Google Scholar is an invaluable resource for researching academic publications across disciplines. However, sometimes you need to extract information from Google Scholar programmatically for analysis or further processing. That's where web scraping comes in!
This is the Google Scholar result page we are talking about…
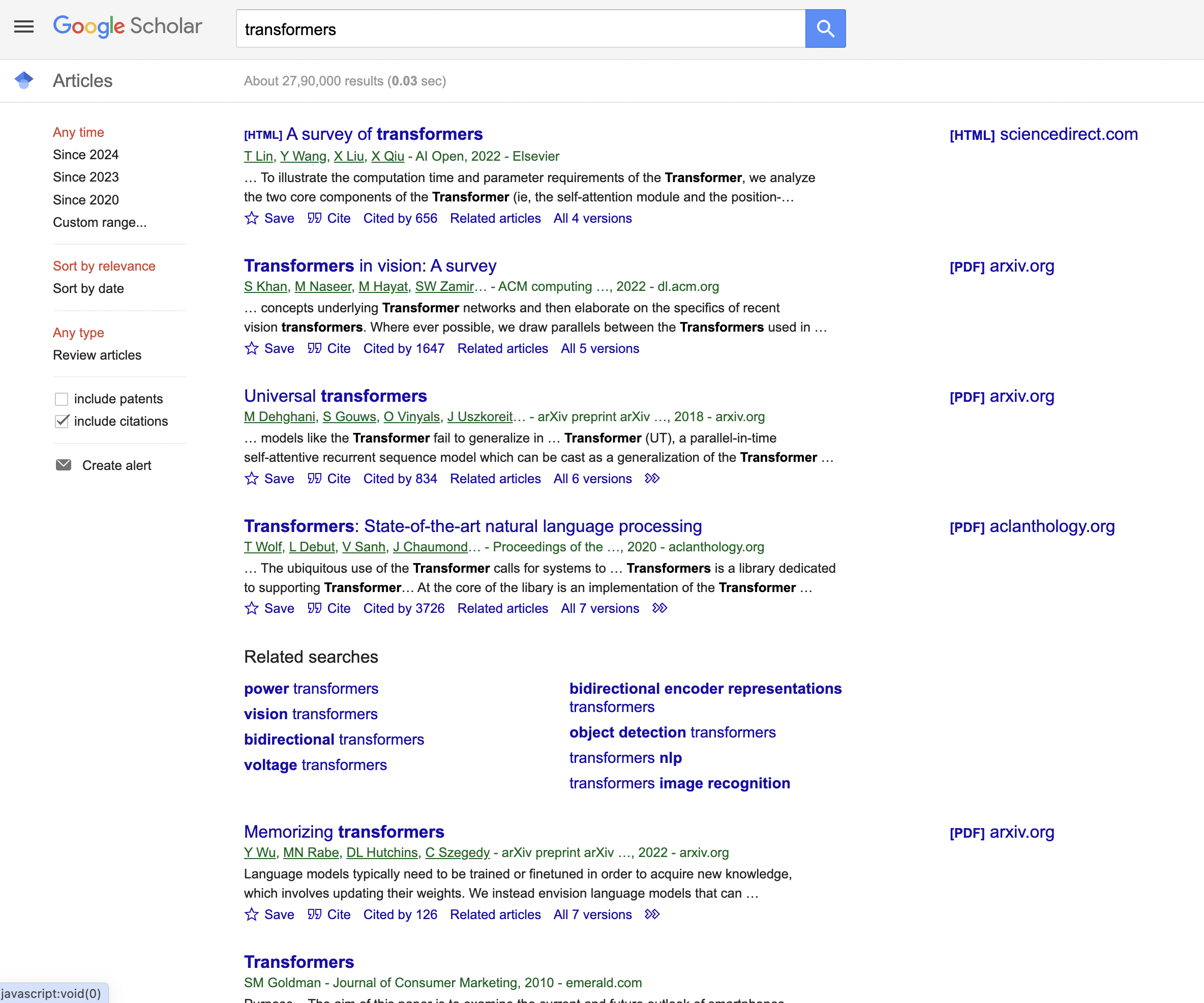
Web scraping uses code to automatically extract data from websites. In this article, we'll explore a complete iOS example for scraping key fields from Google Scholar search results.
