Scrapy is one of the most accessible tools that you can use to crawl and also scrape a website with effortless ease.
So let's see how we can crawl Wikipedia data for any topic.
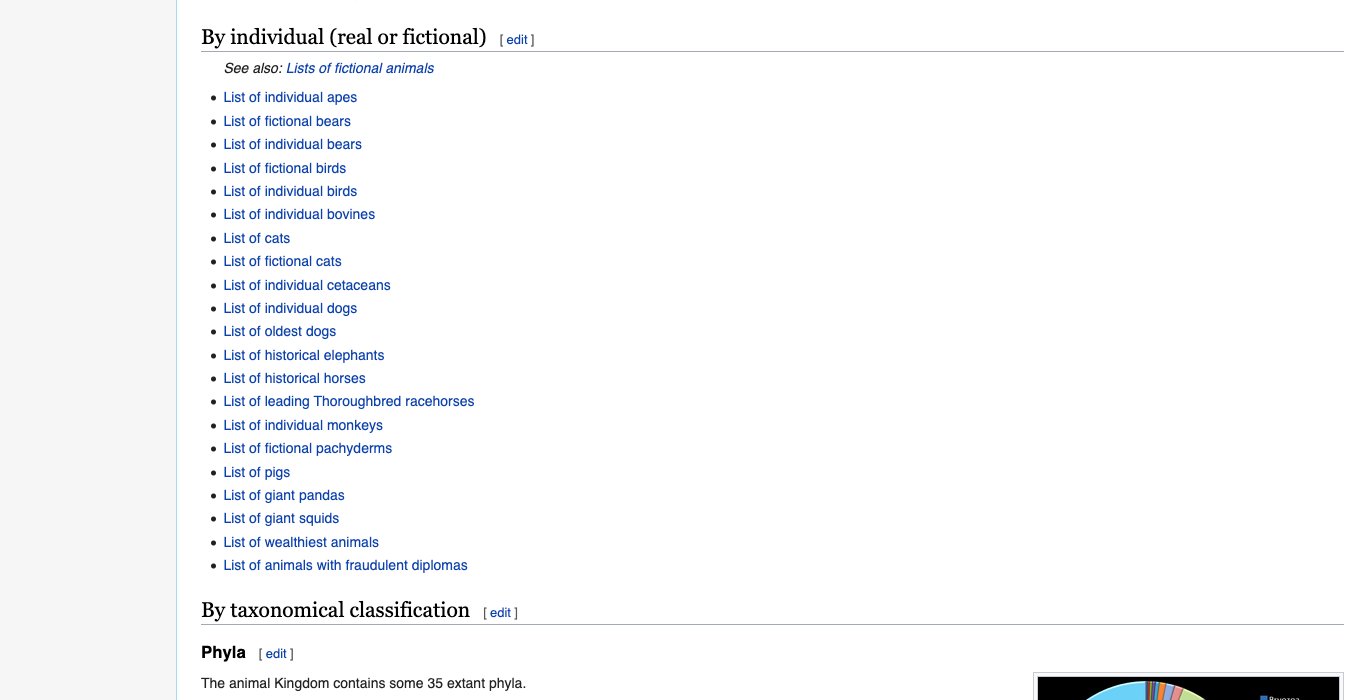
Here is the URL we are going to scrape https://en.wikipedia.org/wiki/Lists_of_animals, which provides a list of lists of different types of animals. We are going to try and spider through this by first downloading this page and then further downloading all further links that point to a subsequent list. We dont want to download any other link. Also, we will avoid any pages that link to pages that talk about bears. We dont want bears.
First, we need to install scrapy if you haven't already.
pip install scrapyThen create a file called fullspider.py and paste the following.
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'Wikipedia'
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Lists_of_animals']
This loads scrapy and the Spider library. We will also need the LinkExtractor module so we can ask scrapy to follow links that follow specific patterns for us.
The allowed_domains variable makes sure that our spider doesn't go off on a tangent and download stuff that's not on the Wikipedia domain. We also just provide the start_url
Now, lets set up the rules.
If you right-click and copy the link address of any of the links that point to other lists, they always seem to follow this pattern.
https://en.wikipedia.org/wiki/List_of_individual_cetaceansYou can see that they always have the string List_of in them.
So now, let's take advantage of this and write this ruleset.
rules = (
# This rule set extracts any link which has the string List_of in it
# also it avoids anything to do with bears. Enough of bears!
#the callback value tells the crawler to invoke the function parse_item below for further processing once the subsequent page is crawled
Rule(LinkExtractor(allow=('List_of', ), deny=('bear', )), callback='parse_item'),
)You can see that the deny array contains the word bear so we can stay away from anything bear-related!
