Sharpen Your Web Scraping Skills: 4 Challenging Web Sites That Will Test Your Web Scraping Skills

We had much fun racking our brains for memories of projects that helped us hone our skills years back. So if you are beginning in web scraping, the best way to get right is to throw yourself in the deep end where you will fail a lot and learn a lot. So here are 5 projects we at Proxies API think will make you a well-rounded web scraping engineer in the shortest amount of time possible. These hopefully will first break all the confidence you have in yourself and then build it back to greater heights, by the time you are done with it. Get them tiger and tell us how you did and what you discovered. We are dying to hear from you noobs :-)
1. Challenge 1:
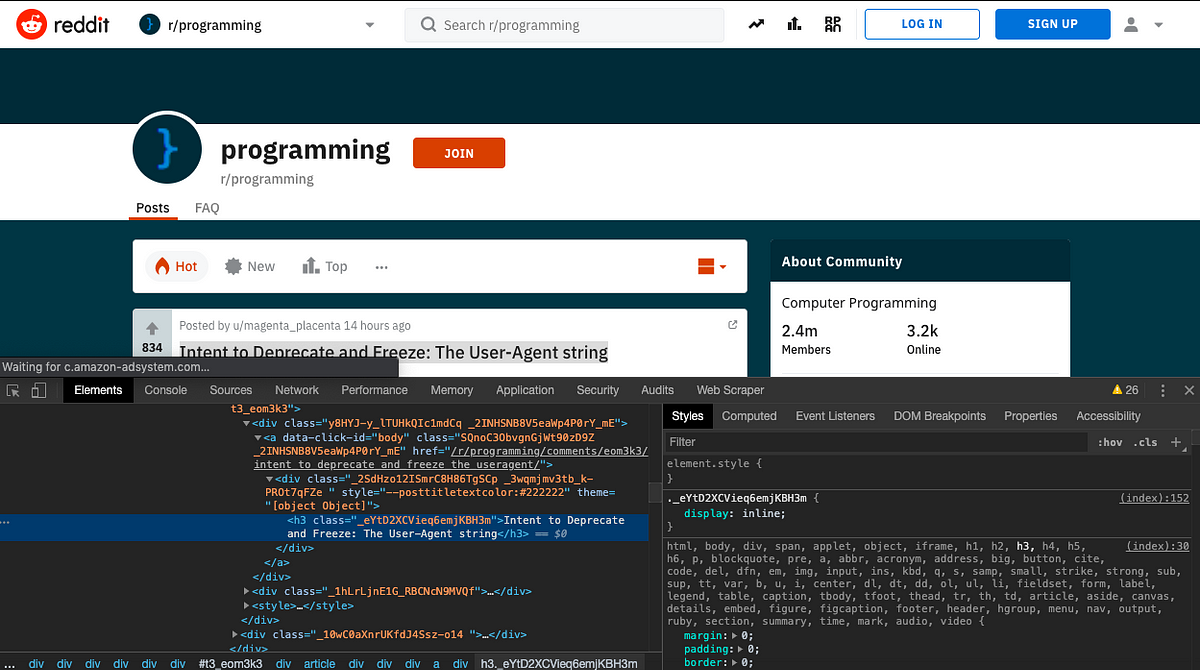
Scrape Reddit — Get us the r/programming subreddit data
a. The reason: Reddit is the second home of most programmers & hackers, and there are many who want to scrape the data for fun and profit. Reddit is expecting you and ready for you. We found it a bit of a challenge. Take a look at the CSS class names. It doesn’t make any sense. It is, we believe, to discourage web scraping. They keep changing the class names now and then because it is named when rendering by an automated system. Reddit helps you hone your web scraping skills by using proper XPath commands.
b. Primary Skill you will learn: You will learn how to yield XPath more effectively.
2. Challenge 2:
Yelp — Find us a bunch of restaurants in San Francisco including their phone numbers, address, and the kind of food people likes to eat there.
a. The reason: Yelp is quick to block you after a few requests in various ways. So you will learn the skills of rate-limiting, overcoming CAPTCHAs, and sooner rather than later, IP blocks.
b. Congrats now you are no longer a web scraping virgin.

