Are you curious about how to scrape data and images from a website using C#? Web scraping can be a powerful tool for collecting information from the web, and in this article, we'll walk you through the process step by step. We'll be using C# along with the HtmlAgilityPack library to extract data from a webpage. Our example scenario involves collecting data about different dog breeds from Wikipedia.
This is page we are talking about…
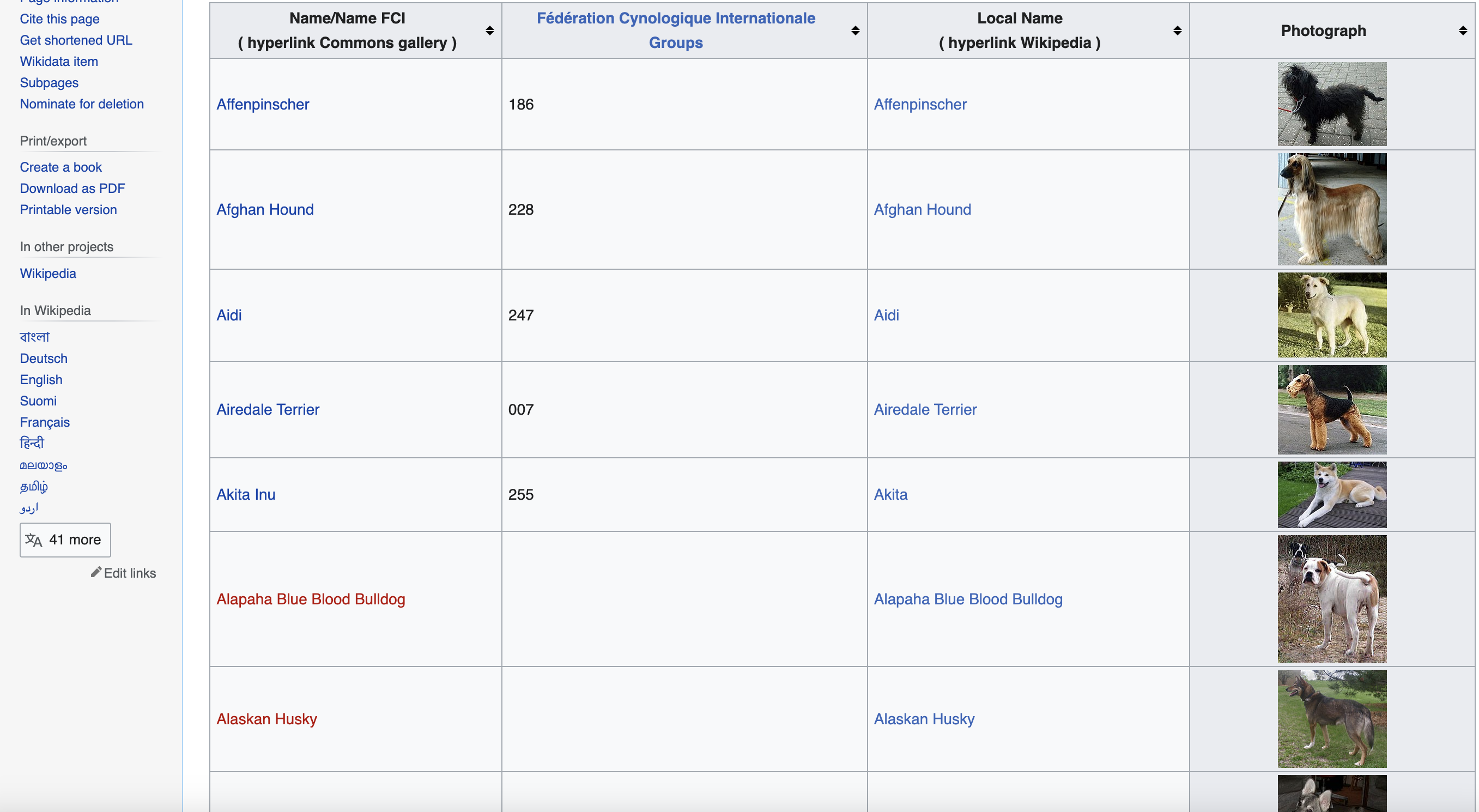
Step 1: Installation Instructions
Before we dive into the code, let's make sure you have the necessary tools and libraries installed. We'll be using C# for this project, so you should have a basic understanding of the language.
