If you dont already know it, the opensource Goutte library makes scraping complex
To scrape Craigslist, we will be using the open-source Craigslist wrapper python-craigslist
First, we need to download and extract the python-craigslist module source from here https://github.com/juliomalegria/python-craigslist
Do not install it using the pip installer as recommended by the page. This is because we are going to change the source to enable it to scale to our benefit later.
Once extracted, open terminal and cd to the folder and install the code manually like this.
python setup.py developNow import the module into your code.
from craigslist import CraigslistHousingNot that this imports the Housing section crawler into your code
Here are more subclasses you can import depending on your needs.
CraigslistCommunity (craigslist.org > community)
CraigslistHousing (craigslist.org > housing)
CraigslistJobs (craigslist.org > jobs)
CraigslistForSale (craigslist.org > for sale)
CraigslistEvents (craigslist.org > event calendar)
CraigslistServices (craigslist.org > services)
CraigslistGigs (craigslist.org > gigs)
CraigslistResumes (craigslist.org > resumes)Going back to the housing subclass, here is how you can scrape housing listings in San Fransisco
from craigslist import CraigslistHousing
cl_h = CraigslistHousing(site='sfbay', area='sfc', category='roo',
filters={'max_price': 1800, 'private_room': True})
for result in cl_h.get_results(sort_by='newest', geotagged=True):
print(result)Save this in a file called craigslist_scraper.py and run it by.
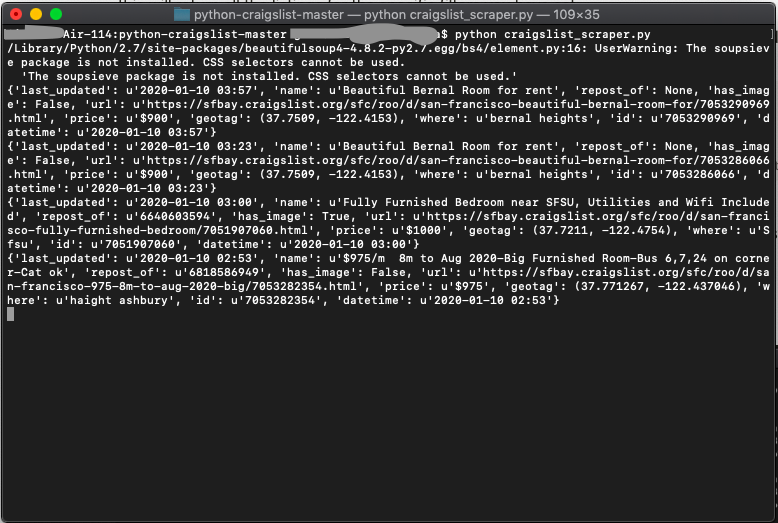
python craigslist_scraper.pyThis will return all the listings for the specific filters you have set, like in the screenshot below.
Notice that the filter names and values are specific to the category. The library has a method that will tell you all available filters for a category. You can access it by calling.
>>> from craigslist import CraigslistGigs
>>> CraigslistGigs.show_filters()So far, so good. But this library works only for small scale projects. If you scrape a lot of data, Craigslist will likely just block you. In that case, you need a rotating proxy that can handle proxy rotation, user-agent-spoofing to enable you to download large quantities of data.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world
- With our automatic IP rotation
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
- With our automatic CAPTCHA solving technology
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
A simple API can access the whole thing like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"Register for free and get your free API Key here before proceeding with the next steps.
Great. Now that you have a Proxies API AuthKey, you are all set.
Lets now edit the source code and ask the module to route all the requests through the Proxies API endpoint.
For that cd to the craigslist directory
Open the base.py file for editing
Here we are going to route all requests through the Proxies API endpoint.
This should happen whenever the requests_get function is called. Its called at two essential points in the code.
Here is how we are going to change it.
