The Complete Guide To Web Scraping in Python
Getting started
Getting started with beautiful soup
Beautiful Soup is a python library that we will use extensively in scraping. It allows your to parse the HTML DOM and be able to select portions of the HTML in various intelligent ways as you are going to soon see.
We are also going to see how we can scrape New York Times articles using Python and BeautifulSoup is a simple and elegant manner.
So the aim of this section is to get you started on a real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup with...
pip3 install beautifulsoup4We will also need the libraries' requests, lxml and soup sieve to fetch data, break it down to XML, and to use CSS selectors. Install them using...
pip3 install requests soupsieve lxmlOnce installed open an editor and type in...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
Using Beautiful Soup to scrape The New York Times
Now that we have installed the beautiful soup library, lets take a practical challenge and see how we can apply it to crawling
Now let's go to the NYT home page and inspect the data we can get.
This is how it looks
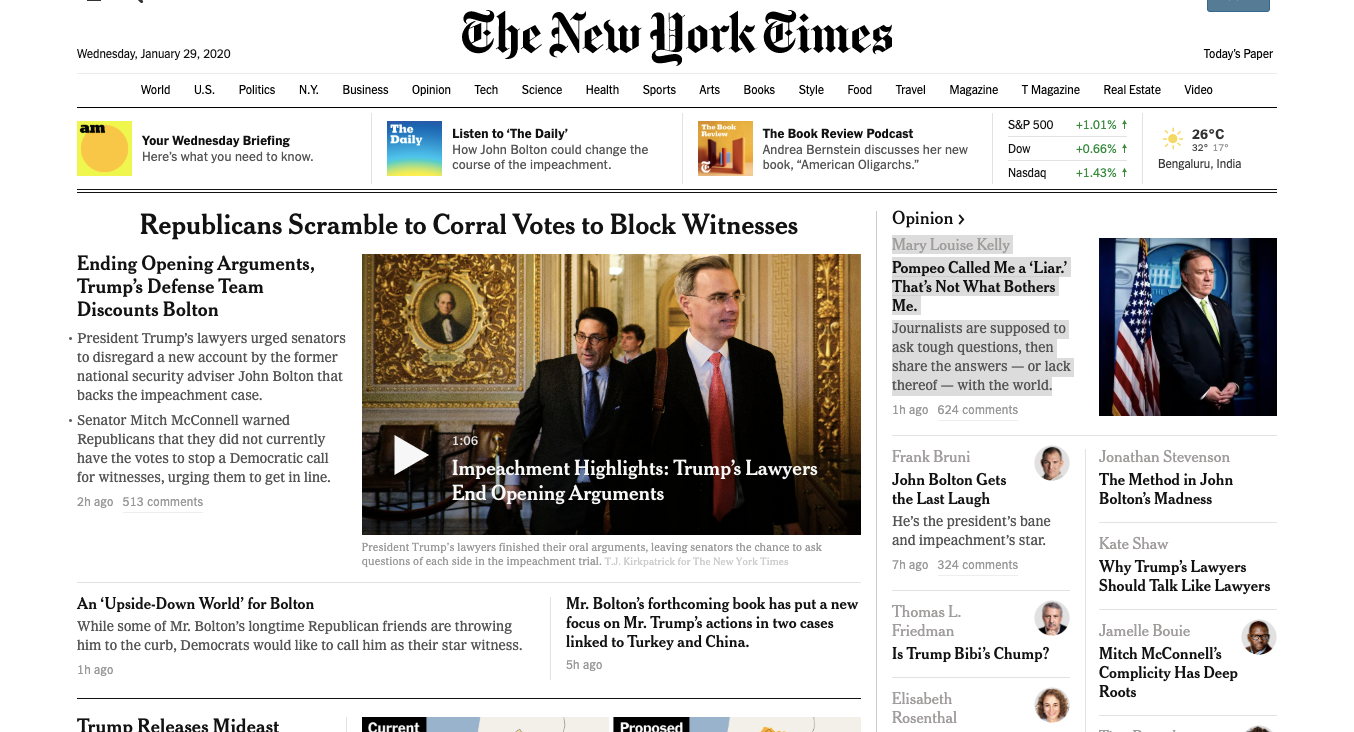
Back to our code now... let's try and get this data by pretending we are a browser like this...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.nytimes.com/'
response=requests.get(url,headers=headers)
print(response)
Save this as nyt_bs.py.
if you run it...
python3 nyt_bs.py
You will see the whole HTML page
Now we need to use beautiful soup's CSS selectors to our benefit. It basically allows you to select a portion of the HTML based on the CSS class or the name of the element.
Now lets use CSS selectors to get to the data we want... To do that let's go back to Chrome and open the inspect tool. We now need to get to all the articles... We notice that the
with the class 'assetWrapper' holds all the individual articles together.
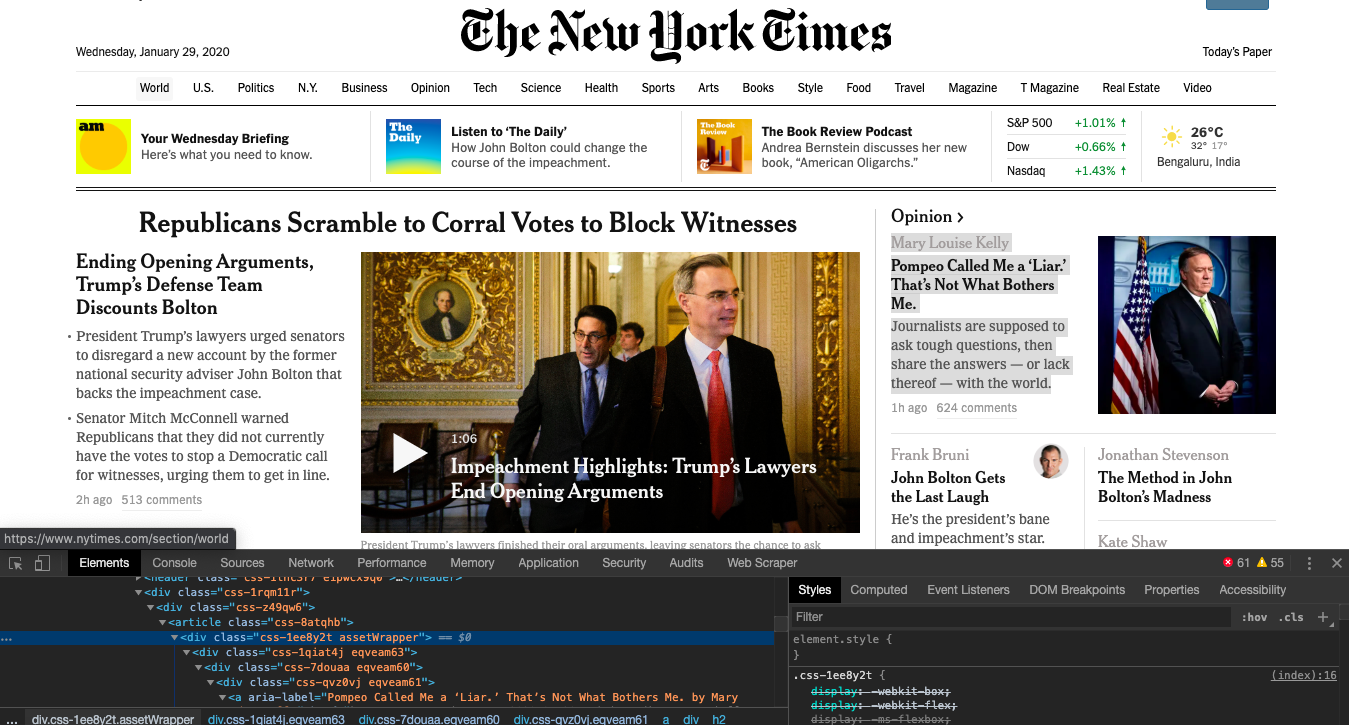
If you notice, that the article title is contained in an element inside the assetWrapper class. We can get to it like this...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.nytimes.com/'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
#print(soup.select('.Post')[0].get_text())
for item in soup.select('.assetWrapper'):
try:
print('----------------------------------------')
headline = item.find('h2').get_text()
print(headline)
except Exception as e:
#raise e
print('')
This selects all the assetWrapper article blocks and runs through them looking for the element and printing its text. So when you run it you get ...
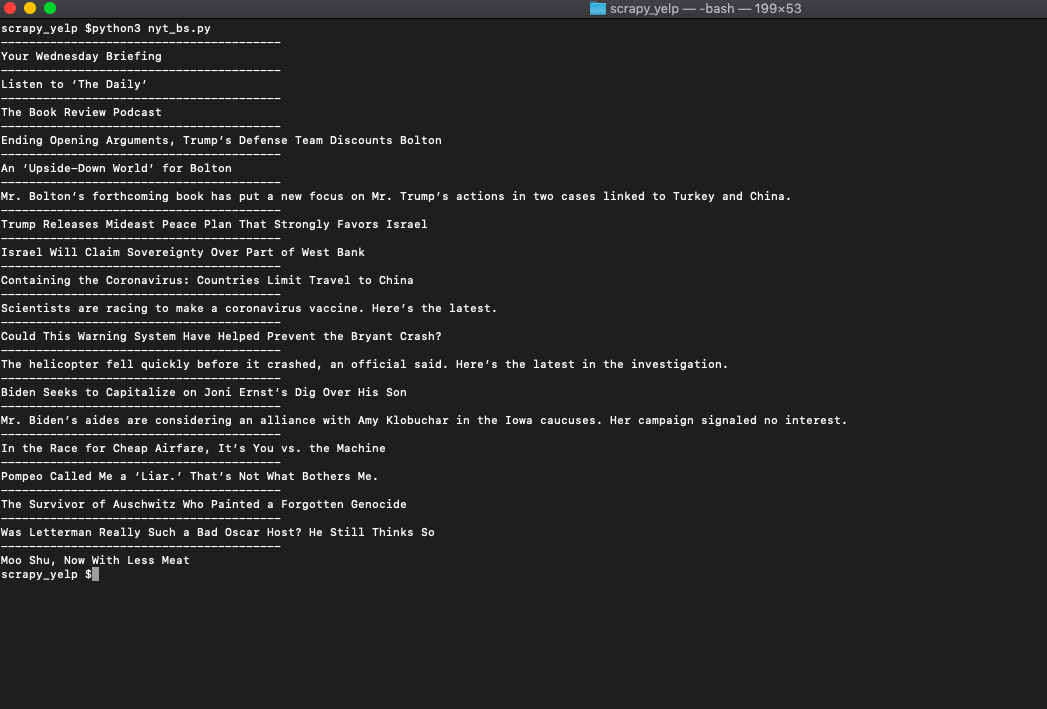
Bingo!! we got the article titles...
Now with the same process, we get the class names of all the other data like article link and article summary...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.nytimes.com/'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
#print(soup.select('.Post')[0].get_text())
for item in soup.select('.assetWrapper'):
try:
print('----------------------------------------')
headline = item.find('h2').get_text()
link = item.find('a')['href']
summary = item.find('p').get_text()
print(headline)
print(link)
print(summary)
except Exception as e:
#raise e
print('')That when run, should print everything we need from each article like this...
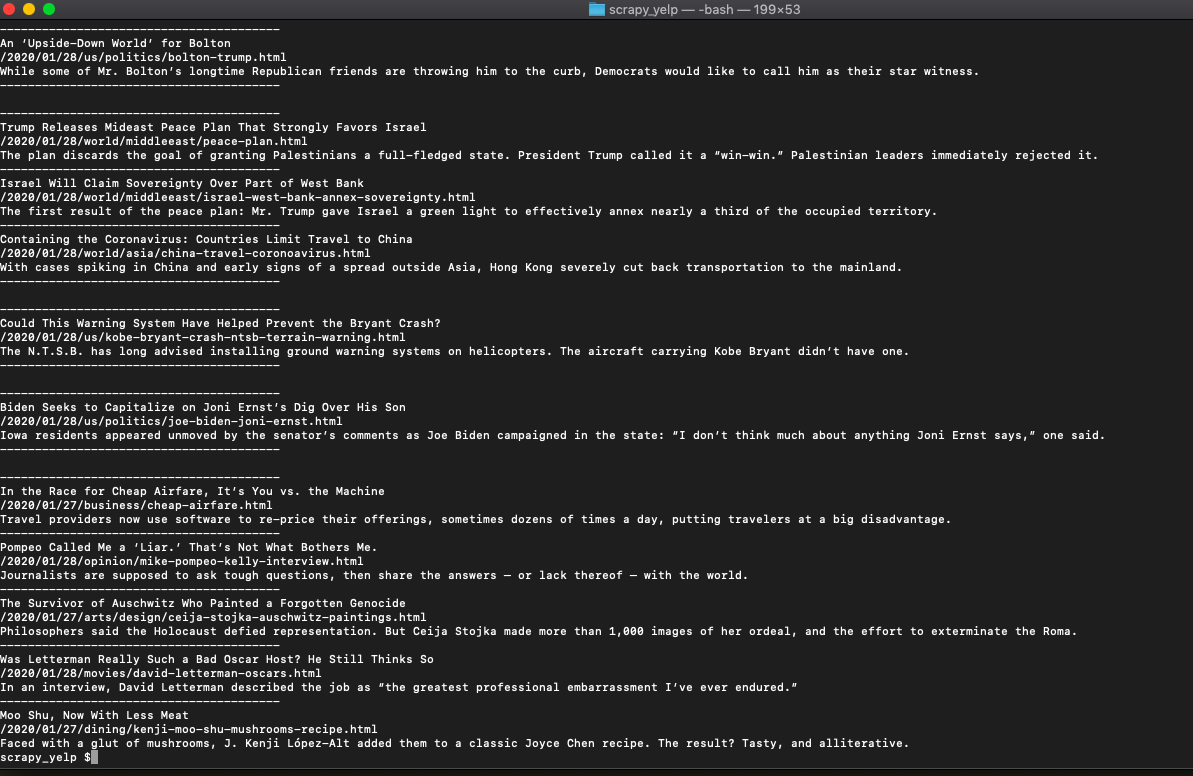
Getting started with Scrapy
Scrapy is one of the most useful open source tools for scraping at a large scale. It handles multi-threading, different file types, robots.txt rules etc out of the box and makes it easy to get started.
