In this beginner-friendly PHP tutorial, we will walk through a full web scraping script to extract search results data from Google Scholar. We won't get into the high-level details or ethics of web scraping - instead we'll jump straight into the code and I'll explain each part in detail.
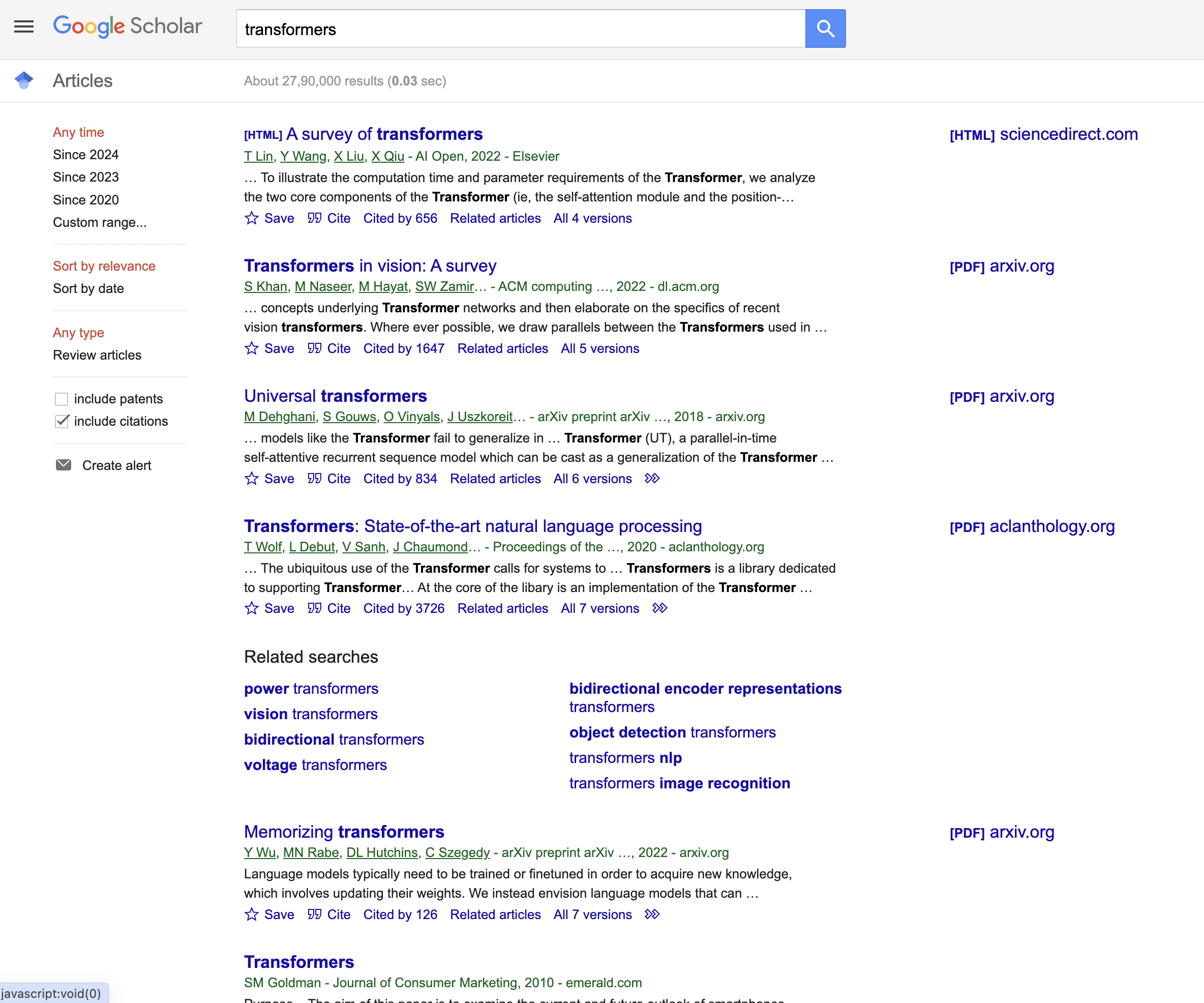
This is the Google Scholar result page we are talking about…
Pre-requisites
Before running the web scraping script, you need to have:
PHP Engine
PHP 7.0+ is required. This should be installed on most shared hosts. For local testing, install XAMPP or similar which includes the PHP engine.
Simple HTML DOM Parser
We use this excellent PHP library to parse and interact with HTML and XML documents.
Download simple_html_dom.php from: https://simplehtmldom.sourceforge.io/
And add it to your PHP project directory.
With those set up, let's get into the scraper!
Overview
Here is a high-level overview of what the script does:
- Imports Simple HTML DOM library
- Defines URL to scrape and headers
- Initializes cURL and sets options
- Makes request and gets HTML response
- Checks response is valid
- Parses HTML into a DOM document
- Uses DOM selectors to extract data
- Outputs extracted data
- Cleans up
Now let's walk through it section-by-section.