This is the original.
def fetch_content(self, url):
response = requests_get(url, logger=self.logger)
self.logger.info('GET %s', response.url)
self.logger.info('Response code: %s', response.status_code)
if response.ok:
return bs(response.content)
return NoneWe will now add the proxy endpoint.
def fetch_content(self, url):
proxy_url='http://api.proxiesapi.com/?auth_key=dad407ce98b274996060fc03c714b6ae_sr98766_ooPq87&url=' urllib.quote_plus(url)
response = requests_get(proxy_url, logger=self.logger)
self.logger.info('GET %s', response.url)
self.logger.info('Response code: %s', response.status_code)
if response.ok:
return bs(response.content)
return NoneThis needs to happen at a couple of other places, and the dependencies need to be imported.
The best thing to do is to simply replace the entire code below with the original code in base.py
import logging
try:
from Queue import Queue # PY2
except ImportError:
from queue import Queue # PY3
from threading import Thread
try:
from urlparse import urljoin # PY2
except ImportError:
from urllib.parse import urljoin # PY3
import urllib
from six import iteritems
from six.moves import range
from .utils import bs, requests_get, get_all_sites, get_list_filters
ALL_SITES = get_all_sites() # All the Craiglist sites
RESULTS_PER_REQUEST = 100 # Craigslist returns 100 results per request
class CraigslistBase(object):
""" Base class for all Craiglist wrappers. """
url_templates = {
'base': 'http://%(site)s.craigslist.org',
'no_area': 'http://%(site)s.craigslist.org/search/%(category)s',
'area': 'http://%(site)s.craigslist.org/search/%(area)s/%(category)s'
}
default_site = 'sfbay'
default_category = None
base_filters = {
'query': {'url_key': 'query', 'value': None},
'search_titles': {'url_key': 'srchType', 'value': 'T'},
'has_image': {'url_key': 'hasPic', 'value': 1},
'posted_today': {'url_key': 'postedToday', 'value': 1},
'bundle_duplicates': {'url_key': 'bundleDuplicates', 'value': 1},
'search_distance': {'url_key': 'search_distance', 'value': None},
'zip_code': {'url_key': 'postal', 'value': None},
}
extra_filters = {}
__list_filters = {} # Cache for list filters requested by URL
# Set to True to subclass defines the customize_results() method
custom_result_fields = False
sort_by_options = {
'newest': 'date',
'price_asc': 'priceasc',
'price_desc': 'pricedsc',
}
def __init__(self, site=None, area=None, category=None, filters=None,
log_level=logging.WARNING):
# Logging
self.set_logger(log_level, init=True)
self.site = site or self.default_site
if self.site not in ALL_SITES:
msg = "'%s' is not a valid site" % self.site
self.logger.error(msg)
raise ValueError(msg)
if area:
if not self.is_valid_area(area):
msg = "'%s' is not a valid area for site '%s'" % (area, site)
self.logger.error(msg)
raise ValueError(msg)
self.area = area
self.category = category or self.default_category
url_template = self.url_templates['area' if area else 'no_area']
self.url = url_template % {'site': self.site, 'area': self.area,
'category': self.category}
self.filters = self.get_filters(filters)
def get_filters(self, filters):
"""Parses filters passed by the user into GET parameters."""
list_filters = self.get_list_filters(self.url)
