Web scraping allows you to automatically extract data from websites - it's useful for collecting large volumes of data for analysis. Here we'll scrape article titles and links from the New York Times homepage.
Prerequisites
Before scraping any site, we need:
You can install these in Windows, Linux or MacOS environments.
Walkthrough
Here's how the NYTimes scraper works:
First we
require 'net/http'
require 'nokogiri'
Next we set the target URL to scrape:
url = '<https://www.nytimes.com/>'
We define a user agent header that mimics a browser's request - this helps avoid getting blocked:
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
Using
response = Net::HTTP.get_response(URI(url), headers)
We check if the request was successful via the status code:
if response.code == "200"
If good, we parse the HTML using Nokogiri:
doc = Nokogiri::HTML(response.body)
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
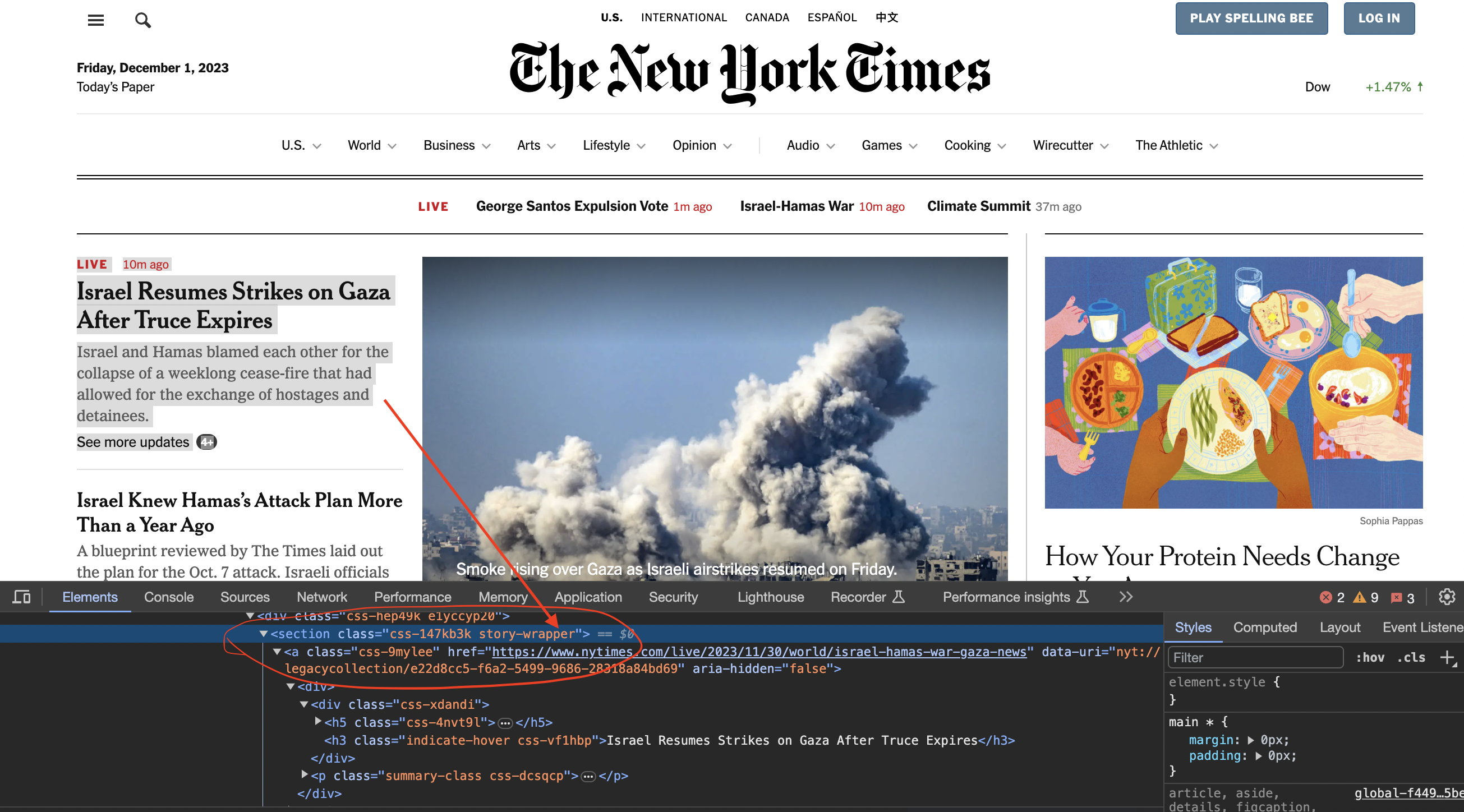
We grab article sections using a CSS selector:
article_sections = doc.css('section.story-wrapper')
Within these, we find titles and links via more selectors:
title_element = article_section.at_css('h3.indicate-hover')
link_element = article_section.at_css('a.css-9mylee')
If found, we extract and store them:
article_titles << article_title
article_links << article_link
Finally, we print the scraped data:
article_titles.zip(article_links).each do |title, link|
puts "Title: #{title}"
puts "Link: #{link}"
end
And that's the gist of how this scraper works!
Here is the full code
require 'net/http'
require 'nokogiri'
# URL of The New York Times website
url = 'https://www.nytimes.com/'
# Define a user-agent header to simulate a browser request
headers = {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
# Send an HTTP GET request to the URL
response = Net::HTTP.get_response(URI(url), headers)
# Check if the request was successful (status code 200)
if response.code == "200"
# Parse the HTML content of the page
doc = Nokogiri::HTML(response.body)
# Find all article sections with class 'story-wrapper'
article_sections = doc.css('section.story-wrapper')
# Initialize lists to store the article titles and links
article_titles = []
article_links = []
# Iterate through the article sections
article_sections.each do |article_section|
# Check if the article title element exists
title_element = article_section.at_css('h3.indicate-hover')
# Check if the article link element exists
link_element = article_section.at_css('a.css-9mylee')
# If both title and link are found, extract and append
if title_element && link_element
article_title = title_element.text.strip
article_link = link_element['href']
article_titles << article_title
article_links << article_link
end
end
# Print or process the extracted article titles and links
article_titles.zip(article_links).each do |title, link|
puts "Title: #{title}"
puts "Link: #{link}"
puts
end
else
puts "Failed to retrieve the web page. Status code: #{response.code}"
endPractical Considerations
Handling errors - We check for status codes and handles cases where page wasn't retrieved properly.
Adaptability - The CSS selectors could be tweaked to scrape other parts of articles.
Blocking - Rotating user agents helps avoid getting blocked by sites.
Legalities - Do check a website's terms before scraping to avoid issues!
Key Takeways
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.