Web scraping is the process of extracting data from websites automatically. In this article, we'll walk through code that scrapes article titles and links from the New York Times homepage using Node.js modules like request and cheerio.
Why Scrape the New York Times?
The New York Times publishes tons of high-quality content every day on topics like news, opinion, arts, living, and more. Scraping the site allows you to extract and store this content to power other applications. For example, you could:
The possibilities are vast once you have structured data from a site like The Times!
Step 1: Import Needed Modules
Let's walk through the code section-by-section. First we import the modules we'll need:
const request = require('request'); // for sending HTTP requests
const cheerio = require('cheerio'); // for selecting/parsing HTML
const fs = require('fs'); // for writing to the filesystem
We use the request module to send the HTTP request to fetch the Times homepage.
Cheerio allows us to select elements in the HTML of the page, kind of like jQuery.
The fs module is used at the end for writing the scraped data to a JSON file.
Step 2: Define the URL and Request Options
Next we set the URL to scrape and define some options for our HTTP request:
// NYTimes URL
const url = '<https://www.nytimes.com/>';
// Request settings
const options = {
url: url,
headers: {
'User-Agent': 'Mozilla/5.0'
}
};
Here we are scraping the main nytimes.com homepage URL.
We also set a custom User-Agent header to mimic a real web browser, which prevents getting blocked as a bot.
Step 3: Send the Request and Load HTML
With our URL and options defined, we use request to grab the page HTML:
// Send request
request(options, (err, res, html) => {
// Load HTML
let $;
try {
$ = cheerio.load(html);
} catch(err) {
console.log('Cheerio error:', err);
return;
}
We pass our options to request and provide a callback to handle the response.
Inside, we use cheerio's load method to parse the HTML string into a Cheerio object that we can query (stored in $).
This gives us jQuery-style selectors to extract data.
Step 4: Define Variables and Select Elements
Now that we have the page loaded, we can start extracting the data we want - article titles and links:
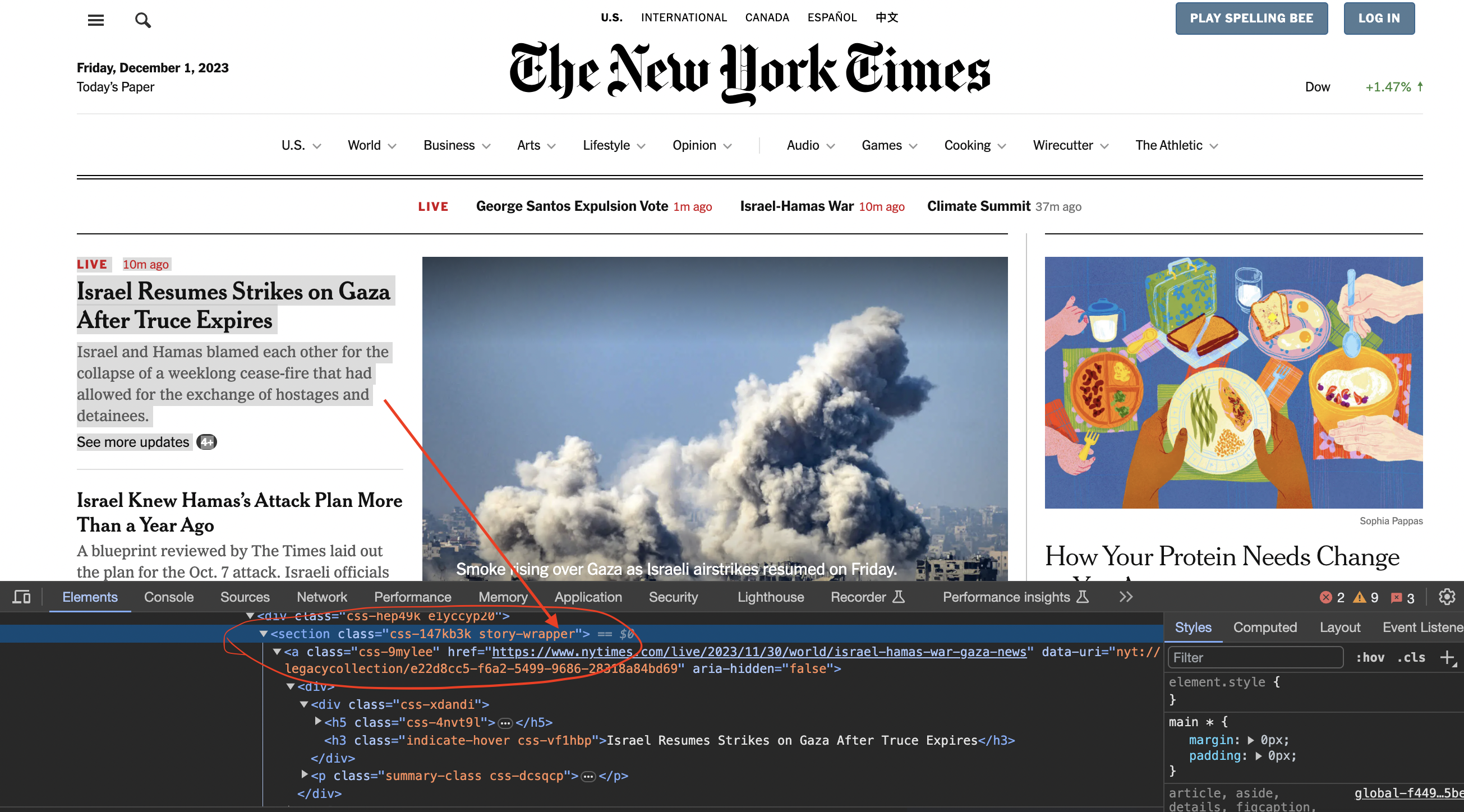
Inspecting the page
We now inspect element in chrome to see how the code is structured…
You can see that the articles are contained inside section tags and with the class story-wrapper
// Initialize variables
let titles = [];
let links = [];
// Select articles