# If a search has few results, results for "similar listings" will be
# included. The solution is a bit counter-intuitive, but to force this
# not to happen, we set searchNearby=True, but not pass any
# nearbyArea=X, thus showing no similar listings.
parsed_filters = {'searchNearby': 1}
for key, value in iteritems((filters or {})):
try:
filter_ = (self.base_filters.get(key) or
self.extra_filters.get(key) or
list_filters[key])
if filter_['value'] is None:
parsed_filters[filter_['url_key']] = value
elif isinstance(filter_['value'], list):
valid_options = filter_['value']
if not hasattr(value, '__iter__'):
value = [value] # Force to list
options = []
for opt in value:
try:
options.append(valid_options.index(opt) 1)
except ValueError:
self.logger.warning(
"'%s' is not a valid option for %s"
% (opt, key)
)
parsed_filters[filter_['url_key']] = options
elif value: # Don't add filter if ...=False
parsed_filters[filter_['url_key']] = filter_['value']
except KeyError:
self.logger.warning("'%s' is not a valid filter", key)
return parsed_filters
def set_logger(self, log_level, init=False):
if init:
self.logger = logging.getLogger('python-craiglist')
self.handler = logging.StreamHandler()
self.logger.addHandler(self.handler)
self.logger.setLevel(log_level)
self.handler.setLevel(log_level)
def is_valid_area(self, area):
base_url = self.url_templates['base']
response = requests_get(base_url % {'site': self.site},
logger=self.logger)
soup = bs(response.content)
sublinks = soup.find('ul', {'class': 'sublinks'})
return sublinks and sublinks.find('a', text=area) is not None
def get_results(self, limit=None, start=0, sort_by=None, geotagged=False,
include_details=False):
"""
Gets results from Craigslist based on the specified filters.
If geotagged=True, the results will include the (lat, lng) in the
'geotag' attrib (this will make the process a little bit longer).
"""
if sort_by:
try:
self.filters['sort'] = self.sort_by_options[sort_by]
except KeyError:
msg = ("'%s' is not a valid sort_by option, "
"use: 'newest', 'price_asc' or 'price_desc'" % sort_by)
self.logger.error(msg)
raise ValueError(msg)
total_so_far = start
results_yielded = 0
total = 0
while True:
self.filters['s'] = start
proxy_url='http://api.proxiesapi.com/?auth_key=dad407ce98b274996060fc03c714b6ae_sr98766_ooPq87&url=' urllib.quote_plus(self.url)
print(proxy_url)
response = requests_get(proxy_url, params=self.filters,
logger=self.logger)
self.logger.info('GET %s', response.url)
self.logger.info('Response code: %s', response.status_code)
response.raise_for_status() # Something failed?
soup = bs(response.content)
if not total:
totalcount = soup.find('span', {'class': 'totalcount'})
total = int(totalcount.text) if totalcount else 0
rows = soup.find('ul', {'class': 'rows'})
for row in rows.find_all('li', {'class': 'result-row'},
recursive=False):
if limit is not None and results_yielded >= limit:
break
self.logger.debug('Processing %s of %s results ...',
total_so_far 1, total)
yield self.process_row(row, geotagged, include_details)
results_yielded = 1
total_so_far = 1
if results_yielded == limit:
break
if (total_so_far - start) < RESULTS_PER_REQUEST:
break
start = total_so_far
def process_row(self, row, geotagged=False, include_details=False):
id = row.attrs['data-pid']
repost_of = row.attrs.get('data-repost-of')
link = row.find('a', {'class': 'hdrlnk'})
name = link.text
url = urljoin(self.url, link.attrs['href'])
time = row.find('time')
if time:
datetime = time.attrs['datetime']
else:
pl = row.find('span', {'class': 'pl'})
datetime = pl.text.split(':')[0].strip() if pl else None
price = row.find('span', {'class': 'result-price'})
where = row.find('span', {'class': 'result-hood'})
if where:
where = where.text.strip()[1:-1] # remove ()
tags_span = row.find('span', {'class': 'result-tags'})
tags = tags_span.text if tags_span else ''
result = {'id': id,
'repost_of': repost_of,
'name': name,
'url': url,
# NOTE: Keeping 'datetime' for backwards
# compatibility, use 'last_updated' instead.
'datetime': datetime,
'last_updated': datetime,
'price': price.text if price else None,
'where': where,
'has_image': 'pic' in tags,
'geotag': None}
if geotagged or include_details:
detail_soup = self.fetch_content(result['url'])
if geotagged:
self.geotag_result(result, detail_soup)
if include_details:
self.include_details(result, detail_soup)
if self.custom_result_fields:
self.customize_result(result)
return result
def customize_result(self, result):
""" Adds custom/delete/alter fields to result. """
# Override in subclass to add category-specific fields.
# FYI: `attrs` will only be presented if include_details was True.
pass
def geotag_result(self, result, soup):
""" Adds (lat, lng) to result. """
self.logger.debug('Geotagging result ...')