It is one of the easiest tools that you can use to scrape and also spider a website with effortless ease.
First, we need to install scrapy if you haven't already.
pip install scrapy
Scraping an entire blog with Scrapy
One of the most common applications of web scraping according to the patterns we see with many of our customers at Proxies API is scraping blog posts. Today let's look at how we can build a simple scraper to pull out and save blog posts from a blog like CopyBlogger.
Here is how the CopyBlogger blog section looks.
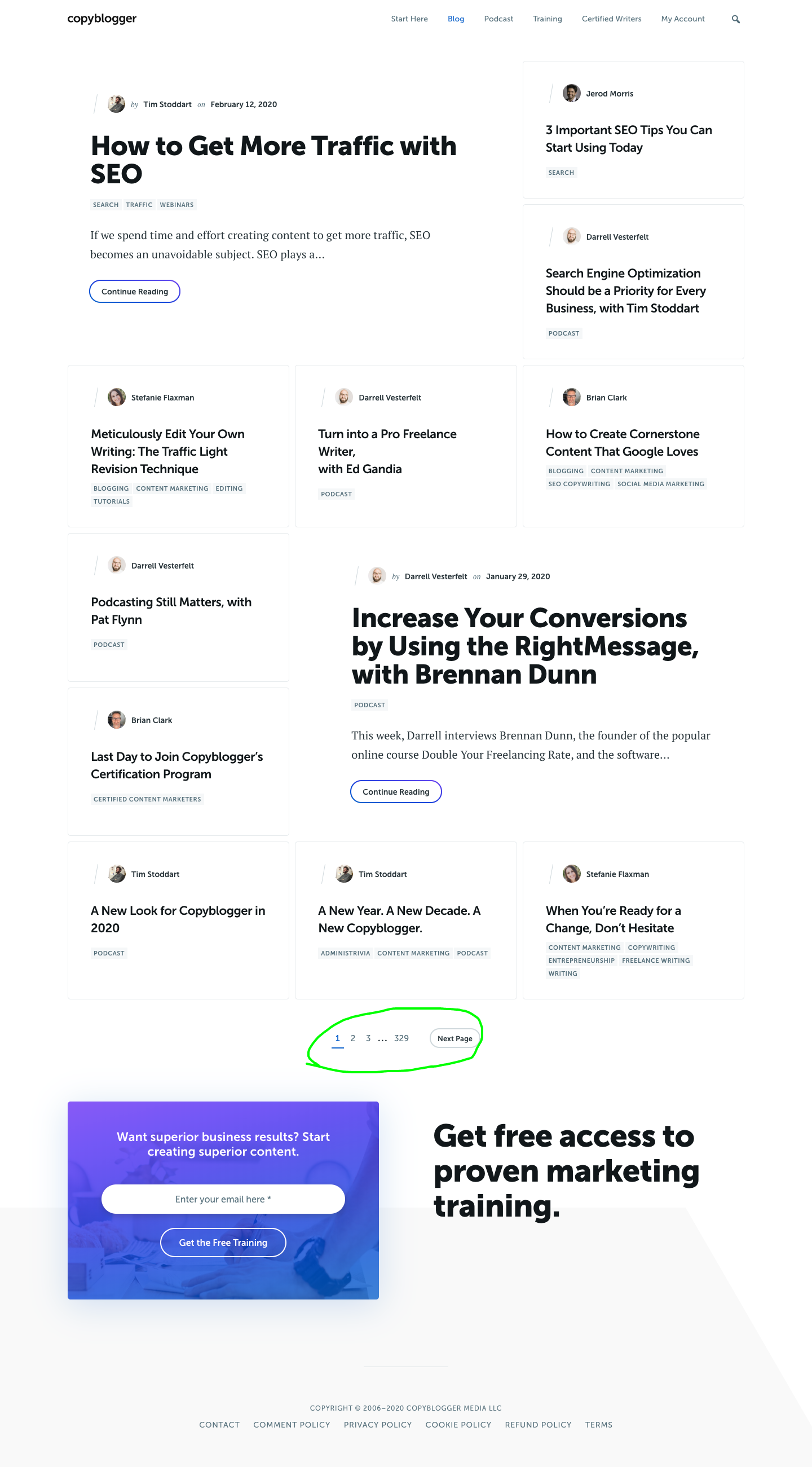
You can see that there are about 10 posts on this page. We will try and scrape them all.
Since you have already installed Scrapy, we will add a simple file with some barebones code like so.
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):Let's examine this code before we proceed...
The allowed_domains array restricts all further crawling to the domain paths specified here.
start_urls is the list of URLs to crawl... for us, in this example, we only need one URL.
The LOG_LEVEL settings make the scrapy output less verbose so it is not confusing.
The def parse(self, response): function is called by scrapy after every successful URL crawl. Here is where we can write our code to extract the data we want.
Now let's see what we can write in the parse function...
For this let's find the CSS patterns that we can use as selectors for finding the blog posts on this page.
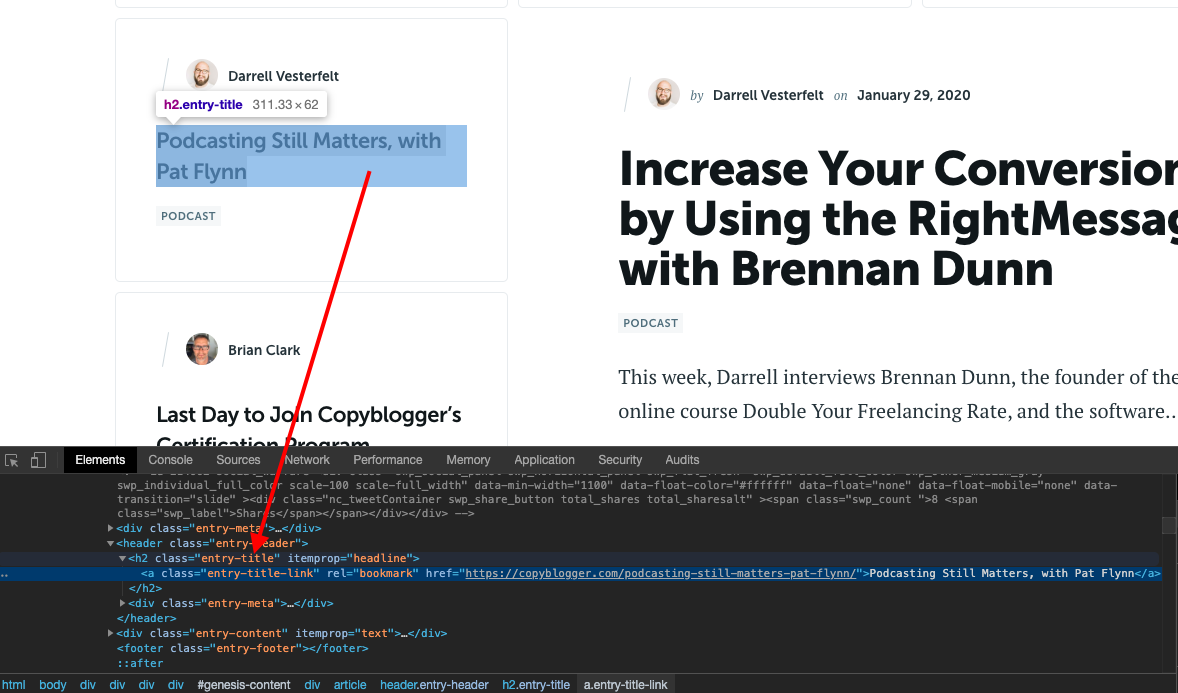
When we inspect this in the Google Chrome inspect tool (right-click on the page in Chrome and click Inspect to bring it up), we can see that the article headlines are always inside an H2 tag with the CSS class entry-title. This is good enough for us. We can just select this using the CSS selector function like this.
titles = response.css('.entry-title').extract()This will give us the Headline. We also need the href in the 'a' which has the class entry-title-link so we need to extract this as well
links = response.css('.entry-title a::attr(href)').extract()So lets put this all together...
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class blogCrawlerSimple(CrawlSpider):
name = 'blogCrawlerSimple'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
def parse(self, response):
#yield response
titles = response.css('.entry-title').extract()
links = response.css('.entry-title a::attr(href)').extract()
for item in zip(titles, links):
all_items = {
'title' : BeautifulSoup(item[0]).text,
'link' : item[1],
}
#found the link now lets scrape it...
yield scrapy.Request(item[1], callback=self.parse_blog_post)
yield all_items
def parse_blog_post(self, response):
print('Fetched blog post' response.url)Let's save it as BlogCrawler.py and then run it with these parameters which tells scrapy to disobey Robots.txt and also to simulate a web browser.
scrapy runspiderBlogCrawler.py -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36" -s ROBOTSTXT_OBEY=FalseWhen you run it should return...
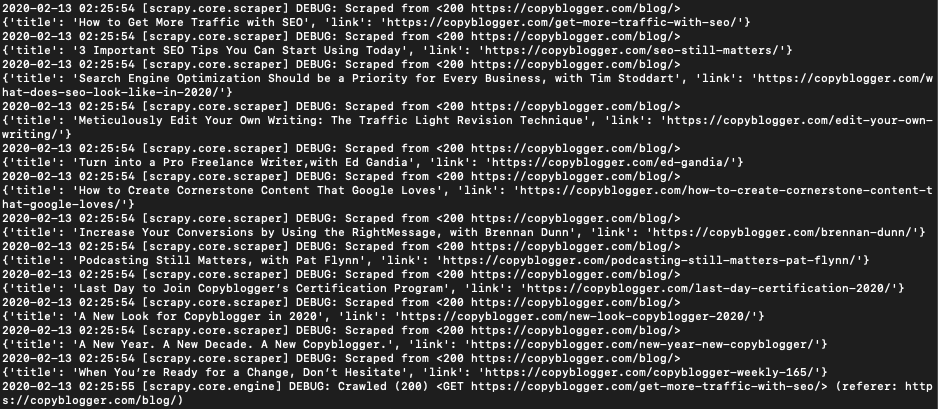
Those are all the blog posts. Let's save them into files.
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class blogCrawlerSimple(CrawlSpider):
name = 'blogCrawlerSimple'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
def parse(self, response):
#yield response
titles = response.css('.entry-title').extract()
links = response.css('.entry-title a::attr(href)').extract()
#links = response.css('.css-8atqhb a::attr(href)').extract()
for item in zip(titles, links):
all_items = {
'title' : BeautifulSoup(item[0]).text,
'link' : item[1],
}
#found the link now lets scrape it...
yield scrapy.Request(item[1], callback=self.parse_blog_post)
yield all_items
def parse_blog_post(self, response):
print('Fetched blog post' response.url)
filename = 'storage/' response.url.split("/")[3] '.html'
print('Saved post as :' filename)
with open(filename, 'wb') as f:
f.write(response.body)
returnWhen you run it now, it will save all the blog posts into a file folder.
But if you really look at it, there are more than 320 odd pages like this on CopyBlogger. We need a way to paginate through to them and fetch them all.
