In this article, we will learn how to use Perl and the LWP::UserAgent and Mojo::DOM modules to download all the images from a Wikipedia page.
—-
Overview
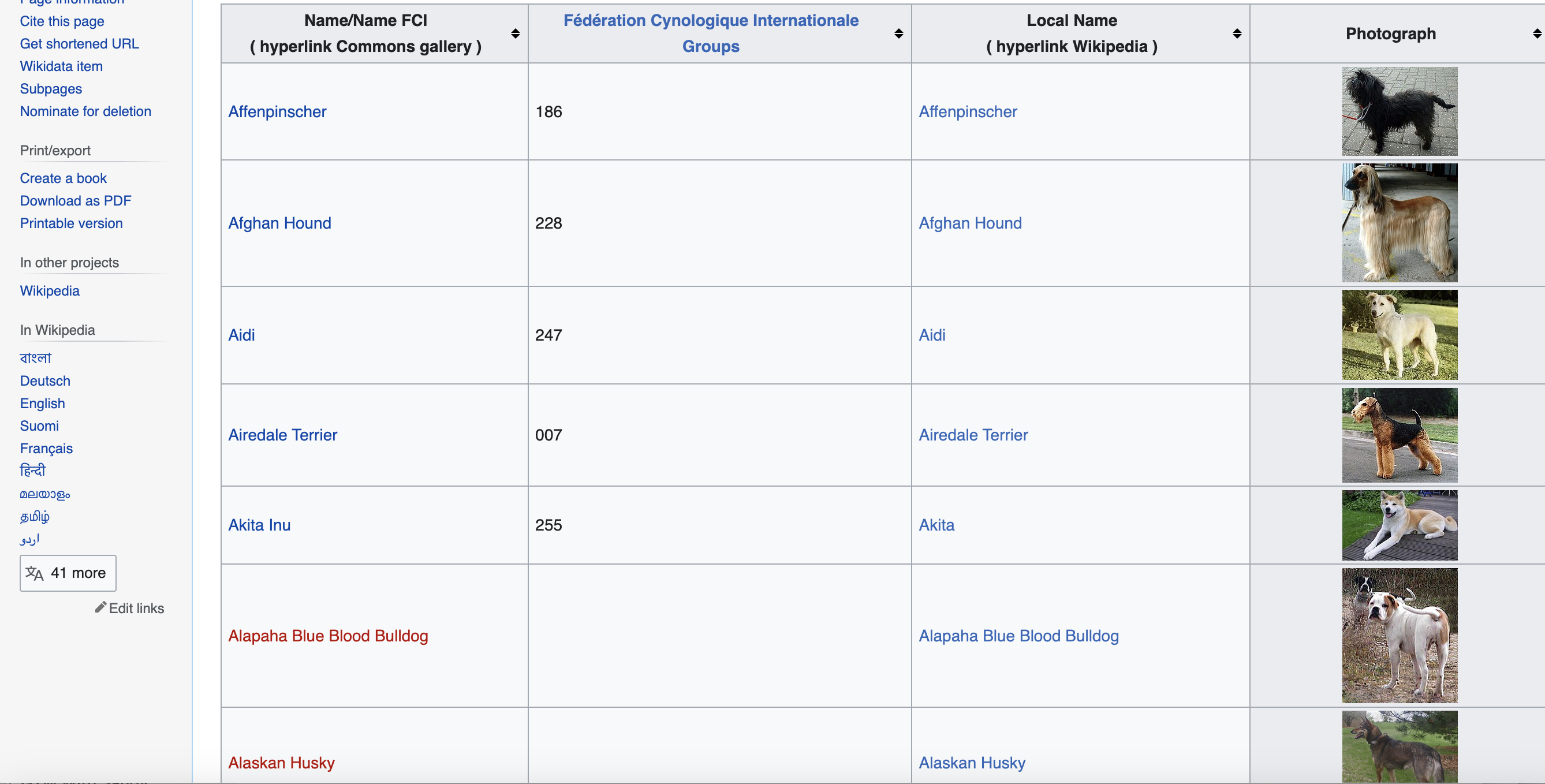
The goal is to extract the names, breed groups, local names, and image URLs for all dog breeds listed on this Wikipedia page. We will store the image URLs, download the images and save them to a local folder.
Here are the key steps we will cover:
- Import required modules
- Send HTTP request to fetch the Wikipedia page
- Parse the page HTML using Mojo::DOM
- Find the table with dog breed data using a CSS selector
- Iterate through the table rows
- Extract data from each column
- Download images and save locally
- Print/process extracted data
Let's go through each of these steps in detail.
Modules
We need these core modules:
use LWP::UserAgent;
use Mojo::DOM;
use File::Path qw(make_path);
Send HTTP Request
To download the web page:
my $url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>';
my $ua = LWP::UserAgent->new;
$ua->agent('PerlScraper');
my $res = $ua->get($url);
We create a user agent object and provide a custom user agent string.
Parse HTML
To parse the HTML:
my $dom = Mojo::DOM->new($res->content);
The
Find Breed Table
We use a CSS selector to find the table element:
my $table = $dom->find('table.wikitable.sortable')->[0];
This selects the We can iterate through the rows like this: We loop through each Inside the loop, we extract the column data: We use To download and save images: We reuse the user agent to download the image and save it to a file. We store the extracted data in arrays: The arrays can then be processed as needed. And that's it! Here is the full code: This provides a complete Perl solution using LWP::UserAgent and Mojo::DOM to scrape data and images from HTML tables. The same approach can apply to many websites. While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help. Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself. This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping. With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com" <!doctype html> Enter your email below to claim your free API key: tag with the required CSS classes.
Iterate Through Rows
foreach my $row ($table->find('tr')->slice(1)) {
# Extract data
}
skipping the first header row. Extract Column Data
my ($name, $group, $local_name, $img) =
map $_->text, $row->find('td, th')->each;
my $photograph = $img->find('img')->attr('src');
Download Images
if ($photograph) {
my $img_data = $ua->get($photograph)->content;
open my $fh, '>', "dog_images/$name.jpg";
print $fh $img_data;
close $fh;
}
Store Extracted Data
push @names, $name;
push @groups, $group;
push @local_names, $local_name;
push @photographs, $photograph;
#!/usr/bin/perl
use strict;
use warnings;
use LWP::UserAgent;
use Mojo::DOM;
use File::Path qw(make_path);
# Arrays to store data
my @names;
my @groups;
my @local_names;
my @photographs;
# User agent
my $ua = LWP::UserAgent->new;
$ua->agent('PerlScraper');
# Fetch HTML
my $url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>';
my $res = $ua->get($url);
# Parse HTML
my $dom = Mojo::DOM->new($res->content);
# Find table
my $table = $dom->find('table.wikitable.sortable')->[0];
# Iterate rows
foreach my $row ($table->find('tr')->slice(1)) {
# Extract data
my ($name, $group, $local_name, $img) =
map $_->text, $row->find('td, th')->each;
my $photograph = $img->find('img')->attr('src');
# Download image
if ($photograph) {
my $img_data = $ua->get($photograph)->content;
open my $fh, '>', "dog_images/$name.jpg";
print $fh $img_data;
close $fh;
}
# Store data
push @names, $name;
push @groups, $group;
push @local_names, $local_name;
push @photographs, $photograph;
}
Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Try ProxiesAPI for free
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...Don't leave just yet!