Even with no prior web scraping experience, you'll learn:
So let's get scraping!
Setting Up the Scraper
We'll utilize native iOS frameworks to handle fetching and parsing. First we need a few imports:
#import <Foundation/Foundation.h>
#import <libxml/HTMLParser.h>
The
Next we define a custom class
@interface ScholarResult : NSObject
@property (nonatomic, strong) NSString *title;
@property (nonatomic, strong) NSString *url;
@property (nonatomic, strong) NSString *authors;
@property (nonatomic, strong) NSString *abstract;
@end
Each search result will be represented by an instance of
We also need a handler class to act as the parser delegate:
@interface ScholarParser : NSObject <NSXMLParserDelegate>
@property (nonatomic, strong) NSMutableArray<ScholarResult *> *results;
@property (nonatomic, strong) ScholarResult *currentResult;
@property (nonatomic, strong) NSMutableString *currentElementValue;
@end
Key properties:
The parser delegate methods will do the actual data extraction work.
Constructing the Request
To retrieve the Google Scholar HTML, we need to send a properly formatted request:
// Define URL
NSString *urlString = @"<https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=transformers&btnG=>";
// User-Agent header
NSString *userAgent = @"Mozilla/5.0...";
// Create NSURL
NSURL *url = [NSURL URLWithString:urlString];
// Create request
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
// Set User-Agent header
[request setValue:userAgent forHTTPHeaderField:@"User-Agent"];
Key aspects:
We could parameterize the search query, but hardcoding serves our example well.
Important: Google expects a proper user agent header. Passing a web browser's user agent helps avoid bot detection.
Now that preparation is complete, we can actually fetch the search results page by sending the request!
Fetching and Parsing the Response
To retrieve and parse Google's response, we leverage
// Send request & get response
NSURLSession *session = [NSURLSession sharedSession];
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
// Handle data
}];
[dataTask resume];
[session finishTasksAndInvalidate];
[[NSRunLoop currentRunLoop] run];
This asynchronously sends our request and executes the completion handler when the full response
With the raw HTML
// Parse HTML
ScholarParser *parser = [[ScholarParser alloc] init];
NSXMLParser *xmlParser = [[NSXMLParser alloc] initWithData:data];
xmlParser.delegate = parser;
[xmlParser parse];
Feeding the response data into
This is where the magic happens! ???? The delegate methods will find and extract fields of interest.
Extracting Paper Details with XPath Selectors
Inspecting the code