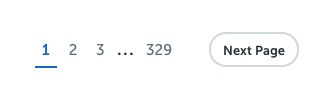
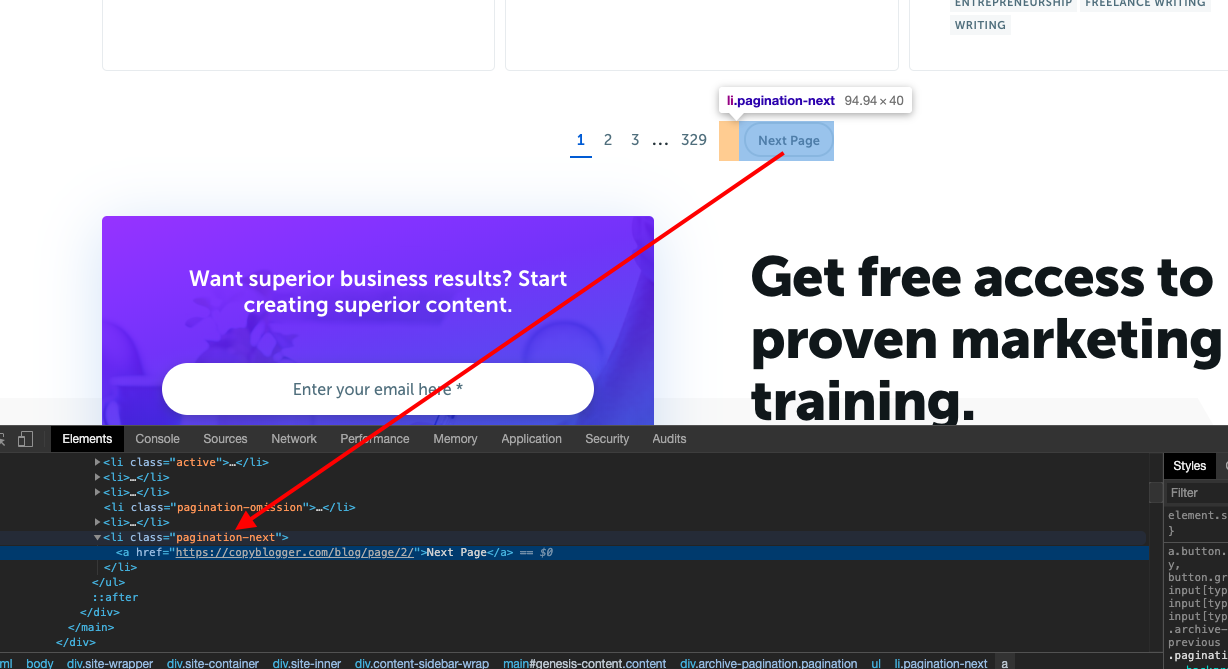
When we inspect this in the Google Chrome inspect tool, we can see that the link is inside an LI element with the CSS class pagination-next. This is good enough for us. We can just select this using the CSS selector function like this...
nextpage = response.css('.pagination-next').extract()This will give us the text 'Next Page' though. What we need is the href in the 'a' tag inside the LI tag. So we modify it to this...
nextpage = response.css('.pagination-next a::attr(href)').extract()In fact, the moment we have the URL, we can ask Scrapy to fetch the URL contents like this
yield scrapy.Request(nextpage[0], callback=self.parse_next_page)So the whole code looks like this:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class blogCrawler(CrawlSpider):
name = 'blogCrawler'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
def parse(self, response):
#yield response
titles = response.css('.entry-title').extract()
links = response.css('.entry-title a::attr(href)').extract()
nextpage = response.css('.pagination-next a::attr(href)').extract()
yield scrapy.Request(nextpage[0], callback=self.parse)
#links = response.css('.css-8atqhb a::attr(href)').extract()
for item in zip(titles, links):
all_items = {
'title' : BeautifulSoup(item[0]).text,
'link' : item[1],
}
#found the link now lets scrape it...
yield scrapy.Request(item[1], callback=self.parse_blog_post)
yield all_items
def parse_blog_post(self, response):
print('Fetched blog post' response.url)
filename = 'storage/' response.url.split("/")[3] '.html'
print('Saved post as :' filename)
with open(filename, 'wb') as f:
f.write(response.body)
return
def parse_next_page(self, response):
print('Fetched next page' response.url)and when you run it, it should download all the blog posts that were ever written on CopyBlogger onto your system.
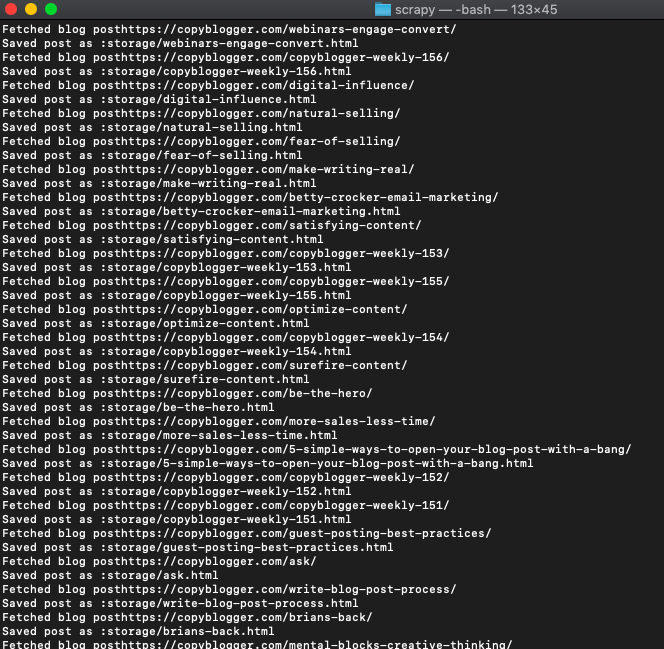
Scaling Scrapy
The example above is ok for small scale web crawling projects. But if you try to scrape large quantities of data at high speeds you will find that sooner or later your access will be restricted. Web servers can tell you are a bot so one of the things you can do is run the crawler impersonating a web browser. This is done by passing the user agent string to the Wikipedia web server so it doesn't block you.
Like this:
-s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64)/
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36" /
-s ROBOTSTXT_OBEY=False
The Gotchas
Now that we have learnt about the 2 major tools, Beautiful soup and Scrapy, lets look at some of the common problems that every programmer faces while web crawling. One of the main factors that cause all the friction in web crawling is the fact that many websites do not want you to crawl them. Heck, Google doesnt want you to crawl them even though thats exactly how they got their data from, through web crawling! Over the years, people who manage websites have come up with many ways to stop you from getting to their content. We need to know about these measures if we think we have any chance against them...
Ways web servers can tell you are a crawler
The cat and mouse game between crawlers and web servers has been going on for a while now. While there are more complex ways large entities like Google/Amazon etc detect crawlers, here are the basic ways in which web servers can tell you are not human.
- Your browser's signature (User-Agent-String) remains the same during multiple web scraping requests.
- Your IP address remains the same, and so gets blocked.
- You change your IP to a proxy but don't change your browser's identity (User-Agent-String)
- You don’t have enough proxies so gradually, all of them get blocked.
- You are making too many requests per second.
- You are too regular in your requests.
- You are not sending back cookie data and other small clues.
- You are unable to solve CAPTCHAs.
How web servers stop bots
Like we learnt in the previous section that many web servers mainly want to allow humans to query them and disallow bots.
Here are the main ways how the web servers stop bots from doing their thing:
- They look at the User-Agent-String header sent by the bot. If it is not a familiar one sent by a known browser on a known OS, they might reject the call.
- The bot is making too many calls too frequently. Web servers know that humans dont do that and can block you out.
- The bot is making calls in a sequential order which humans rarely do.
- The bot is making calls at the same time every day. The call logs show it and the webmaster can block you.
- The bot is making calls at predictable intervals.
- The bot is not passing the cookies back. Even though the cookies are not relevant to the use of the data, the web servers expect it to come back as all browsers do pass them back.
- The User-Agent-String is always the same and is not rotated.
The way out
Rotating user agent strings
Many times the target website's algorithm might be picking up on who you are by the User-Agent-String signature that your curl request or any other library you might be using is sending. Even the absence of it is telling.
But if you do it well, you do get a lease of life, albeit only for a while.
User-Agent Strings were initially being used to identify the environment the user was in so that web servers could tailor the content to that environment. For example, if the user was using a tablet or a phone, you could make the content work in those height and width constraints.
But now web servers use this ‘tell’ to keep web crawlers at bay.
Here is how you can overcome that in python.
Let us create a file called USStrings.txt and fill it up with one User-Agent string per line like this:
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.113 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.167 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36
Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/533.4 (KHTML, like Gecko) Chrome/5.0.375.99 Safari/533.4
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36
Mozilla/5.0 (Linux; Android 9; SM-G960F Build/PPR1.180610.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.157 Mobile Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.109 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_6_8) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
BrightSign/8.0.69 (XT1143)Mozilla/5.0 (X11; Linux armv7l) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.11.2 Chrome/65.0.3325.230 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36 MVisionPlayer/1.0.0.0
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36
Mozilla/5.0 (Windows NT 6.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.112 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.125 Safari/537.36
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) QtWebEngine/5.9.4 Chrome/56.0.2924.122 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36
Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36
Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.117 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36
Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
Mozilla/5.0 (Linux; Android 6.0.1; SM-G532G Build/MMB29T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.83 Mobile Safari/537.36
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36
Mozilla/5.0 (Linux; Android 9; SM-G950F Build/PPR1.180610.011; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.157 Mobile Safari/537.36
Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.67 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/32.0.1700.107 Safari/537.36
Mozilla/5.0 (en-us) AppleWebKit/534.14 (KHTML, like Gecko; Google Wireless Transcoder) Chrome/9.0.597 Safari/534.14Then the following code should be able to retrieve a random string every time you call it.
import random
def getRandomUserAgent():
lines = open('UAStrings.txt').read().splitlines()
return random.choice(lines)
print(getRandomUserAgent())You can use it in the context of web scraping using the python requests module like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import random
def getRandomUserAgent():
lines = open('UAStrings.txt').read().splitlines()
return random.choice(lines)
UAString =getRandomUserAgent()
headers = {'User-Agent': UAString}
url = 'https://www.amazon.com/s?k=shampoo&ref=nb_sb_noss_1'
response=requests.get(url,headers=headers)Now you got code smart enough to get you past most web servers, but it won’t scale. To thousands of links, then you will find that you will get IP blocked quickly by many websites as well. In this scenario, using a rotating proxy service to rotate IPs is almost a must.
Using Proxies
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
a) With millions of high speed rotating proxies located all over the world.
b) With our automatic IP rotation.
c) With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions).
d) With our automatic CAPTCHA solving technology.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
A simple API can access the whole thing like the below in any programming language.
You don’t even have to take the pain of loading Puppeteer as we render JavaScript behind the scenes, and you can get the data and parse it in any language like Node, Puppeteer, or Php or using any framework like Scrapy or Nutch. In all these cases, you can call the URL with render support like so…
curl "http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free
Common problems faced while web scraping
Scraping all the links on a web page
Here is a simple and uncomplicated way to get just the links from a website. This is very useful many times for just being able to count the number of links, use it later in a high-speed web crawler or any other analysis.
First, we import Beautiful soup and the requests module.
The code does that and also retrieves the HTML contents of the URL and uses Beautiful soup to get it ready for being able to query on it.
from bs4 import BeautifulSoup
import requests
def getAllLinks(url):
html_page = requests.get(url)
soup = BeautifulSoup(html_page.content, 'lxml')
print( getAllLinks("https://copyblogger.com") )BeautifulSoup has a function findAll and we will use the CSS selector 'a' to select all the hyperlinks we can find on the page.
links = []
for link in soup.findAll('a'):
url=link.get('href')
links.append(url)Notice how we are appending all the links we find into an array.
Putting the whole code together this is what it will look like.
from bs4 import BeautifulSoup
import requests
def getAllLinks(url):
html_page = requests.get(url)
soup = BeautifulSoup(html_page.content, 'lxml')
links = []
for link in soup.findAll('a'):
url=link.get('href')
if (url[0]!='#'):
links.append(url)
return links
print( getAllLinks("https://copyblogger.com") )The codes below check for hyperlinks that only point to elements within the page and ignores them.
if (url[0]!='#'):
links.append(url)And when we run it, we simply get all the links.
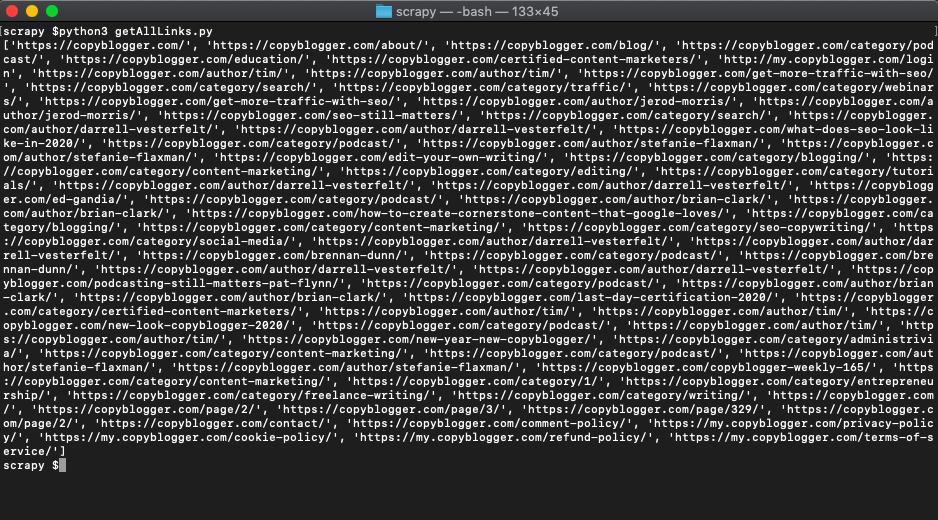
Scraping multiple (paginated) pages
Scrapy is one of the easiest tools that you can use to scrape and also spider a website with effortless ease.
Today lets see how we can solve one of the most common design patterns while scraping any large scale projects like scraping article list or blog posts. Typically, the number of items shown on a single page is limited to 10 or 20 and you will want to pull out all the pages as automatically as possible.
We will take the example of the CopyBlogger blog and see if we can run through all the pages without much sweat. We will do this and do it using a powerful tool like Scrapy because once we have this basic infrastructure, we will be able to build almost anything on top of it.
Here is how the CopyBlogger blog section looks:
You can see that there are about 10 posts on each page and then there are about 329 pages in total.
First, we need to install scrapy if you haven't already
pip install scrapyOnce installed, we will add a simple file with some barebones code like so...
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):Let's examine this code before we proceed...
The allowed_domains array restricts all further crawling to the domain paths specified here.
start_urls is the list of URLs to crawl... for us, in this example, we only need one URL.
The LOG_LEVEL settings make the scrapy output less verbose so it is not confusing.
The def parse(self, response): function is called by scrapy after every successful URL crawl. Here is where we can write our code to extract the data we want.
Now let's see what we can write in the parse function...