c. Main Skill you will learn: Overcoming IP blocks.
d. Another thing you will learn: That there are no free lunches.
e. Eventually, almost everyone falls to the lure of the free public proxy servers seemingly available in the thousands on tens of web sites that list them. But the truth is, you will probably have to invest in a professional rotating proxy server service like Proxies API (full disclosure, I am the founder of Proxies API) if you want to route your requests through a large pool of high-speed residential proxies (millions in our case) and have a peaceful night.
3. Challenge 3:
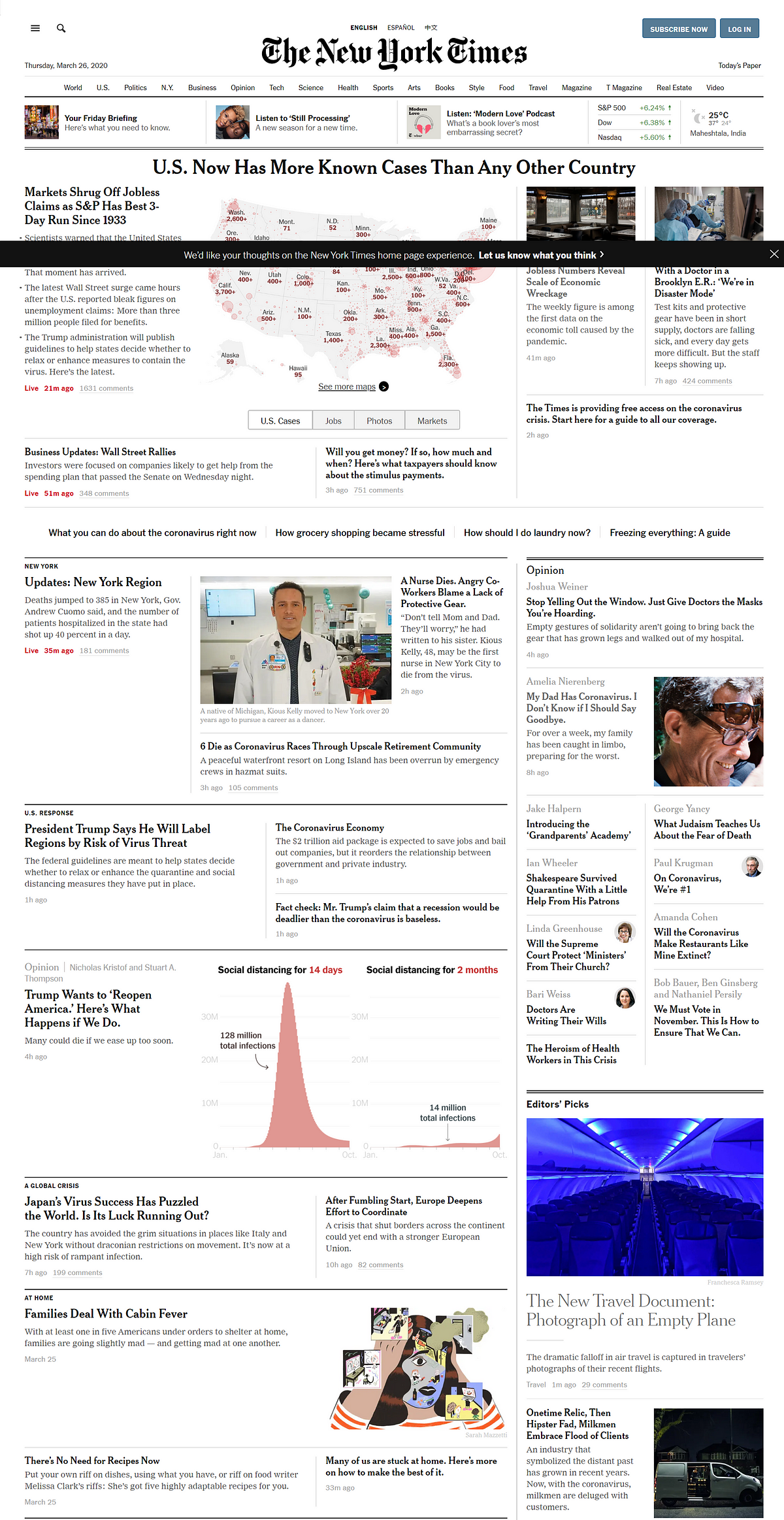
Scraping a news site like the New York Times. Get us the editorial section of the NYT. Get us the headlines, links, authors, date, and the article content itself.