To get started, you'll need to install the HtmlAgilityPack library. You can do this using NuGet Package Manager in Visual Studio or by running the following command in your project's directory:
Install-Package HtmlAgilityPack
With the library installed, we're ready to move on to the code.
Step 2: Code Overview
Our goal is to extract data from a specific webpage and save images related to each entry. Here's a high-level overview of what our code does:
- Send an HTTP GET request to the webpage using a user-agent header to simulate a browser request.
- Check the HTTP status code to ensure the request was successful.
- Extract data from an HTML table on the webpage, including breed names, groups, local names, and image URLs.
- Download and save images to a local folder.
- Store the extracted data in lists for further processing.
- Output the data to the console or use it for other purposes.
Let's break down each step in detail.
Step 3: User-Agent Header
In web scraping, it's essential to send a user-agent header with your request to mimic a real browser. This helps avoid being blocked by the website. In our code, we define a user-agent header as follows:
string userAgent =
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
Step 4: Sending an HTTP GET Request
We use the
HtmlWeb web = new HtmlWeb();
web.UserAgent = userAgent;
HtmlDocument doc = web.Load(url);
Step 5: Checking HTTP Status Code
It's crucial to check the HTTP status code to ensure the request was successful. We do this using the following code snippet:
if (web.StatusCode == HttpStatusCode.OK)
{
// Web scraping code goes here...
}
else
{
Console.WriteLine("Failed to retrieve the web page. Status code: " + (int)web.StatusCode);
}
Step 6: Data Extraction
The heart of our code lies in the data extraction process.
Inspecting the page
You can see when you use the chrome inspect tool that the data is in a table element with the class wikitable and sortable
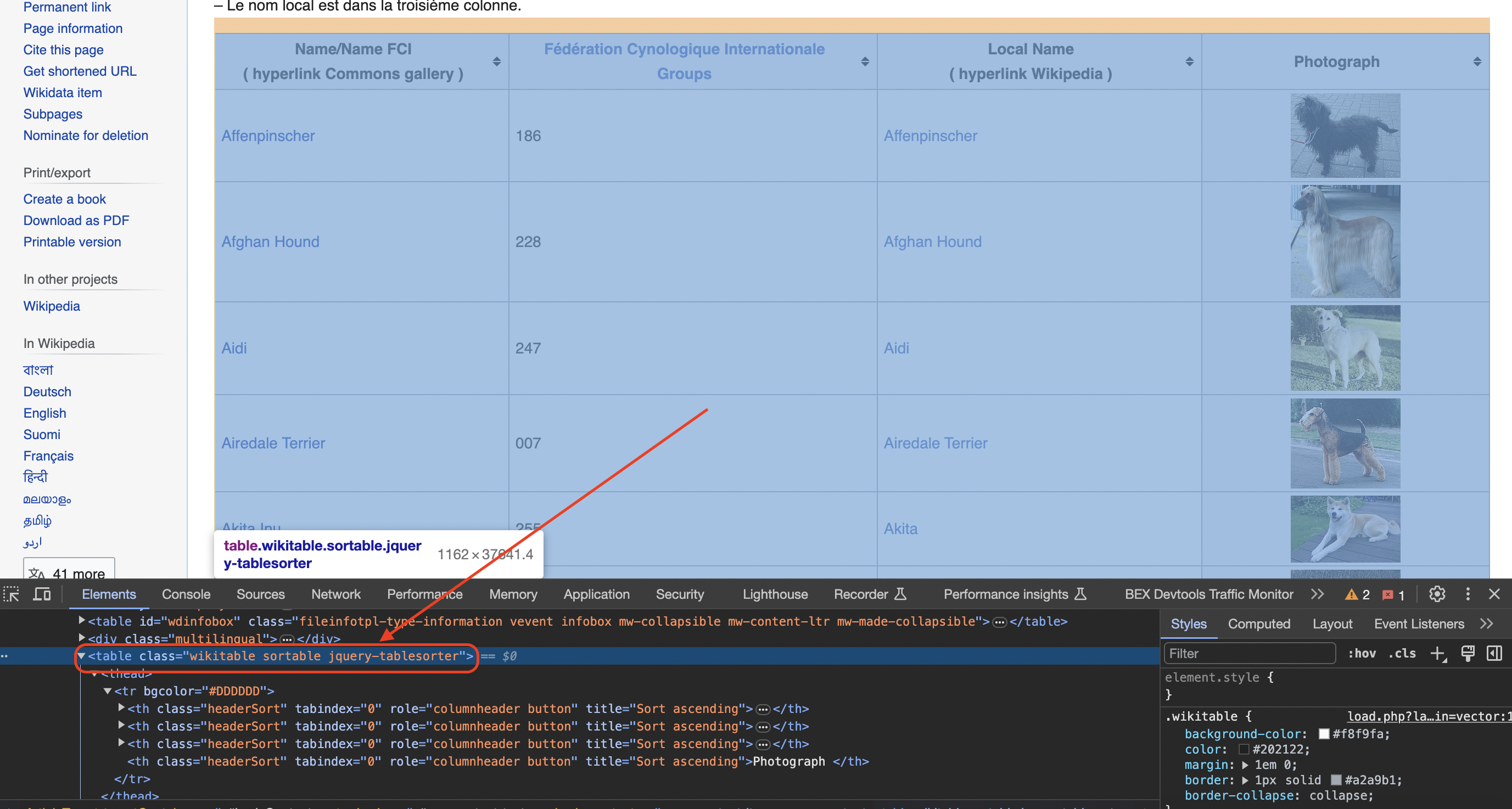
We extract data from an HTML table with the class
HtmlNode table = doc.DocumentNode.SelectSingleNode("//table[@class='wikitable sortable']");
Once we have selected the table, we proceed to extract data from its rows and columns. Each row represents information about a different dog breed, and we skip the header row using
Here's how we extract data from the columns:
foreach (HtmlNode row in table.SelectNodes("tr").Skip(1))