For this let's find the CSS patterns that we can use as selectors for finding the next page link on any page.
We will not use the page links titled 1,2,3 for this. It makes more sense to find the link inside the 'Next Page' button. It should then ALWAYS lead us to the next page reliably.
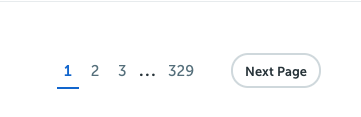
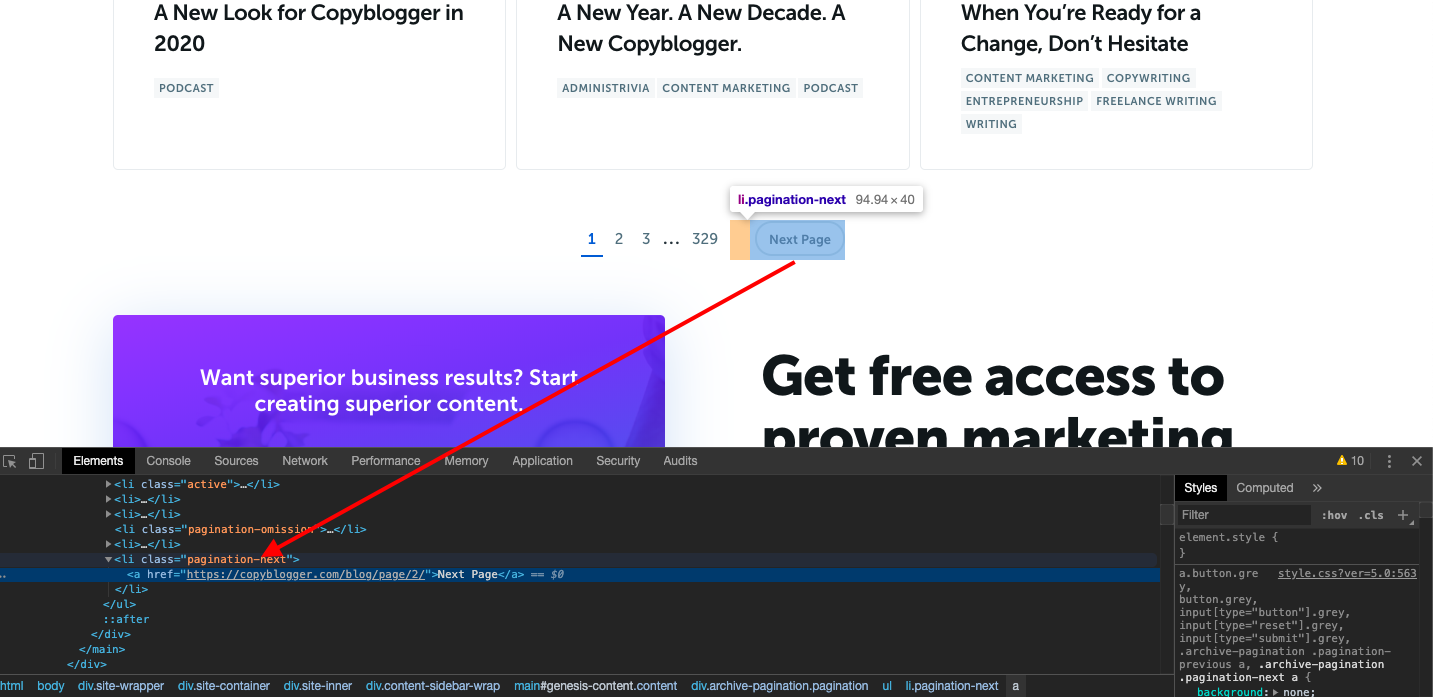
When we inspect this in the Google Chrome inspect tool (right-click on the page in Chrome and click Inspect to bring it up), we can see that the link is inside an LI element with the CSS class pagination-next. This is good enough for us. We can just select this using the CSS selector function like this...
nextpage = response.css('.pagination-next').extract()This will give us the text 'Next Page' though. What we need is the href in the 'a' tag inside the LI tag. So we modify it to this...
nextpage = response.css('.pagination-next a::attr(href)').extract()In fact, the moment we have the URL, we can ask Scrapy to fetch the URL contents like this
yield scrapy.Request(nextpage[0], callback=self.parse_next_page)So the whole code looks like this:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):
print('Current page ' response.url)
nextpage = response.css('.pagination-next a::attr(href)').extract()
nextpagetext = response.css('.pagination-next').extract()
yield scrapy.Request(nextpage[0], callback=self.parse_next_page)
return
def parse_next_page(self, response):
print('Fetched next page' response.url)
returnLet's save it as SimpleNextPage.py and then run it with these parameters which tells scrapy to disobey Robots.txt and also to simulate a web browser...
scrapy runspider SimpleNextPage.py -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36" -s ROBOTSTXT_OBEY=FalseWhen you run it should return...

We dont have to stop there. Let's make these function recursive. For that, we can do away with the parse_next_page function altogether and ask the Parse function to parse all the next page links.
Here is the final code:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):
print('Current page ' response.url)
nextpage = response.css('.pagination-next a::attr(href)').extract()
nextpagetext = response.css('.pagination-next').extract()
yield scrapy.Request(nextpage[0], callback=self.parse)
return
def parse_next_page(self, response):
print('Fetched next page' response.url)
returnAnd the results:
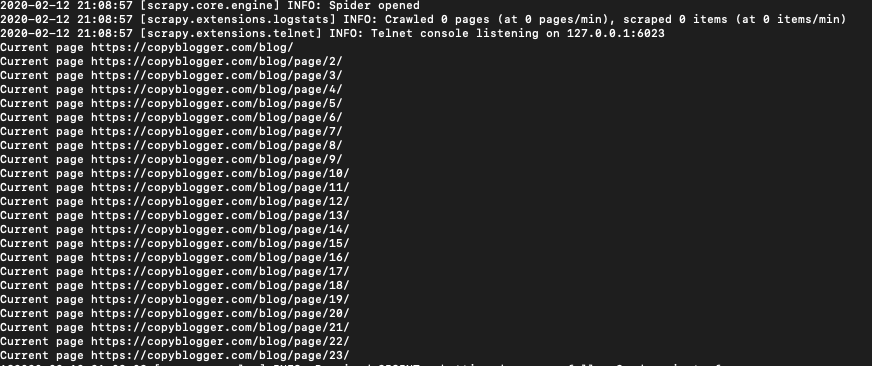
It will fetch all the pages which you can parse, scrape or whatever other function you may want to perform on them.
Handling infinite page scroll
In this example, we will try to load a Quora answers page and scroll down till we reach the end of the content and then take a screenshot of the page to our local disk. We will also try and scrape all the answers and save them as a JSON page on your drive.We are going to scrape this page accurately.
This one has more than 20 answers running into multiple pages, but not all of them load unless you scroll down.
Quora uses an infinite scroll page. Websites with endless page scrolls are basically rendered using AJAX. It calls back to the server for extra content as the user pages down the page. One of the ways of scraping data like this is to simulate the browser, allow the javascript to fire the ajax, and also to simulate a page scroll.
Puppeteer is the best tool to do that. It controls the Chromium browser behind the scenes. Let’s install Puppeteer first.
mkdir quora_scraper
cd quora_scraper
npm install --save puppeteer
Then create a file like this and save it in the quora_scraper folder. Call it quora_scroll.js
const fs = require('fs');
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.quora.com/Which-one-is-the-best-data-scraping-services');
await page.setViewport({
width: 1200,
height: 800
});
await autoScroll(page);// keep scrolling till resolution
await page.screenshot({
path: 'quora.png',
fullPage: true
});
await browser.close();
})();
async function autoScroll(page){
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
var totalHeight = 0;
var distance = 100;
var timer = setInterval(() => {
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight = distance;
//a few of the last scrolling attempts have brought no new
//data so the distance we tried to scroll is now greater
//than the actual page height itself
if(totalHeight >= scrollHeight){
clearInterval(timer);//reset
resolve();
}
}, 100);
});
});
}Now run it by the command
node quora_scroll.js
It should open the Chromium browser, and you should be able to see the page scroll in action.
Once done, you will find a rather large file called quora.png in your folder.
Now let’s add some more code to this to scrape the HTML collected after all the scrolling to get the answers and the details of the users who posted the answers.
We need to find the elements containing the user’s name and also the solution. If you inspect the HTML in Chrome’s Inspect tool, you will find the two parts with the class names, user, and ui_qtext_rendered_qtext contain the user’s name and their answer, respectively.
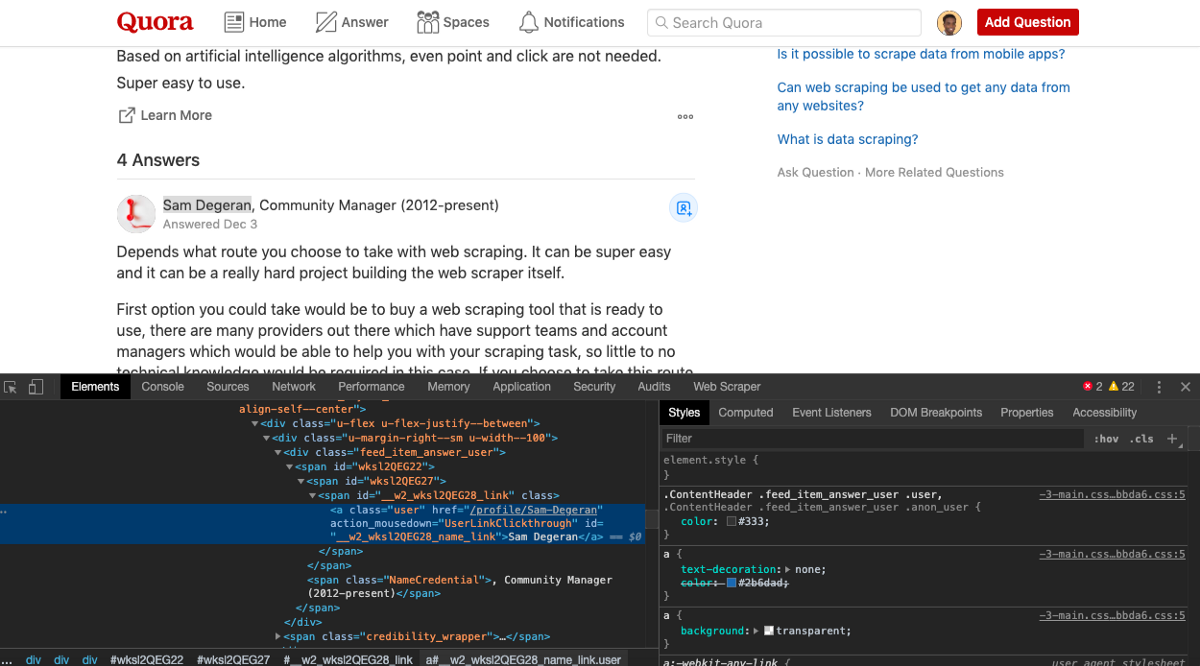
Puppeteer allows you to use CSS selectors to extract data using the querySelectorAll command like this.
var answers = await page.evaluate(() => {
var Answerrers = document.querySelectorAll('.user'); //gets the user's name
var Answers = document.querySelectorAll('.ui_qtext_rendered_qtext');//gets the answer
var titleLinkArray = [];
for (var i = 0; i < Answerrers.length; i ) {
titleLinkArray[i] = {
Answerrer: Answerrers[i].innerText.trim(),
Answer: Answers[i].innerText.trim(),
};
}
return titleLinkArray;
});We can put this code right after the page scrolling has finished, and so the whole code will look like this.
const fs = require('fs');
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.quora.com/Which-one-is-the-best-data-scraping-services');
//await page.goto('https://www.quora.com/Is-data-scraping-easy');
await page.setViewport({
width: 1200,
height: 800
});
await autoScroll(page);// keep scrolling till resolution
var answers = await page.evaluate(() => {
var Answerrers = document.querySelectorAll('.user');
var Answers = document.querySelectorAll('.ui_qtext_rendered_qtext');
var titleLinkArray = [];
for (var i = 0; i < Answerrers.length; i ) {
titleLinkArray[i] = {
Answerrer: Answerrers[i].innerText.trim(),
Answer: Answers[i].innerText.trim(),
};
}
return titleLinkArray;
});
console.log(answers);
await page.screenshot({
path: 'quora.png',
fullPage: true
});
console.log("The screenshot has been saved!");
await browser.close();
})();
async function autoScroll(page){
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
var totalHeight = 0;
var distance = 100;
var timer = setInterval(() => {
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight = distance;
if(totalHeight >= scrollHeight){//a few of the last scrolling attempts have brought no new data so the distance we tried to scroll is now greater than the actual page height itself
clearInterval(timer);//reset
resolve();
}
}, 100);
});
});
}Now run it with...
node quora_scroll.js
It will print the Answers scraped onto the console when you run it.