Import Simple HTML DOM
include('simple_html_dom.php');
We include the Simple HTML DOM parser library so we can easily interact with DOM elements later.
Define Target URL and Headers
// Define the URL of the Google Scholar search page
$url = "<https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=transformers&btnG=>";
// Define a User-Agent header
$headers = [
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36',
];
We define the target URL to scrape - a Google Scholar search for "transformers".
And add a user-agent header to mimic a real browser, avoiding bot detection.
Initialize cURL Session
// Initialize cURL session
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
cURL allows making HTTP requests in PHP. We initialize a new cURL session, then configure our options:
Send Request and Check Response
// Execute cURL session and get the response
$response = curl_exec($ch);
// Check if the request was successful (status code 200)
if ($response !== false) {
// Scrape page
} else {
// Request failed
}
We execute the cURL request and store the resulting HTML content.
It's good practice to check the response is valid before trying to parse/scrape it.
Parse Response and Extract Data
Inspecting the code
You can see that the items are enclosed in a This is the key part - using Simple HTML DOM to interact with DOM elements and extract information. First we pass the HTML response into Simple HTML DOM, which parses it into a DOM document we can query. We find all We loop through the search result The data is outputted, giving the title, URL, authors and abstract for each search result. Finally we free resources and close cURL to avoid issues. And that wraps up the key parts of our Google Scholar scraper! Let's see the full code. Here is the complete script to scrape Google Scholar search results in PHP: This is great as a learning exercise but it is easy to see that even the proxy server itself is prone to get blocked as it uses a single IP. In this scenario where you may want a proxy that handles thousands of fetches every day using a professional rotating proxy service to rotate IPs is almost a must. Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms. Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly. Hundreds of our customers have successfully solved the headache of IP blocks with a simple API. The whole thing can be accessed by a simple API like below in any programming language. In fact, you don't even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so: We have a running offer of 1000 API calls completely free. Register and get your free API Key.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key:
// Create a new instance of the Simple HTML DOM Parser
$html = str_get_html($response);
// Find all the search result blocks with class "gs_ri"
$search_results = $html->find('div.gs_ri');
// Loop through each search result block and extract information
foreach ($search_results as $result) {
// Extract the title and URL
$title_elem = $result->find('h3.gs_rt', 0);
$title = $title_elem ? $title_elem->plaintext : "N/A";
$url = $title_elem ? $title_elem->find('a', 0)->href : "N/A";
// Extract the authors
$authors_elem = $result->find('div.gs_a', 0);
$authors = $authors_elem ? $authors_elem->plaintext : "N/A";
// Extract the abstract
$abstract_elem = $result->find('div.gs_rs', 0);
$abstract = $abstract_elem ? $abstract_elem->plaintext : "N/A";
// Output extracted info
echo "Title: " . $title . "\\n";
echo "URL: " . $url . "\\n";
echo "Authors: " . $authors . "\\n";
echo "Abstract: " . $abstract . "\\n";
}
Cleanup
// Clean up resources
$html->clear();
unset($html);
// Close cURL session
curl_close($ch);
Full PHP Web Scraping Script
<?php
// Include the PHP Simple HTML DOM Parser library
include('simple_html_dom.php');
// Define the URL of the Google Scholar search page
$url = "https://scholar.google.com/scholar?hl=en&as_sdt=0%2C5&q=transformers&btnG=";
// Define a User-Agent header
$headers = [
'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36', // Replace with your User-Agent string
];
// Initialize cURL session
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// Execute cURL session and get the response
$response = curl_exec($ch);
// Check if the request was successful (status code 200)
if ($response !== false) {
// Create a new instance of the Simple HTML DOM Parser
$html = str_get_html($response);
// Find all the search result blocks with class "gs_ri"
$search_results = $html->find('div.gs_ri');
// Loop through each search result block and extract information
foreach ($search_results as $result) {
// Extract the title and URL
$title_elem = $result->find('h3.gs_rt', 0);
$title = $title_elem ? $title_elem->plaintext : "N/A";
$url = $title_elem ? $title_elem->find('a', 0)->href : "N/A";
// Extract the authors and publication details
$authors_elem = $result->find('div.gs_a', 0);
$authors = $authors_elem ? $authors_elem->plaintext : "N/A";
// Extract the abstract or description
$abstract_elem = $result->find('div.gs_rs', 0);
$abstract = $abstract_elem ? $abstract_elem->plaintext : "N/A";
// Print the extracted information
echo "Title: " . $title . "\n";
echo "URL: " . $url . "\n";
echo "Authors: " . $authors . "\n";
echo "Abstract: " . $abstract . "\n";
echo str_repeat("-", 50) . "\n"; // Separating search results
}
// Clean up resources
$html->clear();
unset($html);
// Close cURL session
curl_close($ch);
} else {
echo "Failed to retrieve the page. Error: " . curl_error($ch);
}
?>curl "<http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com>"
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!