:5678>'}
requests.get(url, proxies=proxies)
Use proxy auth:
proxies = {'http': 'user:pass@1.2.3.4'}
requests.get(url, proxies=proxies)
Error Handling
Catch and recover from specific errors:
try:
response = requests.get(url)
response.raise_for_status()
except requests.exceptions.HTTPError as err:
# Handle HTTP error
except requests.exceptions.Timeout:
# Retry after timeout
Set timeouts to avoid hanging:
requests.get(url, timeout=3)
Debugging
Inspect request details:
import logging
logging.basicConfig(level=logging.DEBUG)
requests.get(url)
# -> logs request method, path, headers, body
Use a proxy like Fiddler to capture traffic.
Example Use Cases
Test API Client Module
Httpbin provides an excellent way to test API client code without relying on actual production backends. For example:
import appapi
import requests
# Test authentication
response = requests.get("<https://httpbin.org/basic-auth/user/passwd>",
auth=("user", "passwd"))
assert response.status_code == 200
# Mock client module method
appapi.get_user = lambda x: requests.get("<https://httpbin.org/anything>")
response = appapi.get_user(123)
assert b'"httpbin"' in response.content
Here httpbin acts as a dummy API that can return realistic response codes and payloads to validate the client module works as expected, without needing real implementations on the server side.
We can take advantage of endpoints like:
To stand-in for actual APIs the client code will interact with.
Identify Security Issues
The httpbin service provides ways to detect security anti-patterns:
import requests
# Test for SQL injection
payload = "' OR 1=1--"
response = requests.post("<https://httpbin.org/post>",
data={"username": payload})
# If API is vulnerable, might see database errors
if b'error' not in response.content:
print("SQL Injection vulnerability detected")
# Test overflow with long string
long_str = "A"*5000
requests.post("<https://httpbin.org/post>", data=long_str)
Here we can send intentional malicious payloads designed to trigger exceptions and unstable behavior that indicate problems like SQLi, buffer overflows etc.
Since httpbin simply echoes back the request, it allows testing the actual API backend in an isolated way.
Tooling and Libraries
Requests
Popular HTTP client with options like:
Httpx - AsyncRequests analogue
Features like Requests plus:
import httpx
async with httpx.AsyncClient() as client:
resp = await client.get(url)
PyRESTTest - Declarative REST API Testing
Test cases specified in YAML:
- test:
name: Get user
url: /api/users
method: GET
headers:
Auth: abc123
validators:
- compare: {header: Content-Type, expected: application/json}
- compare: {jsonpath_mini: .id, expected: 123}
Similar Services
Here are some useful links for some services similar to httpbin:
JSONPlaceholder
JSONPlaceholder provides a fake REST API for testing without needing real backends.
Example usage:
<https://jsonplaceholder.typicode.com/posts/1>
# Returns fake post data
WireMock
WireMock allows stubbing and mocking web services for testing how code handles different scenarios and responses.
Example usage:
stubFor(get(urlEqualTo("/api/user"))
.willReturn(aResponse()
.withStatus(500))
);
Mocky
Mocky provides a simple way to mock APIs by returning static or dynamic JSON data.
Example usage:
<https://run.mocky.io/v3/{{guuid}>}
# Returns dynamic guid value