Now let’s go further and save it as a JSON file…
fs.writeFile("quora_answers.json", JSON.stringify(answers), function(err) {
if (err) throw err;
console.log("The answers have been saved!");
});And putting it all together
const fs = require('fs');
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false
});
const page = await browser.newPage();
await page.goto('https://www.quora.com/Which-one-is-the-best-data-scraping-services');
//await page.goto('https://www.quora.com/Is-data-scraping-easy');
await page.setViewport({
width: 1200,
height: 800
});
await autoScroll(page);// keep scrolling till resolution
var answers = await page.evaluate(() => {
var Answerrers = document.querySelectorAll('.user');
var Answers = document.querySelectorAll('.ui_qtext_rendered_qtext');
var titleLinkArray = [];
for (var i = 0; i < Answerrers.length; i ) {
titleLinkArray[i] = {
Answerrer: Answerrers[i].innerText.trim(),
Answer: Answers[i].innerText.trim(),
};
}
return titleLinkArray;
});
console.log(answers);
fs.writeFile("quora_answers.json", JSON.stringify(answers), function(err) {
if (err) throw err;
console.log("The answers have been saved!");
});
await page.screenshot({
path: 'quora.png',
fullPage: true
});
console.log("The screenshot has been saved!");
await browser.close();
})();
async function autoScroll(page){
await page.evaluate(async () => {
await new Promise((resolve, reject) => {
var totalHeight = 0;
var distance = 100;
var timer = setInterval(() => {
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight = distance;
if(totalHeight >= scrollHeight){//a few of the last scrolling attempts have brought no new data so the distance we tried to scroll is now greater than the actual page height itself
clearInterval(timer);//reset
resolve();
}
}, 100);
});
});
}Now run it.
node quora_scroll.jsOnce it is run, you will find the file quora_answers.json with the following results in it.
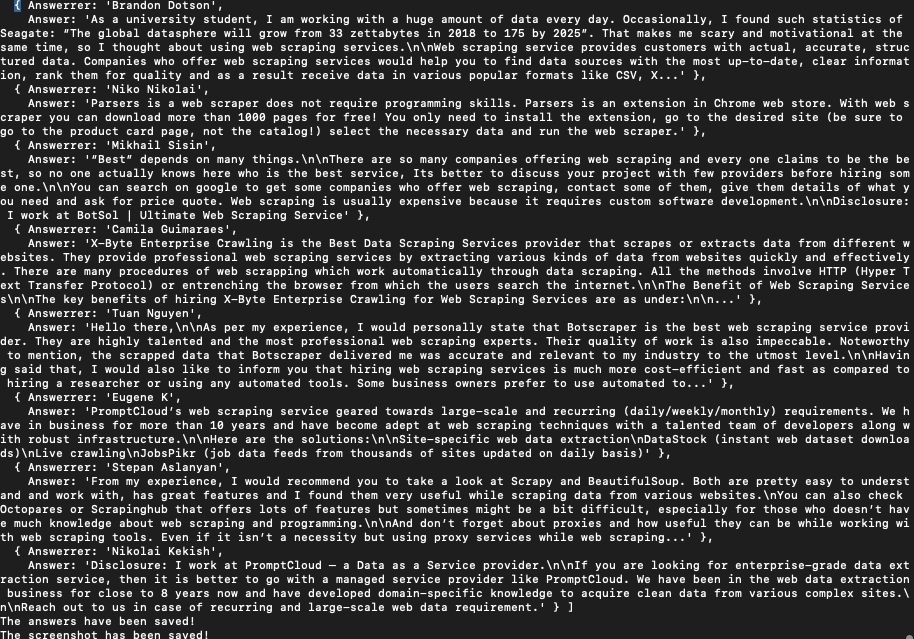
[{"Answerrer":"Cahide Gunes","Answer":"Which one is the best data scraping services?"},{"Answerrer":"Ethan Connor","Answer":"There are many data scraping services available on the market nowadays and you can see some of them below:\n\nImport io\nWebhose io\nScrapinghub\nVisual Scraper and etc.\n\n8 years ago, when Price2Spy was launched back in springtime 2011, there weren't many data scraping services.\n\nEver since Price2Spy was born, we have gained huge experience in data scraping that could help your business gather any valuable data in bulk.\n\nSo, if you are looking for data scraping service that tends to provide 'best' data scraping experience, please feel free to check out Price2Spy.\n\nBelow, you can see some of the key technical..."},{"Answerrer":"Ashley Ng","Answer":"Who is best at data scraping?"},{"Answerrer":"Ricky Arnold","Answer":"Is data scraping easy?"},{"Answerrer":"Eric Frazer","Answer":"What is the best way to scrape data from a website?"},{"Answerrer":"State Bank of India (SBI)","Answer":"I need to extract data from a website. What web scraping tool is the best?"},{"Answerrer":"Suresh Sharma","Answer":"What are some of the best web data scraping tools?"},{"Answerrer":"Ankitha Sumit","Answer":"I have tried several data scraping services like companies that provide data scraping & data mining services, Freelancers & data scraping tools also. But the best I found is Projjal K’s data scraping services on Fiverr. He really does amazing job. Fast, reliable & really friendly to his clients. I have recommeded him to many of my clients, colleagues and friends who were looking for a good data scraping service.\n\nYou guys can contact him from the links below:\n\nData Scraping & data mining service by Projjal K. on Fiverr.\nData Extraction service from any website & directory by Projjal.\nData Scrapin..."},{"Answerrer":"Priyanka Rathee","Answer":"Octoparse, the mission is to make data accessible to anyone, in particular, those without a technical background. In the long run, we aim to automate the web data collection process as easy as any everyday software, such as Excel and Word. In essence, we believe that data is becoming so important that everyone should be equipped with the ability to source the data they need without having to own a degree in Computer Science. So we would like to take the job from a Tech's hand and put it into a typical non-tech person's hand.\n\nThe Octoparse Data Extraction Solution provides is a highly flexibl..."},{"Answerrer":"Joel Daly","Answer":"First, let’s understand what makes a data scraping service good.\n\nThere are a number of things to consider before choosing a service:\n\nQuality of the data provided: The quality of the data depends both on the accuracy and freshness of it.\nAbility to meet the deadlines: One of the reasons we need data scraping services is that they can collect data very fast and deliver it to us. The timeframe also depends on the quantity of data needed. However a good service should be able to provide data in the set timeframe.\nTechnology/skilled staff: both the technology used and the skills of the staff will im..."},{"Answerrer":"Sam Degeran","Answer":"What are some of the best web data scraping tools?"},{"Answerrer":"Keerthi","Answer":"What is the best and most efficient way to scrape a website?"},{"Answerrer":"Skone Cosmetics","Answer":"If scraping data from Amazon, Alibaba and other websites is illegal, then how do dropshipping sites like Pricematik, ProfitScraper and others ..."},{"Answerrer":"Henry Obinna","Answer":"Is it worth paying for a web scraping service?"},{"Answerrer":"Mason Harlin","Answer":"What are the easiest and best web scraping tools for non-technical people? I want to collect data from a few sites and have it dumped into Exc..."},{"Answerrer":"Timothy Lewis","Answer":"Content scraping (also referred to as web scraping or data scraping) is nothing but lifting off unique/original content from other websites and publishing it elsewhere. ...Content scrapers typically copy the entire content and pass it off as their own content.\n\nThe Web Scraping Services:\n\nScrape Financial and Stock Market Data\nWeb Scraping for Sales Lead Generation\nWeb Scraping Sentiment Analysis\nScraping Product Prices and Reviews\nWeb Scraping Mobile Application\nScrape Airline Websites\nGoogle Scraper\nWeb Screen Scraping\nDoctors and Lawyers Data Scraping\nWeb Scraping Car Data\n\nInfovium web scraping compan..."},{"Answerrer":"Pritpal Singh","Answer":"What are the details of the Global Ed-Vantage loan offered by the State Bank of India? What is the interest rate offered by SBI..."},{"Answerrer":"Jacob Martirosyan","Answer":"According to an article published in Live Mint on 17.08.2018, while the government has stepped up its efforts to improve the quality of higher education institutions in India, more and more Indian students seem to be preferring to study abroad. According to the Reserve Bank of India (RB..."},{"Answerrer":"Data iSolutions","Answer":"Hello there,\n\nData scraping is all about extracting data from the World Wide Web for various reasons. Extractive data from the web can be extremely beneficial for businesses. It can help you gain insight into the current market trend, your potential customers, your competitors and that’s just the beginning.\n\nThere are two ways to scrape data from a website, either you can write code and scrape data on your own, or you can scrape data with the help of certain scraping tools. But, know that automated tools would not be able to scrape data from each and every website. And, writing scraping codes r..."},{"Answerrer":"Ankita Banerjee","Answer":"We can list N number of data scraping service providers, but the thing is we have to opt for the best service provider in terms of cost, time and the excellence in scraping tricky website with quality output.\n\nSearch for a web creeping specialist organization with transparent and straightforward evaluating. Evaluating models that are exceptionally mind-boggling are regularly irritating and May even imply that they have shady concealed expenses.\n\nEven I had tried many data scraping services but the one which I found the best is outsourcebigdata, they are so much willing in providing quality outp..."},{"Answerrer":"Alessander Conossel","Answer":"Checkout Agenty!\n\nAgenty is SaaS(Software as a service) based scraping tool. You can run from any browser by accessing through the url. It provides a complete toolkit for data extractions.\n\nIt offers the services according to your needs and requirement.\n\nIt provides cloud hosted web scraping agent to scrape data according to your choice.\nManaged services: Feel free to build, maintain and host your data scraping project. Expert team do all for you.\nExpert Agent Setup: If you don’t know how to setup your agent. Request a setup quote by expert team.\n\nIt has most of the advance feature required in a data..."},{"Answerrer":"Olga Bamatter","Answer":"Divinfosys. COM top web-scraping company in India.They can do amazon and all ecommerce scraping application. if you are looking for a fully managed web scraping service with most affordable web scraping solutions compare to other service provider. There’s are many great web scraping tools out there. These are currently popular tools for collecting web data.\n\nDivinfosys is the right place. They can deliver the data in various popular document formats like XML, excel and CSV and also the websites which are login or PDF\n\nbased too. It is located in India.About my knowledge company in my mind which..."},{"Answerrer":"Halina Makeeva","Answer":"When choosing a crawler services, you need to keep an eye on few things - speed, quality, and price for the product you are about to get. Obviously, would recommend do do your own research on all the available tools and compare them.\nPersonally, from all the tools i have seen available online, Real-Time Crawler by Oxylabs, seems very interesting to me.\nFirst of all, you need to have minimal knowledge of scraping itself, as it offers graphical UI for simple users. Person doesnt need to combine proxies and scraping bot itself, as its just an app, that you install, and are ready to use.\nAs pe..."},{"Answerrer":"Brandon Dotson","Answer":"Divinfosys Software company in India, Best Web Design and Development Company.\n\none of the top web-scraping companies in India. if you are looking for a fully managed web scraping service with most affordable web scraping solutions compare to other service provider.\n\nDivinfosys is the right place. They can deliver the data in various popular document formats like XML, excel and CSV and also the websites which are login or PDF\n\nbased too. It is located in India.About my knowledge company in my mind which has been done 2000 projects done in web scraping.\n\nAlso they can do Ecommerce Based Scraping,Pr..."},{"Answerrer":"Ishtiaq","Answer":"Greetings of the day,\n\nWell, as per my experience, Botscraper is the best provider of data scraping services. I know, a lot of people would have told you that hiring professional data scraping experts will be very costly for you and you should get automated data scraping tools to get the job done.\n\nIf that’s true, know that automated data scraping tools would not be able to scrape data from certain websites, but, data scraping experts can develop custom scrappers to scrape any websites to get the information that you require. That being said, I would also like to let you know that web scraping ..."},{"Answerrer":"X-Byte Enterprise Crawling","Answer":"Best data scraping service? Best is a subjective term to use here, most people would recommend the web scraping service they represent or work for without highlighting what makes a good web scraping service or tool.