Scrapy is one of the most accessible tools that you can use to crawl and also scrape a website with effortless ease.
So let's see how we can crawl Wikipedia data for any topic and download all the images and save it to our disk.
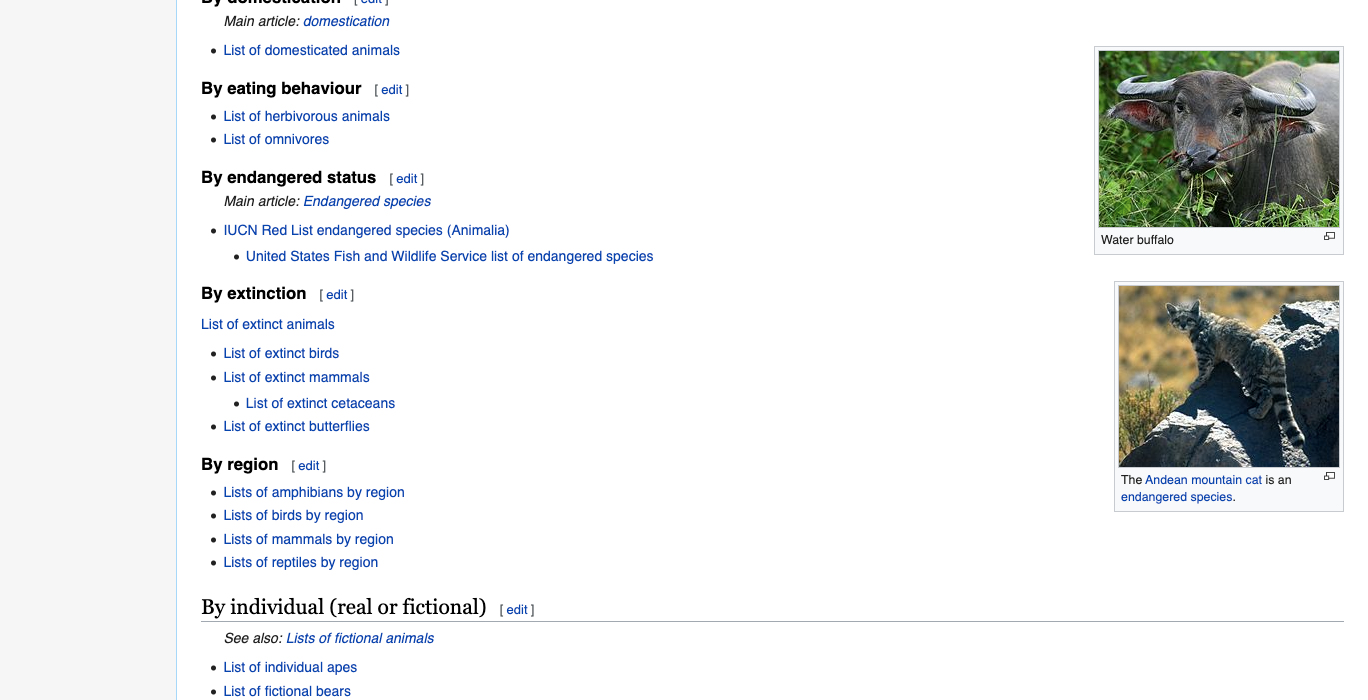
Here is the URL we are going to scrape https://en.wikipedia.org/wiki/Lists_of_animals, which provides a list of lists of different types of animals. We are going to try and spider through this by first downloading this page and then further downloading all other images.
First, we need to install scrapy if you haven't already.
pip install scrapyThen create a file called fullspider.py and paste the following.
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
i=1
class MySpider(CrawlSpider):
name = 'Wikipedia'
allowed_domains = ['en.wikipedia.org', 'upload.wikimedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Lists_of_animals']
It loads scrapy and the Spider library. We will also need the LinkExtractor module so we can ask scrapy to follow links that follow specific patterns for us.
The allowed_domains variable makes sure that our spider doesn't go off on a tangent and download stuff that's not on the Wikipedia domain. Also, the upload.wikimedia.org is where all the images sit. We also just provide the start_url
Now, lets set up the rules.
This ruleset makes sure it downloads anything with the extension .jpg in it and also removes the deny_extensions default setting.
Rule(LinkExtractor(allow=('.jpg'), deny_extensions=set(), tags = ('img',), attrs=('src',), canonicalize = True, unique = True), follow = False, callback='parse_item'),This tells scrapy to download all images and then call the function parse_item
so in parse item, we are just going to save images downloaded to the disk
def parse_item(self, response):
global i
i=i 1
self.logger.info('Found image - %s', response.url)
flname='image' str(i) '.jpg'
with open('image' str(i) '.jpg', 'wb') as html_file:
html_file.write(response.body)
self.logger.info('Saved image as - %s', flname)
item = scrapy.Item()
return itemNow lets put the whole thing together
import scrapy
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
i=1
class MySpider(CrawlSpider):
name = 'Wikipedia'
allowed_domains = ['en.wikipedia.org', 'upload.wikimedia.org']
start_urls = ['https://en.wikipedia.org/wiki/Lists_of_animals']
rules = (
# This rule set makes sure it downloads anything with the extension .jpg in it and also removes the deny_extensions default setting
Rule(LinkExtractor(allow=('.jpg'), deny_extensions=set(), tags = ('img',), attrs=('src',), canonicalize = True, unique = True), follow = False, callback='parse_item'),
)
def parse_item(self, response):
global i
i=i 1
self.logger.info('Found image - %s', response.url)
flname='image' str(i) '.jpg'
with open('image' str(i) '.jpg', 'wb') as html_file:
html_file.write(response.body)
self.logger.info('Saved image as - %s', flname)
item = scrapy.Item()
return itemAnd run it with.
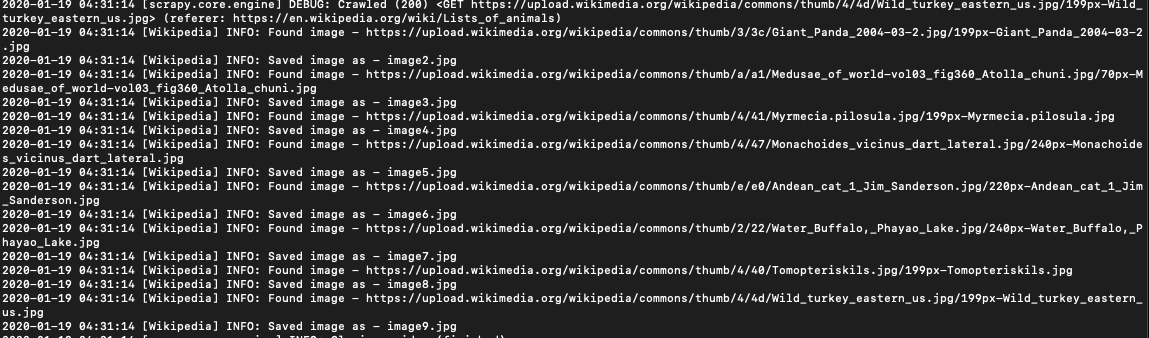
scrapy runspider fullspider.pyIt should output that the files have been saved successfully.
This technique will work on almost any website. But if you want to scale this, you will need to overcome the inevitable IP block.
Consider using a professional Rotating Proxy Service like Proxies API to route requests through millions of anonymous proxies to scale your web projects.
Proxies API also handles automatic retries, automatic User-Agent-String rotation, solves CAPTCHAs behind the scenes using a simple one-line API call.
We have a running offer of 1000 API calls completely free. Register and get your free API Key here.