{
HtmlNodeCollection columns = row.SelectNodes("td|th");
if (columns.Count == 4)
{
// Extract data from each column
string name = columns[0].SelectSingleNode("a").InnerText.Trim();
string group = columns[1].InnerText.Trim();
// Check if the second column contains a span element
HtmlNode spanTag = columns[2].SelectSingleNode("span");
string localName = spanTag?.InnerText.Trim() ?? "";
// Check for the existence of an image tag within the fourth column
HtmlNode imgTag = columns[3].SelectSingleNode("img");
string photograph = imgTag?.GetAttributeValue("src", "") ?? "";
// Download the image and save it to the folder
if (!string.IsNullOrEmpty(photograph))
{
using (WebClient client = new WebClient())
{
byte[] imageData = client.DownloadData(photograph);
string imageFileName = Path.Combine("dog_images", $"{name}.jpg");
File.WriteAllBytes(imageFileName, imageData);
}
}
// Append data to respective lists
names.Add(name);
groups.Add(group);
localNames.Add(localName);
photographs.Add(photograph);
}
}
Step 7: Storing Data
We initialize lists (
Step 8: Image Download
Images related to each dog breed are downloaded using the
Step 9: Outputting Data
After extracting and processing the data, we can print it to the console or use it for various purposes. In the code provided, the data is printed to the console, but you can modify it to suit your needs.
Step 10: Next Steps
With the extracted data in hand, you can explore various possibilities. You might want to perform data analysis, create visualizations, or store the data in a database for future reference.
In more advanced implementations you will need to even rotate the User-Agent string so the website cant tell its the same browser!
If we get a little bit more advanced, you will realize that the server can simply block your IP ignoring all your other tricks. This is a bummer and this is where most web crawling projects fail.
Overcoming IP Blocks
Investing in a private rotating proxy service like Proxies API can most of the time make the difference between a successful and headache-free web scraping project which gets the job done consistently and one that never really works.
Plus with the 1000 free API calls running an offer, you have almost nothing to lose by using our rotating proxy and comparing notes. It only takes one line of integration to its hardly disruptive.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.