\n\nTo the Op, what you need is a good web scraper that’s able to handle all your web scraping tasks and requests while delivering optimum quality at the fastest rate possible.\n\nHere are things you should consider when selecting your ‘best’ web scraper:\n\nSpeed.\nSupported webpage types.\nQaulity of scrapped data.\nPrice.\nAbility to handle web scraping challenges.\nSupport for Anonymity?\nHow fast c..."},{"Answerrer":"Rajesh Rajonia","Answer":"Octoparse is a good bet if you are not that well rounded when it comes to scraping. The software is quite self explanatory and user friendly (there’s loads of tutorials and such if something is unclear).\n\nAnother thing that you will need is some kind of pool of residential proxies, as sending a more than a few automated requests will result in your IP address being blocked (data center ones can work on some websites too, but most pages have a somewhat sophisticated security measures which are reacting to IP addresses which does not look like unique human visitors)."},{"Answerrer":"Prithwi Mondal","Answer":"Data scraping is the same as web harvesting and web data extraction. It essentially means gathering data from websites. This type of software can access the internet through a web browser or a HTP. There are many different kinds of data scraping but it really just means accumulating information from other sites, some can be significantly sketchier than others.\n\nThe site I use to get intensive eCommerce data is Algopix. Algopix analyzes over 16 global marketplaces. Their data includes real-time transactions from all the site and is run through proprietary algorithms to provide you with product..."},{"Answerrer":"Norman Dicerto","Answer":"You guys can check ( Webnyze: Fully Managed Web Scraping Service ).\nThey are best of best and quick response and clean data delivery which keep them on top.\n\nFollowing are some Features that webnyze Provides:\n\nAlso in website their is a live price tracking Graph/Visualisation is present for Uk and German ( Iphone x and Iphone x Max )\n\nTo check this live visualisation click on following link: Iphone x and Max Live Price Change Graph\n\nTo Download Free Sample Data refer following link : Data Visualization | Webnyze\n\nFor more Details you can submit form\nHarry Bajwa\nClick to submit"},{"Answerrer":"Preetish Panda","Answer":"There are many great data scraping services out there.\n\nIn order to choose the best you need to follow these criteria:\n\nReliability\nWell-established companies tend to have years of successful experience behind their back. Naturally, they are the best fit.\n\nSpeed\nThis one explains itself. The faster- the better.\n\nPrice\nThe most sensitive part is the cost of the service. Price is very important, especially for a small company or a startup, who can't go around and splash the cash.\n\nI strongly recommend DataHen. You can request a Free Quote, and they will tell you how much the scraping service cost and..."},{"Answerrer":"Aisha Danna","Answer":"In today's era, as all knows data is oil. For better market analysis , Market research and expand your business growth you must review data statics.\n\nYou have to build your database for perfect analysis\n\nWeb scraping technique best for devlope your database.\n\nData iSolutions is a one of top companies in India who has been serving IT - BPO services (Web Scraping Service) for last 15 years.\n\nData iSolutions India's well known outsourcing company who is providing web scraping service in affordable price with excellent quality of work.\n\nWith use of, latest technology(Python, VBA, Ruby and Aws Cloud) Data..."},{"Answerrer":"Rajendra Parouha","Answer":"Data is the core of any business. No great business decisions have ever been made on qualitative data. Every business in some way or the other depends on data to help them make decisions. This is a data-driven world and businesses needs to be constantly vigilant and updated with the data. And Binaryfolks knows to scrape any data, any size, anywhere - Automatically!\n\nLet me at this very initial stage clarify that there is no magic web scraping tool available that will extract data from each and every website on the web. Every website is different in terms of structure, navigation, coding and h..."},{"Answerrer":"Igor Savinkin","Answer":"I believe that it really depends on what are your needs and what kind of web scraper you’re looking for - what features it should have, for what reason you going to use it, the price and much more.\n\nFro my own experience I would recommend checking Scrapy and/or BeautifulSoup. I found both of these tools easy to work with, user-friendly (so you don’t need to have an advanced level of knowledge on how to program the tool), fast and the best part is that both of the tools can work with complexed websites without any problems the same way like with the easy-ones.\n\nThey also work perfectly fine with..."},{"Answerrer":"Brandon Dotson","Answer":"As a university student, I am working with a huge amount of data every day. Occasionally, I found such statistics of Seagate: “The global datasphere will grow from 33 zettabytes in 2018 to 175 by 2025”. That makes me scary and motivational at the same time, so I thought about using web scraping services.\n\nWeb scraping service provides customers with actual, accurate, structured data. Companies who offer web scraping services would help you to find data sources with the most up-to-date, clear information, rank them for quality and as a result receive data in various popular formats like CSV, X..."},{"Answerrer":"Niko Nikolai","Answer":"Parsers is a web scraper does not require programming skills. Parsers is an extension in Chrome web store. With web scraper you can download more than 1000 pages for free! You only need to install the extension, go to the desired site (be sure to go to the product card page, not the catalog!) select the necessary data and run the web scraper."},{"Answerrer":"Mikhail Sisin","Answer":"“Best” depends on many things.\n\nThere are so many companies offering web scraping and every one claims to be the best, so no one actually knows here who is the best service, Its better to discuss your project with few providers before hiring some one.\n\nYou can search on google to get some companies who offer web scraping, contact some of them, give them details of what you need and ask for price quote. Web scraping is usually expensive because it requires custom software development.\n\nDisclosure: I work at BotSol | Ultimate Web Scraping Service"},{"Answerrer":"Camila Guimaraes","Answer":"X-Byte Enterprise Crawling is the Best Data Scraping Services provider that scrapes or extracts data from different websites. They provide professional web scraping services by extracting various kinds of data from websites quickly and effectively. There are many procedures of web scrapping which work automatically through data scraping. All the methods involve HTTP (Hyper Text Transfer Protocol) or entrenching the browser from which the users search the internet.\n\nThe Benefit of Web Scraping Services\n\nThe key benefits of hiring X-Byte Enterprise Crawling for Web Scraping Services are as under:\n\n..."},{"Answerrer":"Tuan Nguyen","Answer":"Hello there,\n\nAs per my experience, I would personally state that Botscraper is the best web scraping service provider. They are highly talented and the most professional web scraping experts. Their quality of work is also impeccable. Noteworthy to mention, the scrapped data that Botscraper delivered me was accurate and relevant to my industry to the utmost level.\n\nHaving said that, I would also like to inform you that hiring web scraping services is much more cost-efficient and fast as compared to hiring a researcher or using any automated tools. Some business owners prefer to use automated to..."},{"Answerrer":"Eugene K","Answer":"PromptCloud’s web scraping service geared towards large-scale and recurring (daily/weekly/monthly) requirements. We have in business for more than 10 years and have become adept at web scraping techniques with a talented team of developers along with robust infrastructure.\n\nHere are the solutions:\n\nSite-specific web data extraction\nDataStock (instant web dataset downloads)\nLive crawling\nJobsPikr (job data feeds from thousands of sites updated on daily basis)"},{"Answerrer":"Stepan Aslanyan","Answer":"From my experience, I would recommend you to take a look at Scrapy and BeautifulSoup. Both are pretty easy to understand and work with, has great features and I found them very useful while scraping data from various websites.\nYou can also check Octopares or Scrapinghub that offers lots of features but sometimes might be a bit difficult, especially for those who doesn’t have much knowledge about web scraping and programming.\n\nAnd don’t forget about proxies and how useful they can be while working with web scraping tools. Even if it isn’t a necessity but using proxy services while web scraping..."},{"Answerrer":"Nikolai Kekish","Answer":"Disclosure: I work at PromptCloud — a Data as a Service provider.\n\nIf you are looking for enterprise-grade data extraction service, then it is better to go with a managed service provider like PromptCloud. We have been in the web data extraction business for close to 8 years now and have developed domain-specific knowledge to acquire clean data from various complex sites.\n\nReach out to us in case of recurring and large-scale web data requirement."}]
Real world scraping examples
Scraping Hacker News
we are going to see how we can scrape Hacker News posts using Python and BeautifulSoup in a simple and elegant manner.
The aim of this section is to get you started on a real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed.
Then you can install beautiful soup with...
pip3 install beautifulsoup4We will also need the libraries requests, lxml and soupsieve to fetch data, break it down to XML, and to use CSS selectors. Install them using...
pip3 install requests soupsieve lxmlOnce installed open an editor and type in...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requestsNow let's go to the Hacker News home page and inspect the data we can get.
This is how it looks:
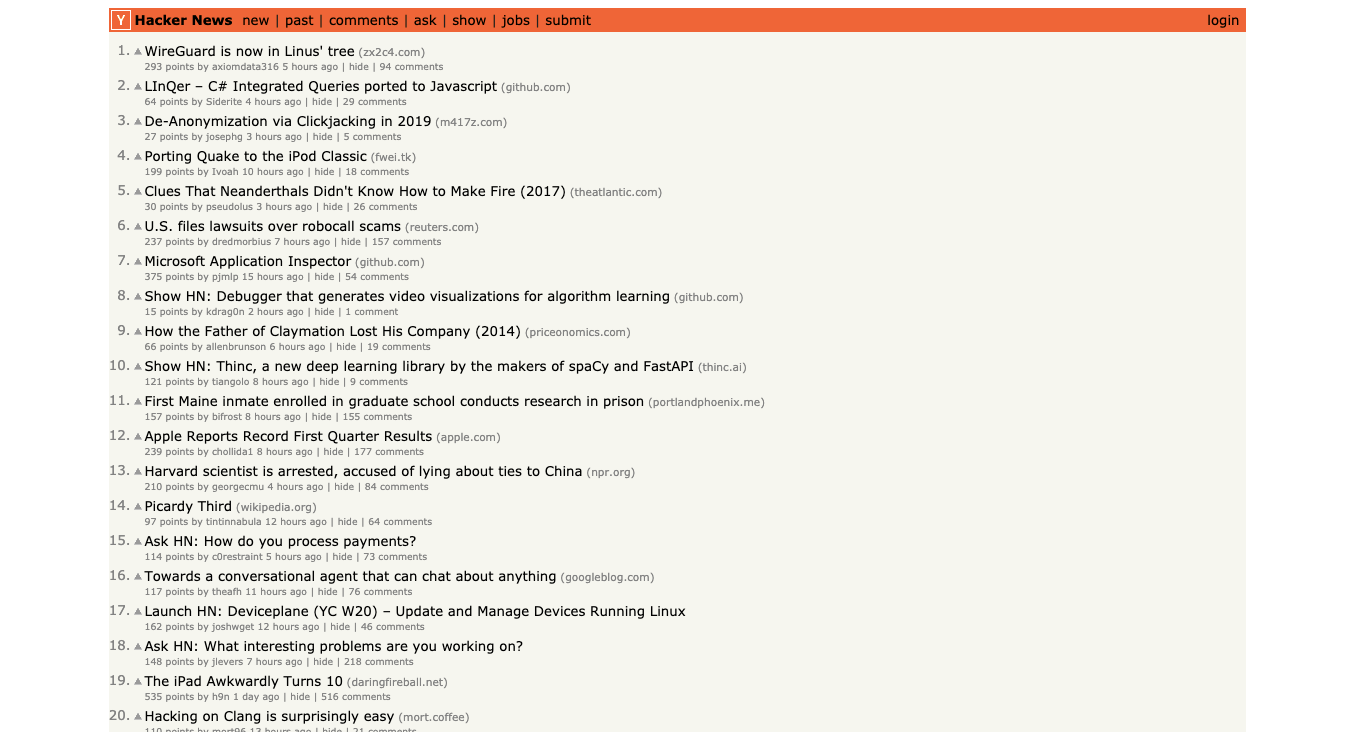
Back to our code now... let's try and get this data by pretending we are a browser like this...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://news.ycombinator.com/'
response=requests.get(url,headers=headers)
print(response)Save this as HN_bs.py.
If you run it...
python3 HN_bs.pyYou will see the whole HTML page
Now let's use CSS selectors to get to the data we want... To do that let's go back to Chrome and open the inspect tool. We now need to get to all the posts... We notice that the data is arranged in a table and each post uses 3 rows to show the data.
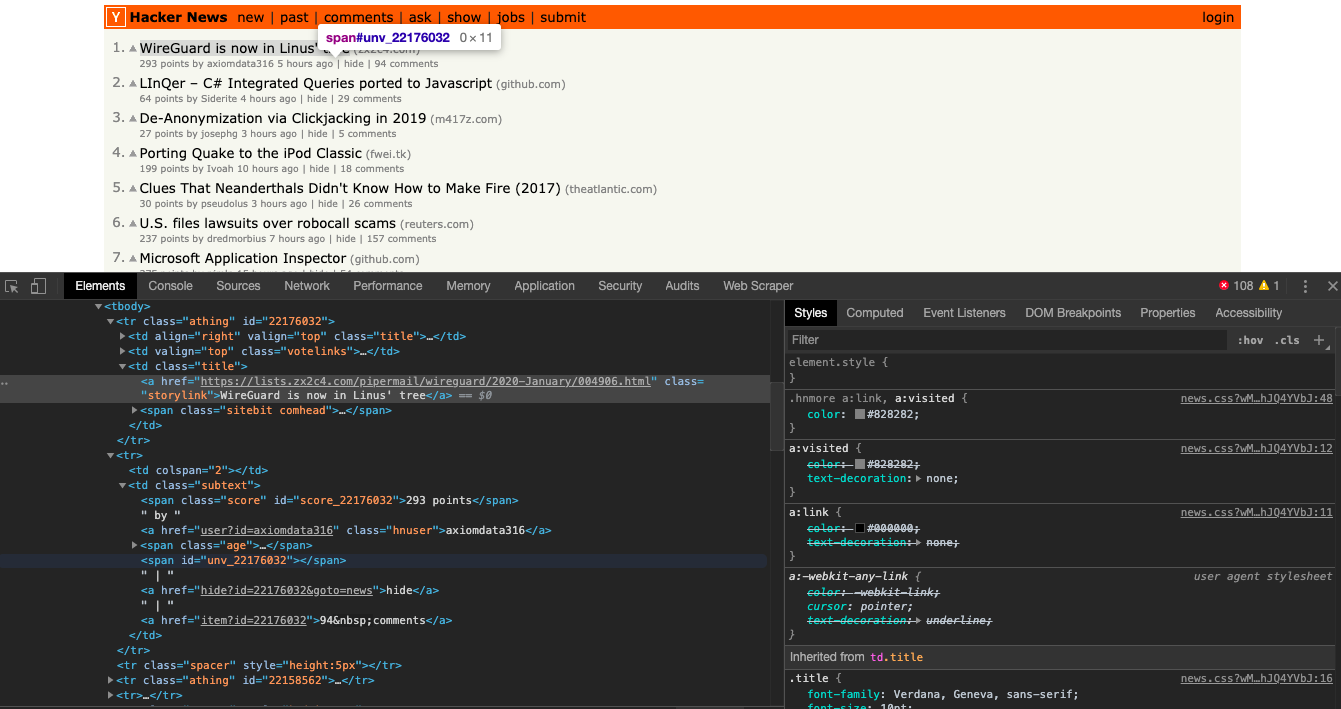
We have to just run through the rows to get data like this...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://news.ycombinator.com/'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.find_all('tr'):
try:
print(item)
except Exception as e:
raise e
print('')This prints all the content in each of the rows. We now need to be smart about the kind of content we want. The first row contains the title. But we have to make sure we dont ask for content from the other rows so we put in a check like the one below. The storylink class contains the title of the post so the code below makes sure the class exists in THIS row before asking for the text of it...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://news.ycombinator.com/'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.find_all('tr'):
try:
#print(item)
if item.select('.storylink'):
print(item.select('.storylink')[0].get_text())
except Exception as e:
raise e
print('')If you run it. This will print the titles...