This tells scrapy to download all links inside the starting URLs that obey these rules and then call the function parse_item
so in parse item, we are just going to print the URL that has been downloaded
def parse_item(self, response):
self.logger.info('Downloaded list wiki - %s', response.url)
item = scrapy.Item()
return itemNow lets put the whole thing together
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class MySpider(CrawlSpider):
name = 'Wikipedia'
allowed_domains = ['en.wikipedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Lists_of_animals']
rules = (
# This rule set extracts any link which has the string List_of in it
# also it avoids anything to do with bears. Enough of bears!
#the callback value tells the crawler to invoke the function parse_item below for further processing once the subsequent page is crawled
Rule(LinkExtractor(allow=('List_of', ), deny=('bears', )), callback='parse_item'),
)
def parse_item(self, response):
self.logger.info('Downloaded list wiki - %s', response.url)
item = scrapy.Item()
return itemAnd run it with.
scrapy runspider fullspider.pyIt should output all the links that point to the Lists of animals.
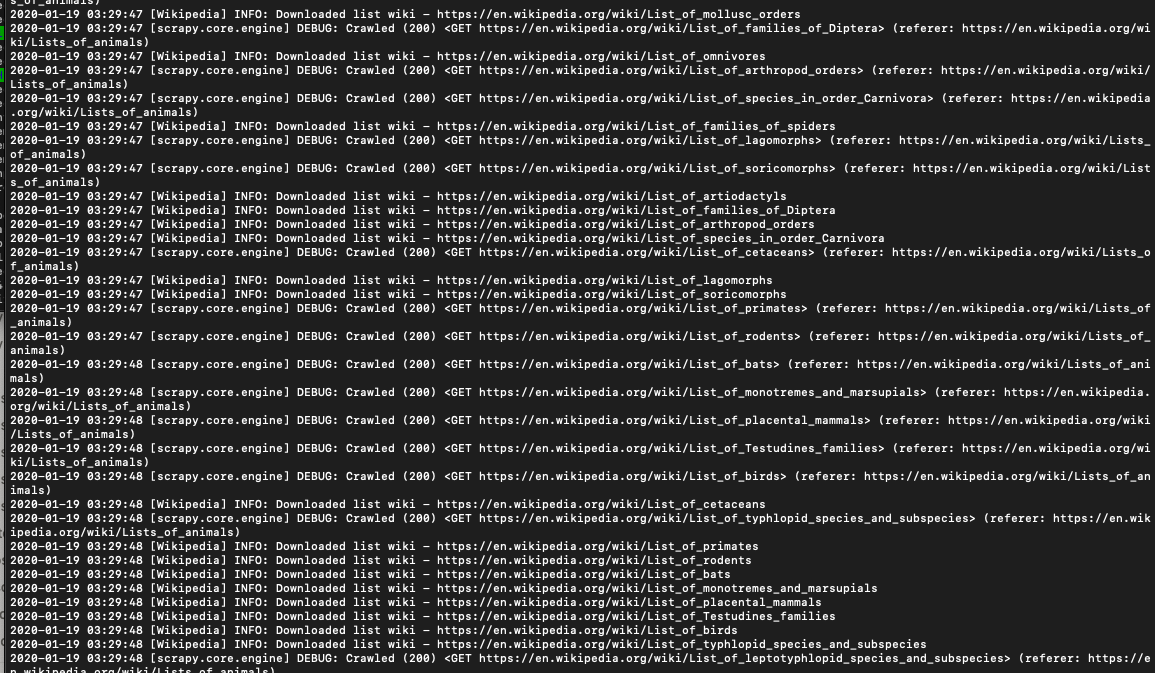
Pretty simple so far. But there is a catch. If you want to scale a web crawler like this to thousands of downloads and if you do it frequently, you will find that you will eventually run into rate limits, CAPTCHA challenges, and even IP blocks pretty soon.
So if you want to scale reliably to thousands of requests, you can consider using a professional Rotating Proxy Service like Proxies API to route requests through millions of anonymous proxies and prevent all the blocking problems.
Proxies API also handles automatic retries, automatic User-Agent-String rotation, solves CAPTCHAs behind the scenes using a simple one-line API call.
We have a running offer of 1000 API calls completely free. Register and get your free API Key here.