map = soup.find('div', {'id': 'map'})
if map:
result['geotag'] = (float(map.attrs['data-latitude']),
float(map.attrs['data-longitude']))
return result
def include_details(self, result, soup):
""" Adds description, images to result """
self.logger.debug('Adding details to result...')
body = soup.find('section', id='postingbody')
# We need to massage the data a little bit because it might include
# some inner elements that we want to ignore.
body_text = (getattr(e, 'text', e) for e in body
if not getattr(e, 'attrs', None))
result['body'] = ''.join(body_text).strip()
# Add created time (in case it's different from last updated).
postinginfos = soup.find('div', {'class': 'postinginfos'})
for p in postinginfos.find_all('p'):
if 'posted' in p.text:
time = p.find('time')
if time:
# This date is in ISO format. I'm removing the T literal
# and the timezone to make it the same format as
# 'last_updated'.
created = time.attrs['datetime'].replace('T', ' ')
result['created'] = created.rsplit(':', 1)[0]
# Add images' urls.
image_tags = soup.find_all('img')
# If there's more than one picture, the first one will be repeated.
image_tags = image_tags[1:] if len(image_tags) > 1 else image_tags
images = []
for img in image_tags:
if 'src' not in img: # Some posts contain empty ![]() tags.
continue
img_link = img['src'].replace('50x50c', '600x450')
images.append(img_link)
result['images'] = images
# Add list of attributes as unparsed strings. These values are then
# processed by `parse_attrs`, and are available to be post-processed
# by subclasses.
attrgroups = soup.find_all('p', {'class': 'attrgroup'})
attrs = []
for attrgroup in attrgroups:
for attr in attrgroup.find_all('span'):
attr_text = attr.text.strip()
if attr_text:
attrs.append(attr_text)
result['attrs'] = attrs
if attrs:
self.parse_attrs(result)
def parse_attrs(self, result):
"""Parses raw attributes into structured fields in the result dict."""
# Parse binary fields first by checking their presence.
attrs = set(attr.lower() for attr in result['attrs'])
for key, options in iteritems(self.extra_filters):
if options['value'] != 1:
continue # Filter is not binary
if options.get('attr', '') in attrs:
result[key] = True
# Values from list filters are sometimes shown as {filter}: {value}
# e.g. "transmission: automatic", although usually they are shown only
# with the {value}, e.g. "laundry in bldg". By stripping the content
# before the colon (if any) we reduce it to a single case.
attrs_after_colon = set(
attr.split(': ', 1)[-1] for attr in result['attrs'])
for key, options in iteritems(self.get_list_filters(self.url)):
for option in options['value']:
if option in attrs_after_colon:
result[key] = option
break
def fetch_content(self, url):
proxy_url='http://api.proxiesapi.com/?auth_key=dad407ce98b274996060fc03c714b6ae_sr98766_ooPq87&url=' urllib.quote_plus(url)
print(proxy_url)
response = requests_get(proxy_url, logger=self.logger)
self.logger.info('GET %s', response.url)
self.logger.info('Response code: %s', response.status_code)
if response.ok:
return bs(response.content)
return None
def geotag_results(self, results, workers=8):
"""
Adds (lat, lng) to each result. This process is done using N threads,
where N is the amount of workers defined (default: 8).
"""
results = list(results)
queue = Queue()
for result in results:
queue.put(result)
def geotagger():
while not queue.empty():
self.logger.debug('%s results left to geotag ...',
queue.qsize())
self.geotag_result(queue.get())
queue.task_done()
threads = []
for _ in range(workers):
thread = Thread(target=geotagger)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return results
@classmethod
def get_list_filters(cls, url):
if cls.__list_filters.get(url) is None:
cls.__list_filters[url] = get_list_filters(url)
return cls.__list_filters[url]
@classmethod
def show_filters(cls, category=None):
print('Base filters:')
for key, options in iteritems(cls.base_filters):
value_as_str = '...' if options['value'] is None else 'True/False'
print('* %s = %s' % (key, value_as_str))
print('Section specific filters:')
for key, options in iteritems(cls.extra_filters):
value_as_str = '...' if options['value'] is None else 'True/False'
print('* %s = %s' % (key, value_as_str))
url = cls.url_templates['no_area'] % {
'site': cls.default_site,
'category': category or cls.default_category,
}
list_filters = cls.get_list_filters(url)
for key, options in iteritems(list_filters):
value_as_str = ', '.join([repr(opt) for opt in options['value']])
print('* %s = %s' % (key, value_as_str))
tags.