$('section.story-wrapper').each(function() {
// Get data
const title = $(this).find('h3').text().trim();
const link = $(this).find('a').attr('href');
// Validate
if (!title || !link) {
return;
}
// Save data
titles.push(title);
links.push(link);
});
First we define some arrays to store the info we scrape.
We select all
We do some validation to make sure we have valid content before saving to our arrays.
Step 5: Log and Store the Scraped Data
With our titles and links arrays populated, we wrap up by logging and storing the data:
// Check no articles
if (titles.length === 0) {
console.log('No articles found');
return;
}
// Log articles
titles.forEach((title, i) => {
console.log('Title:', title);
console.log('Link:', links[i]);
console.log();
});
// Write to file
fs.writeFileSync('articles.txt', JSON.stringify({ titles, links }));
First we make sure we actually captured articles by checking the length.
Then we log each title/link pair in the console so you can validate it worked.
Finally, we use fs to write the data to a JSON file for later use.
And that's it! Here is the full code for reference:
// Import modules
const request = require('request');
const cheerio = require('cheerio');
const fs = require('fs');
// NYTimes URL
const url = 'https://www.nytimes.com/';
// Request settings
const options = {
url: url,
headers: {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
};
// Send request
request(options, (err, res, html) => {
// Check errors
if (err) {
console.log('Error:', err);
return;
}
if(res.statusCode !== 200) {
console.log('Status:', res.statusCode);
return;
}
// Load HTML
let $;
try {
$ = cheerio.load(html);
} catch(err) {
console.log('Cheerio error:', err);
return;
}
// Initialize variables
let titles = [];
let links = [];
// Select articles
$('section.story-wrapper').each(function() {
// Get data
const title = $(this).find('h3').text().trim();
const link = $(this).find('a').attr('href');
// Validate
if (!title || !link) {
return;
}
// Save data
titles.push(title);
links.push(link);
});
// Check if no articles
if (titles.length === 0) {
console.log('No articles found');
return;
}
// Log articles
titles.forEach((title, i) => {
console.log('Title:', title);
console.log('Link:', links[i]);
console.log();
});
// Write to file
fs.writeFileSync('articles.txt', JSON.stringify({ titles, links }));
});
Next Steps
With this foundation, you can now:
The key is that you now understand how to programmatically grab data from a site using Node.js. The possibilities are endless :)
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.