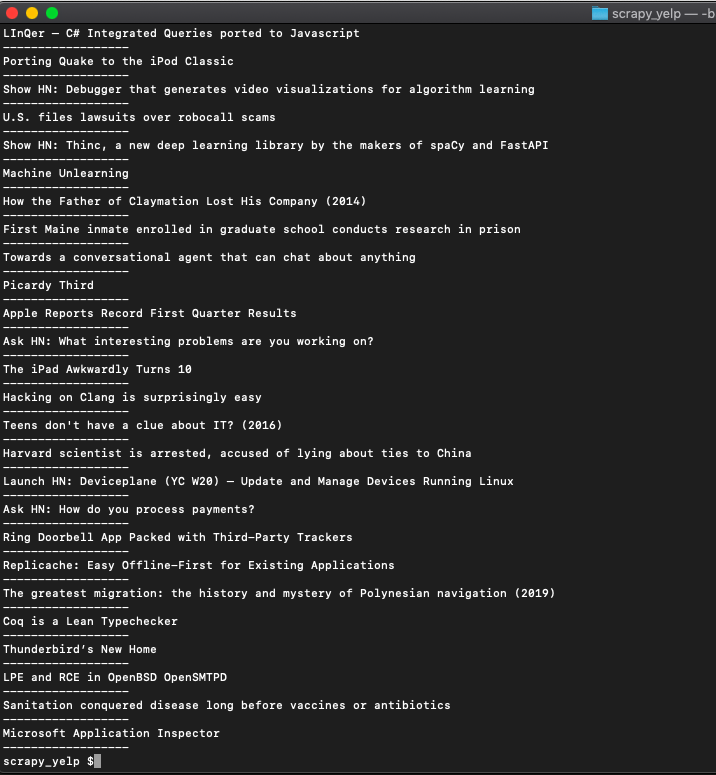
Bingo!! we got the post titles...
Now with the same process, we get the other data like a number of comments, HN user name, link, etc like below.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://news.ycombinator.com/'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.find_all('tr'):
try:
#print(item)
if item.select('.storylink'):
print(item.select('.storylink')[0].get_text())
print(item.select('.storylink')[0]['href'])
if item.select('.hnuser'):
print(item.select('.hnuser')[0].get_text())
print(item.select('.score')[0].get_text())
print(item.find_all('a')[3].get_text())
print('------------------')
except Exception as e:
raise e
print('')Notice that for getting the comments we try and find the fourth link inside the block that contains the hnuser details like so
item.find_all('a')[3].get_text()
That when run, should print everything we need from each post like this.
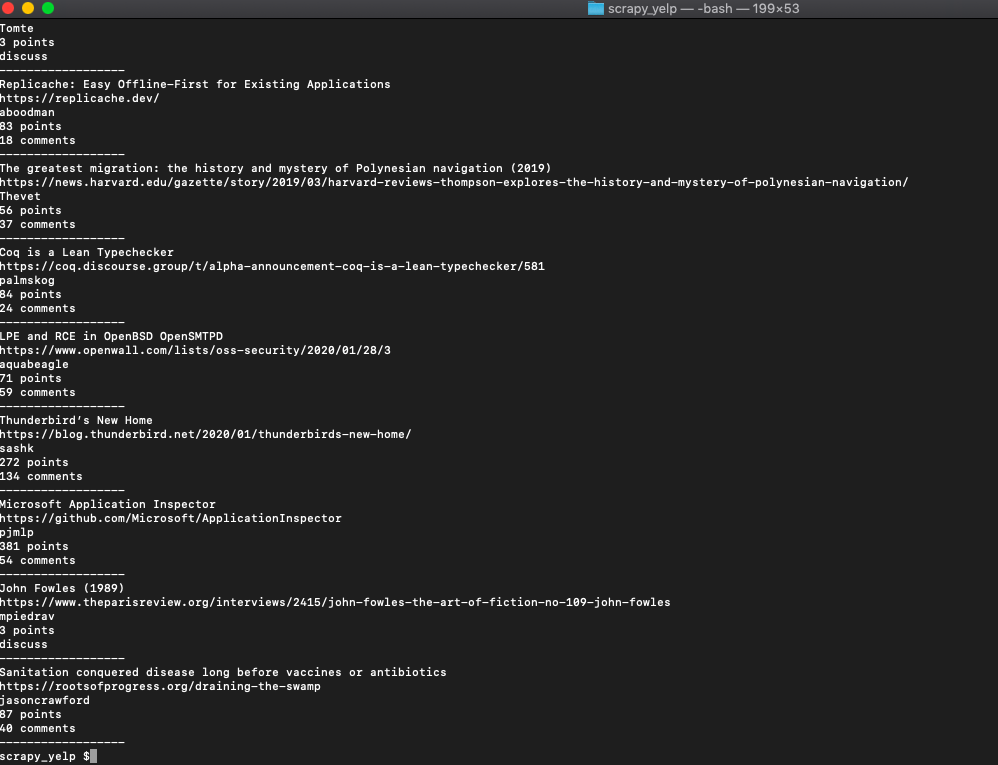
We even added a separator to show where each post ends. You can now pass this data into an array or save it to CSV and do whatever you want.
Yelp scraping
we are going to see how we can scrape Yelp data using Python and BeautifulSoup in a simple and elegant manner.
The aim of this article is to get you started on a real-world problem solving while keeping it super simple so you get familiar and get practical results as fast as possible.
So the first thing we need is to make sure we have Python 3 installed. If not, you can just get Python 3 and get it installed before you proceed. Then you can install beautiful soup with...
pip3 install beautifulsoup4
We will also need the libraries requests, lxml and soupsieve to fetch data, break it down to XML, and to use CSS selectors. Install them using.
pip3 install requests soupsieve lxml
Once installed open an editor and type in.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
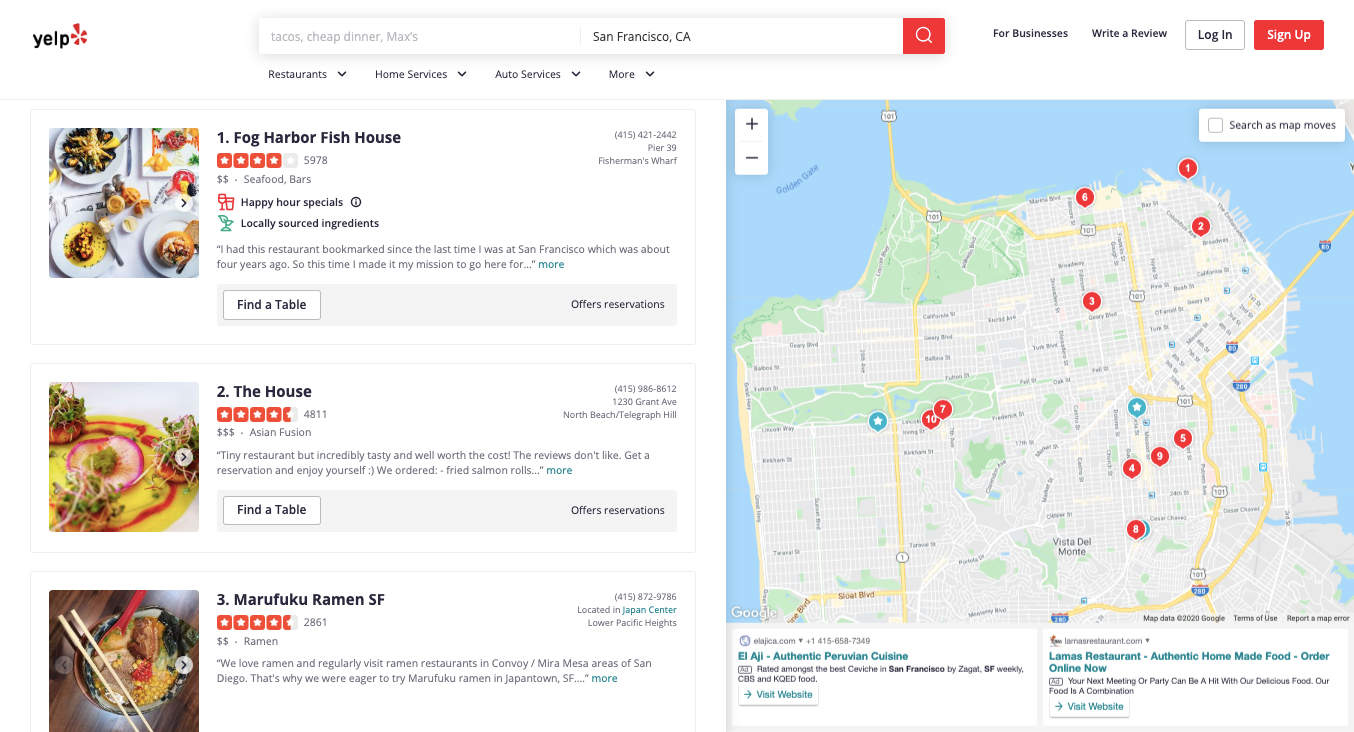
Now let's go to the Yelp San Fransisco restaurants listing page and inspect the data we can get.
This is how it looks:
Back to our code now. Let's try and get this data by pretending we are a browser like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.yelp.com/search?cflt=restaurants&find_loc=San Francisco, CA'
response=requests.get(url,headers=headers)
print(response)
Save this as yelp_bs.py.
If you run it.
python3 yelp_bs.py
You will see the whole HTML page
Now, let's use CSS selectors to get to the data we want. To do that let's go back to Chrome and open the inspect tool.
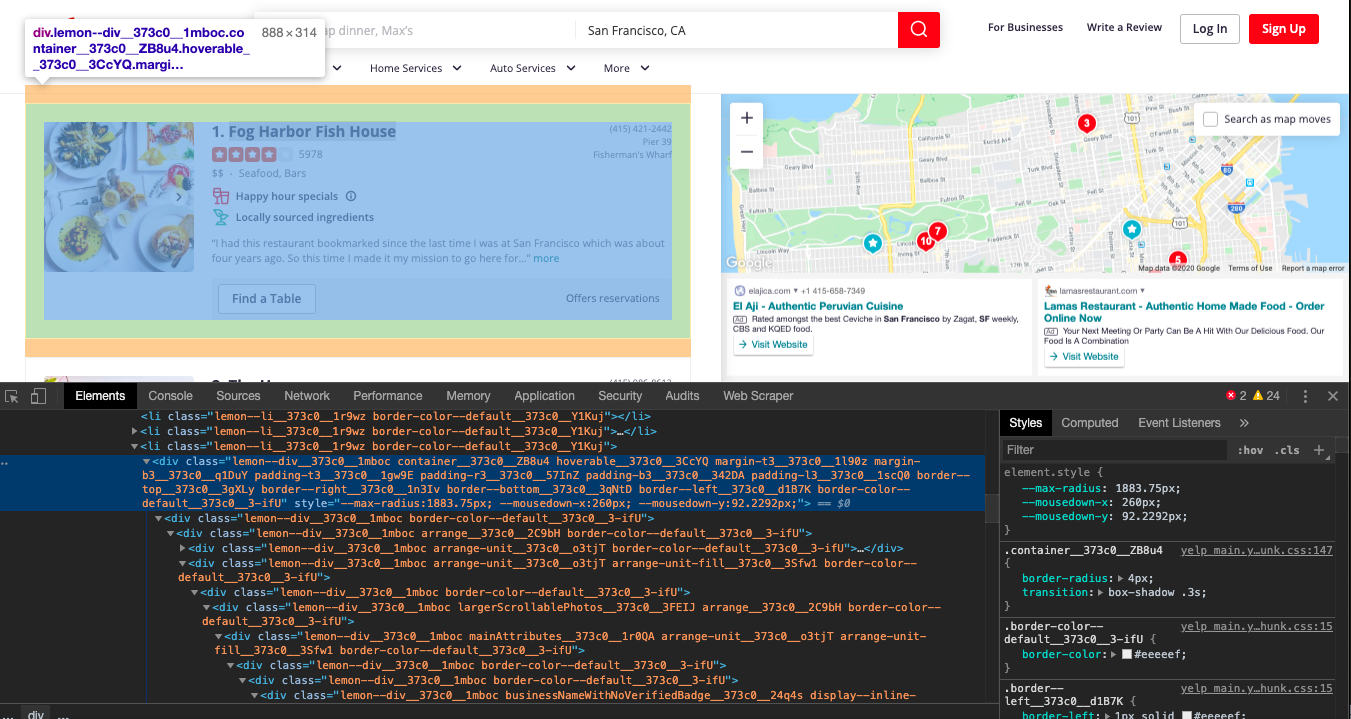
We notice that all the individual rows of data are contained in awith the class 'container along with other jibberish before and after it. This is good enough for us to scrape it. We can get BeautifulSoup to select the data that has the word inside its class definition anywhere with the * operator like this.