continue
img_link = img['src'].replace('50x50c', '600x450')
images.append(img_link)
result['images'] = images
# Add list of attributes as unparsed strings. These values are then
# processed by `parse_attrs`, and are available to be post-processed
# by subclasses.
attrgroups = soup.find_all('p', {'class': 'attrgroup'})
attrs = []
for attrgroup in attrgroups:
for attr in attrgroup.find_all('span'):
attr_text = attr.text.strip()
if attr_text:
attrs.append(attr_text)
result['attrs'] = attrs
if attrs:
self.parse_attrs(result)
def parse_attrs(self, result):
"""Parses raw attributes into structured fields in the result dict."""
# Parse binary fields first by checking their presence.
attrs = set(attr.lower() for attr in result['attrs'])
for key, options in iteritems(self.extra_filters):
if options['value'] != 1:
continue # Filter is not binary
if options.get('attr', '') in attrs:
result[key] = True
# Values from list filters are sometimes shown as {filter}: {value}
# e.g. "transmission: automatic", although usually they are shown only
# with the {value}, e.g. "laundry in bldg". By stripping the content
# before the colon (if any) we reduce it to a single case.
attrs_after_colon = set(
attr.split(': ', 1)[-1] for attr in result['attrs'])
for key, options in iteritems(self.get_list_filters(self.url)):
for option in options['value']:
if option in attrs_after_colon:
result[key] = option
break
def fetch_content(self, url):
proxy_url='http://api.proxiesapi.com/?auth_key=dad407ce98b274996060fc03c714b6ae_sr98766_ooPq87&url=' urllib.quote_plus(url)
print(proxy_url)
response = requests_get(proxy_url, logger=self.logger)
self.logger.info('GET %s', response.url)
self.logger.info('Response code: %s', response.status_code)
if response.ok:
return bs(response.content)
return None
def geotag_results(self, results, workers=8):
"""
Adds (lat, lng) to each result. This process is done using N threads,
where N is the amount of workers defined (default: 8).
"""
results = list(results)
queue = Queue()
for result in results:
queue.put(result)
def geotagger():
while not queue.empty():
self.logger.debug('%s results left to geotag ...',
queue.qsize())
self.geotag_result(queue.get())
queue.task_done()
threads = []
for _ in range(workers):
thread = Thread(target=geotagger)
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
return results
@classmethod
def get_list_filters(cls, url):
if cls.__list_filters.get(url) is None:
cls.__list_filters[url] = get_list_filters(url)
return cls.__list_filters[url]
@classmethod
def show_filters(cls, category=None):
print('Base filters:')
for key, options in iteritems(cls.base_filters):
value_as_str = '...' if options['value'] is None else 'True/False'
print('* %s = %s' % (key, value_as_str))
print('Section specific filters:')
for key, options in iteritems(cls.extra_filters):
value_as_str = '...' if options['value'] is None else 'True/False'
print('* %s = %s' % (key, value_as_str))
url = cls.url_templates['no_area'] % {
'site': cls.default_site,
'category': category or cls.default_category,
}
list_filters = cls.get_list_filters(url)
for key, options in iteritems(list_filters):
value_as_str = ', '.join([repr(opt) for opt in options['value']])
print('* %s = %s' % (key, value_as_str))That should do the trick. After running this with the command.
python craigslist_scraper.pyYou should not face IP blocks again from Craigslist.
You can verify that the requests are passing through the Proxies API endpoint by going to your dashboard at https://app.proxiesapi.com/index.php and see the number of successful requests logged like this.