You can see that the items are enclosed in a The key is crafting XPath selectors to pinpoint elements containing the data we want. For example, title lives inside Let's break down selector logic to extract titles: Whenever an Similar logic applies for other fields like URL, authors, and abstract. Key delegate methods: This handles: Through carefully crafted selectors, we extract all needed data! With each result extracted, we add it to the overall results array: By the end, We could analyze these programmatically, display them in an app, save to a database, etc. The possibilities are endless! This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html>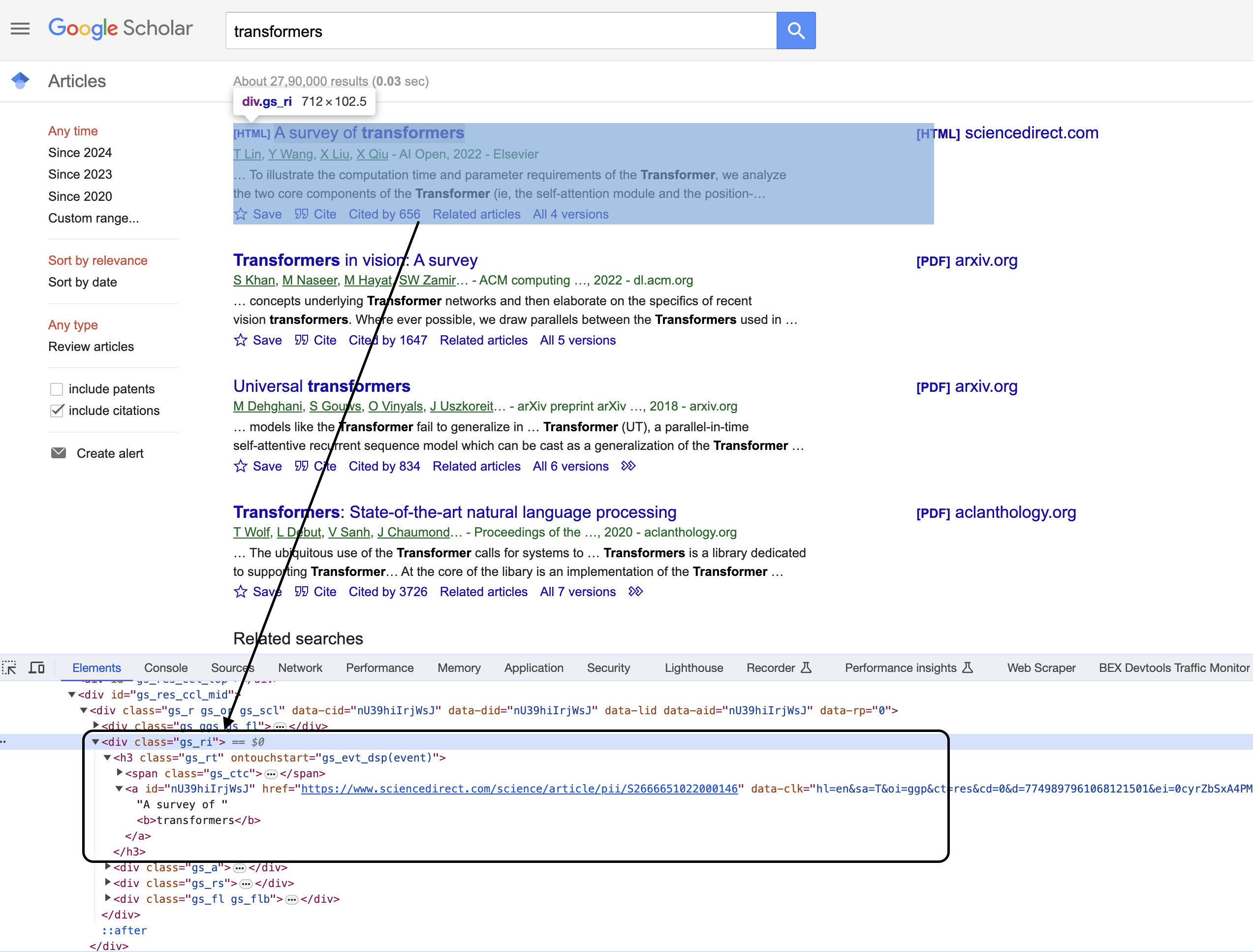
<h3>Attention Is All You Need</h3>
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName {
if ([elementName isEqualToString:@"h3"]) {
// Set title on current result
self.currentResult.title = self.currentElementValue;
}
}
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName {
// Initialize current result when start new search result
if ([elementName isEqualToString:@"div"] && div.class == "gs_ri") {
self.currentResult = [[ScholarResult alloc] init];
}
// Reset current element value
self.currentElementValue = [NSMutableString string];
}
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string {
[self.currentElementValue appendString:string];
}
Storing Results
- (void)parser:(NSXMLParser *)parser didEndElement: {
// After all fields populated:
if ([elementName isEqual:@"div"] && div.class == "gs_ri") {
[self.results addObject:self.currentResult];
self.currentResult = nil; // Reset
}
}
Putting It All Together
#import <Foundation/Foundation.h>
#import <libxml/HTMLParser.h>
// Create custom class to store result data
@interface ScholarResult : NSObject
@property (nonatomic, strong) NSString *title;
@property (nonatomic, strong) NSString *url;
@property (nonatomic, strong) NSString *authors;
@property (nonatomic, strong) NSString *abstract;
@end
@implementation ScholarResult
@end
@interface ScholarParser : NSObject <NSXMLParserDelegate>
@property (nonatomic, strong) NSMutableArray<ScholarResult *> *results;
@property (nonatomic, strong) ScholarResult *currentResult;
@property (nonatomic, strong) NSMutableString *currentElementValue;
@end
@implementation ScholarParser
- (instancetype)init {
self = [super init];
if (self) {
self.results = [NSMutableArray array];
}
return self;
}
- (void)parserDidStartDocument:(NSXMLParser *)parser {
NSLog(@"Parsing started.");
}
- (void)parserDidEndDocument:(NSXMLParser *)parser {
NSLog(@"Parsing finished.");
for (ScholarResult *result in self.results) {
NSLog(@"Title: %@", result.title);
NSLog(@"URL: %@", result.url);
NSLog(@"Authors: %@", result.authors);
NSLog(@"Abstract: %@", result.abstract);
NSLog(@"-------------------------------------------------");
}
}
- (void)parser:(NSXMLParser *)parser didStartElement:(NSString *)elementName namespaceURI:(nullable NSString *)namespaceURI qualifiedName:(nullable NSString *)qName attributes:(NSDictionary<NSString *, NSString *> *)attributeDict {