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.yelp.com/search?cflt=restaurants&find_loc=San Francisco, CA'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[class*=container]'):
try:
print(item)
except Exception as e:
raise e
print('')# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.yelp.com/search?cflt=restaurants&find_loc=San Francisco, CA'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[class*=container]'):
try:
#print(item)
if item.find('h4'):
name = item.find('h4').get_text()
print(name)
print('------------------')
except Exception as e:
raise e
print('')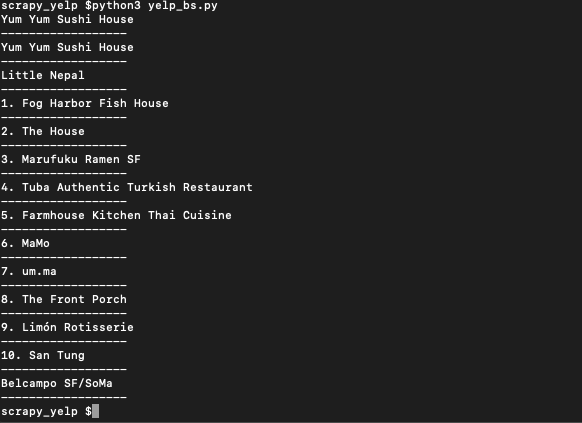
Bingo!! we got the names...Now with the same process, we get the other data like phone, address, review count, ratings, price range etc...
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9'}
url='https://www.yelp.com/search?cflt=restaurants&find_loc=San Francisco, CA'
response=requests.get(url,headers=headers)
soup=BeautifulSoup(response.content,'lxml')
for item in soup.select('[class*=container]'):
try:
#print(item)
if item.find('h4'):
name = item.find('h4').get_text()
print(name)
print(soup.select('[class*=reviewCount]')[0].get_text())
print(soup.select('[aria-label*=rating]')[0]['aria-label'])
print(soup.select('[class*=secondaryAttributes]')[0].get_text())
print(soup.select('[class*=priceRange]')[0].get_text())
print(soup.select('[class*=priceCategory]')[0].get_text())
print('------------------')
except Exception as e:
raise e
print('')
so we get it with this line.. it selects the element with the attribute aria-label but only ones that have the word label in them and then goes onto to ask for its aria-label attribute value... loved writing this one...
print(soup.select('[aria-label*=rating]')[0]['aria-label'])
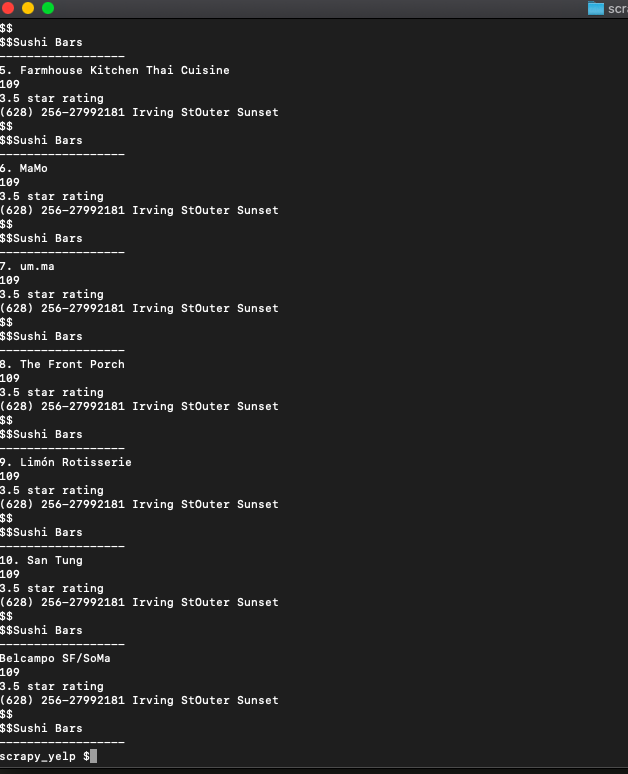
We even added a separator to show where each restaurant detail ends. You can now pass this data into an array or save it to CSV and do whatever you want.
Advanced web scraping
Speeding up the crawler: Synchronous and Asynscronous web scraping
One of the features of our Rotating Proxy Service Proxies API is the enormous concurrency it offers straight from the free plan itself. This is because we wanted the ability to scale our customer's web scrapers to be there from moment one. People do ask us what is the best way to make concurrent requests on their side. So we thought we would put together a getting started code that helps you understand and get started with async requests in Python.
To properly understand them, however, let's look at the differences between a normal, synchronous approach as compared to an asynchronous one.
To fetch URLs sequentially, we will use the requests module in python.
import requestsLets store all the URLs in an array-like so...
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']The simple function uses the requests.get function to get the URLs one by one and calculate the time taken for each and also for the total.
from timeit import default_timer
import requests
def get_urls(urls):
start_time = default_timer()
for url in urls:
start_time_url = default_timer()
_ = requests.get(url)
elapsed = default_timer() - start_time_url
print(url ' took ' str(elapsed))
tot_elapsed = default_timer() - start_time
print('Total time taken for all : ' str(tot_elapsed))
if __name__ == '__main__':
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']
get_urls(urls)And when we run it we get something like...
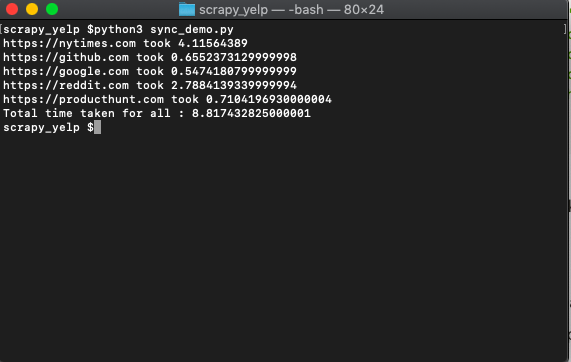
The whole thing runs one after the other and takes around 8.8 seconds on my machine.
Now let's see if we can do this the Asynchronous way.
Async is a better option than multi-threading because it's very difficult to write thread-safe code.
So here is an example of fetching multiple URLs simultaneously using aiohttp module.
We will try and fetch all the URLs from this array...
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']First, we will initialize everything by loading the modules we need...
import asyncio
from timeit import default_timer
from aiohttp import ClientSession
import requestsWe need a function to handle individual fetches.
async def fetch(url, session):
fetch.start_time[url] = default_timer()
async with session.get(url) as response:
r = await response.read()
elapsed = default_timer() - fetch.start_time[url]
print(url ' took ' str(elapsed))
return rNotice how we use the start_time is stored in an array for each URL and the time taken is calculated and printed.
The fetch_urls calls the ensure_future function to make sure the URLs finish fetching.
async def fetch_all(urls):
tasks = []
fetch.start_time = dict()
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
_ = await asyncio.gather(*tasks)The fetch_async sets up the event loops and uses the run_until_complete to wait till all the URL fetches are completed to pass the control back so we can print the total time taken...
def fetch_async(urls):
start_time = default_timer()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_all(urls))
loop.run_until_complete(future)
tot_elapsed = default_timer() - start_time
print('Total time taken : ' str(tot_elapsed))Putting it all together...
import asyncio
from timeit import default_timer
from aiohttp import ClientSession
import requests
def fetch_async(urls):
start_time = default_timer()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_all(urls))
loop.run_until_complete(future)
tot_elapsed = default_timer() - start_time
print('Total time taken : ' str(tot_elapsed))
async def fetch_all(urls):
tasks = []
fetch.start_time = dict()
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
_ = await asyncio.gather(*tasks)
async def fetch(url, session):
fetch.start_time[url] = default_timer()
async with session.get(url) as response:
r = await response.read()
elapsed = default_timer() - fetch.start_time[url]
print(url ' took ' str(elapsed))
return r
if __name__ == '__main__':
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']
fetch_async(urls)And when you run it...
python3 async.pyYou get..
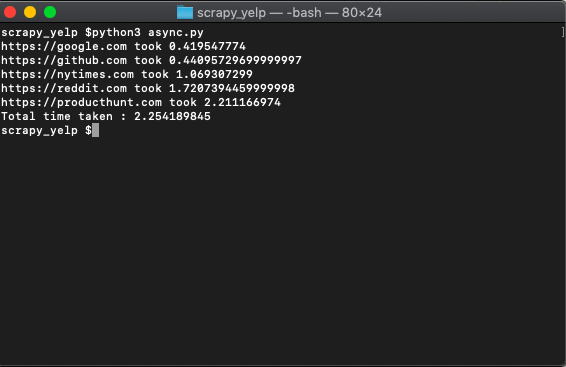
That's much faster than doing it synchronously which took 8.8 seconds earlier.
Further reading...
Scraping multiple pages
lets see how we can solve one of the most common design patterns while scraping any large scale projects like scraping article list or blog posts. Typically, the number of items shown on a single page is limited to 10 or 20 and you will want to pull out all the pages as automatically as possible.
We will take the example of the CopyBlogger blog and see if we can run through all the pages without much sweat. We will do this and do it using a powerful tool like Scrapy because once we have this basic infrastructure, we will be able to build almost anything on top of it.
Here is how the CopyBlogger blog section looks:
You can see that there are about 10 posts on each page and then there are about 329 pages in total.
First, we need to install scrapy if you haven't already
pip install scrapyOnce installed, we will add a simple file with some barebones code like so...
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):Let's examine this code before we proceed...
The allowed_domains array restricts all further crawling to the domain paths specified here.
start_urls is the list of URLs to crawl... for us, in this example, we only need one URL.
The LOG_LEVEL settings make the scrapy output less verbose so it is not confusing.
The def parse(self, response): function is called by scrapy after every successful URL crawl. Here is where we can write our code to extract the data we want.
Now let's see what we can write in the parse function...
For this let's find the CSS patterns that we can use as selectors for finding the next page link on any page.
We will not use the page links titled 1,2,3 for this. It makes more sense to find the link inside the 'Next Page' button. It should then ALWAYS lead us to the next page reliably.
When we inspect this in the Google Chrome inspect tool (right-click on the page in Chrome and click Inspect to bring it up), we can see that the link is inside an LI element with the CSS class pagination-next. This is good enough for us. We can just select this using the CSS selector function like this...
nextpage = response.css('.pagination-next').extract()This will give us the text 'Next Page' though. What we need is the href in the 'a' tag inside the LI tag. So we modify it to this...
nextpage = response.css('.pagination-next a::attr(href)').extract()In fact, the moment we have the URL, we can ask Scrapy to fetch the URL contents like this
yield scrapy.Request(nextpage[0], callback=self.parse_next_page)So the whole code looks like this:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):
print('Current page ' response.url)
nextpage = response.css('.pagination-next a::attr(href)').extract()
nextpagetext = response.css('.pagination-next').extract()
yield scrapy.Request(nextpage[0], callback=self.parse_next_page)
return
def parse_next_page(self, response):
print('Fetched next page' response.url)
returnLet's save it as SimpleNextPage.py and then run it with these parameters which tells scrapy to disobey Robots.txt and also to simulate a web browser...
scrapy runspider SimpleNextPage.py -s USER_AGENT="Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36" -s ROBOTSTXT_OBEY=FalseWhen you run it should return...
We dont have to stop there. Let's make these function recursive. For that, we can do away with the parse_next_page function altogether and ask the Parse function to parse all the next page links.
Here is the final code:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from bs4 import BeautifulSoup
import urllib
class SimpleNextPage(CrawlSpider):
name = 'SimpleNextPage'
allowed_domains = ['copyblogger.com']
start_urls = [
'https://copyblogger.com/blog/',
]
custom_settings = {
'LOG_LEVEL': 'INFO',
}
def parse(self, response):
print('Current page ' response.url)
nextpage = response.css('.pagination-next a::attr(href)').extract()
nextpagetext = response.css('.pagination-next').extract()
yield scrapy.Request(nextpage[0], callback=self.parse)
return
def parse_next_page(self, response):
print('Fetched next page' response.url)
returnAnd the results:
It will fetch all the pages which you can parse, scrape or whatever other function you may want to perform on them.
How to build a production-level, truly hands-off web scraper
A lot of programmers think that building a web crawler/scraper is all about the code. It's mostly not. The robustness of your project depends mainly on other factors, in our opinion. Here are the boxes you need to check to build something that truly scales, that you can rely on, is consistent, rarely breaks, is easy to diagnose and debug, and doesn't give you the midnight emergency alert.
Use a framework: Use Beautifulsoup or scrapy or Nutch. Anything. Anything that has thousands of lines of code by hundreds of coders who do large web scraping projects for years, to take care of all the weird exceptions that happen when you are dealing with something as unpredictable as the web. If your scraper is hand-coded, I am sorry to say this, and you have hard times coming.
Take a lot of measures to pretend to be human.
Build multiple checks in your web crawler that monitors the health of your crawler and fires an alert to you.
Here is a list of places that your web crawler will probably fail
- The web pages dont load
- Internet is down
- When the content at the URL has moved
- You are shown a CAPTCHA challenge.
- The web page changes its HTML, so your scraping doesn't work.
- Some fields that you scrape are empty some of the time, and there is no handler for that.
- The web pages take a long time to load
- The web site has blocked you completely.
- Just use a professional third party Rotating Proxy Service to avoid the inevitable IP block. There is no getting around it. We have tried it for years.We have tried it all. That's why we built the Proxies API. It will rotate proxies with a pool of a couple of million private residential proxies. Rotates user-agents retries requests automatically, solve captchas, renders AJAX pages. Problems you should not be solving and won't be able to without massive investments.
Is it rotating user-agents? Yes. It will cut you some slack for a while, but your IP address is right there for them to block and they will
Have 4-5 IPs from different machines or servers? Yes. For a while. After that, they will ALL get blocked.
Use publicly available proxies? Sure. They have a life span of about 5 mins because every other hacker around the world is onto them.