a. News sites pose a typical set of problems, mainly finding news headlines in various categories. Then scraping the actual article almost always has the problem of removing the HTML Boilerplate. It is the extra HTML and CSS that constitute the menu, the header, the footer, the ads that need to be removed. You will also encounter a lot of badly formed HTML so you might learn the powers of Beautiful Soup.
b. You can also go the extra mile to download the article related images — notably, the main image, the author, the date of the article, etc.
c. Primary Skills you will learn: Removing boilerplate, handling bad HTML.
4. Challenge 4:
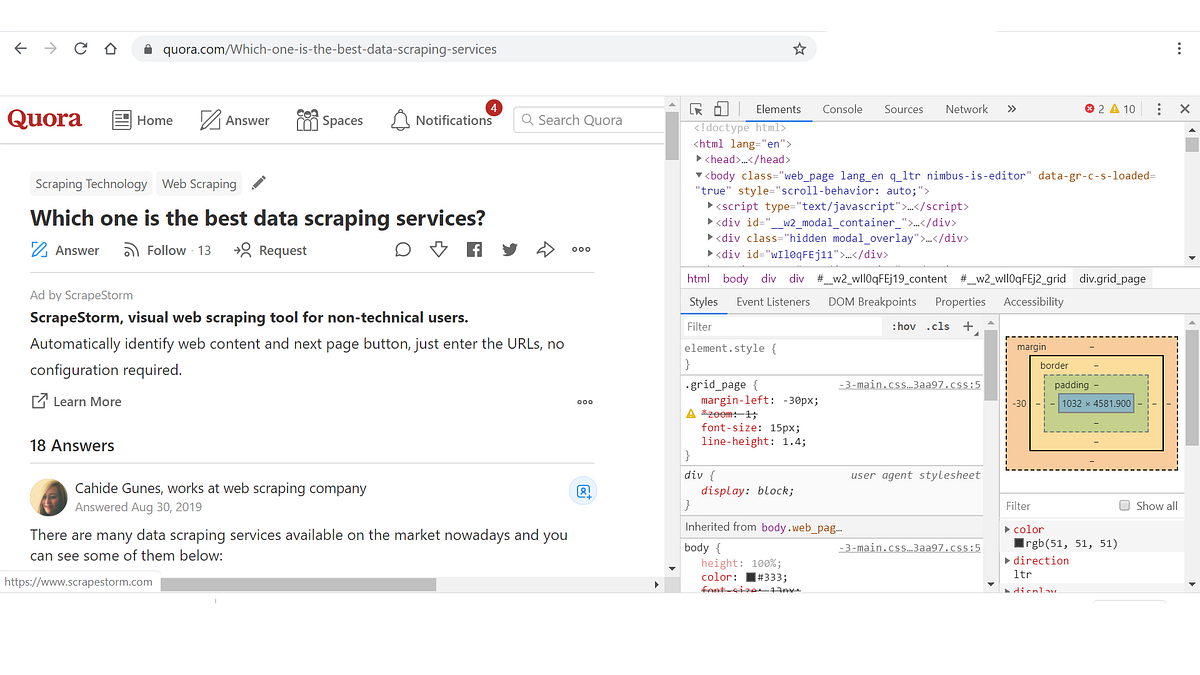
Scraping a website Quora: Scrape all the answers on this page: https://www.quora.com/Which-one-is-the-best-data-scraping-services
a. Quora loads most of its content using AJAX. So you will learn how to use Puppeteer to allow the JS to render, solve the infinite page scroll automation problem, and then retrieve dynamic content.
b. Primary Skills you will learn: Scraping AJAX loaded content, simulating page scrolls, etc.
The author is the founder of Proxies API, a proxy rotation API service.