if ([elementName isEqualToString:@"div"] && [attributeDict[@"class"] isEqualToString:@"gs_ri"]) {
self.currentResult = [[ScholarResult alloc] init];
}
self.currentElementValue = [NSMutableString string];
}
- (void)parser:(NSXMLParser *)parser foundCharacters:(NSString *)string {
[self.currentElementValue appendString:string];
}
- (void)parser:(NSXMLParser *)parser didEndElement:(NSString *)elementName namespaceURI:(nullable NSString *)namespaceURI qualifiedName:(nullable NSString *)qName {
if (self.currentResult) {
if ([elementName isEqualToString:@"h3"] && [self.currentElementValue length] > 0) {
self.currentResult.title = self.currentElementValue;
} else if ([elementName isEqualToString:@"a"] && [self.currentElementValue length] > 0) {
self.currentResult.url = self.currentElementValue;
} else if ([elementName isEqualToString:@"div"] && [attributeDict[@"class"] isEqualToString:@"gs_a"] && [self.currentElementValue length] > 0) {
self.currentResult.authors = self.currentElementValue;
} else if ([elementName isEqualToString:@"div"] && [attributeDict[@"class"] isEqualToString:@"gs_rs"] && [self.currentElementValue length] > 0) {
self.currentResult.abstract = self.currentElementValue;
}
}
if ([elementName isEqualToString:@"div"] && [attributeDict[@"class"] isEqualToString:@"gs_ri"]) {
[self.results addObject:self.currentResult];
self.currentResult = nil;
}
}
@end
int main(int argc, const char * argv[]) {
@autoreleasepool {
// Define the URL of the Google Scholar search page
NSString *urlString = @"https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=transformers&btnG=";
// Define a User-Agent header
NSString *userAgent = @"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36"; // Replace with your User-Agent string
// Create an NSURL object from the URL string
NSURL *url = [NSURL URLWithString:urlString];
// Create an NSMutableURLRequest with the URL
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url];
// Set the User-Agent header
[request setValue:userAgent forHTTPHeaderField:@"User-Agent"];
// Send a GET request to the URL with the User-Agent header
NSURLSession *session = [NSURLSession sharedSession];
NSURLSessionDataTask *dataTask = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
if (error) {
NSLog(@"Failed to retrieve the page. Error: %@", error.localizedDescription);
return;
}
// Parse the HTML content of the page using NSXMLParser
ScholarParser *parser = [[ScholarParser alloc] init];
NSXMLParser *xmlParser = [[NSXMLParser alloc] initWithData:data];
xmlParser.delegate = parser;
[xmlParser parse];
}];
[dataTask resume];
[session finishTasksAndInvalidate];
[[NSRunLoop currentRunLoop] run];
}
return 0;
}curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...