Web scraping is the process of extracting data from websites through automated scripts. It can be an extremely useful technique for gathering large volumes of public data available on the web. In this beginner tutorial, we'll walk through a full code sample for scraping business listings from Yelp.
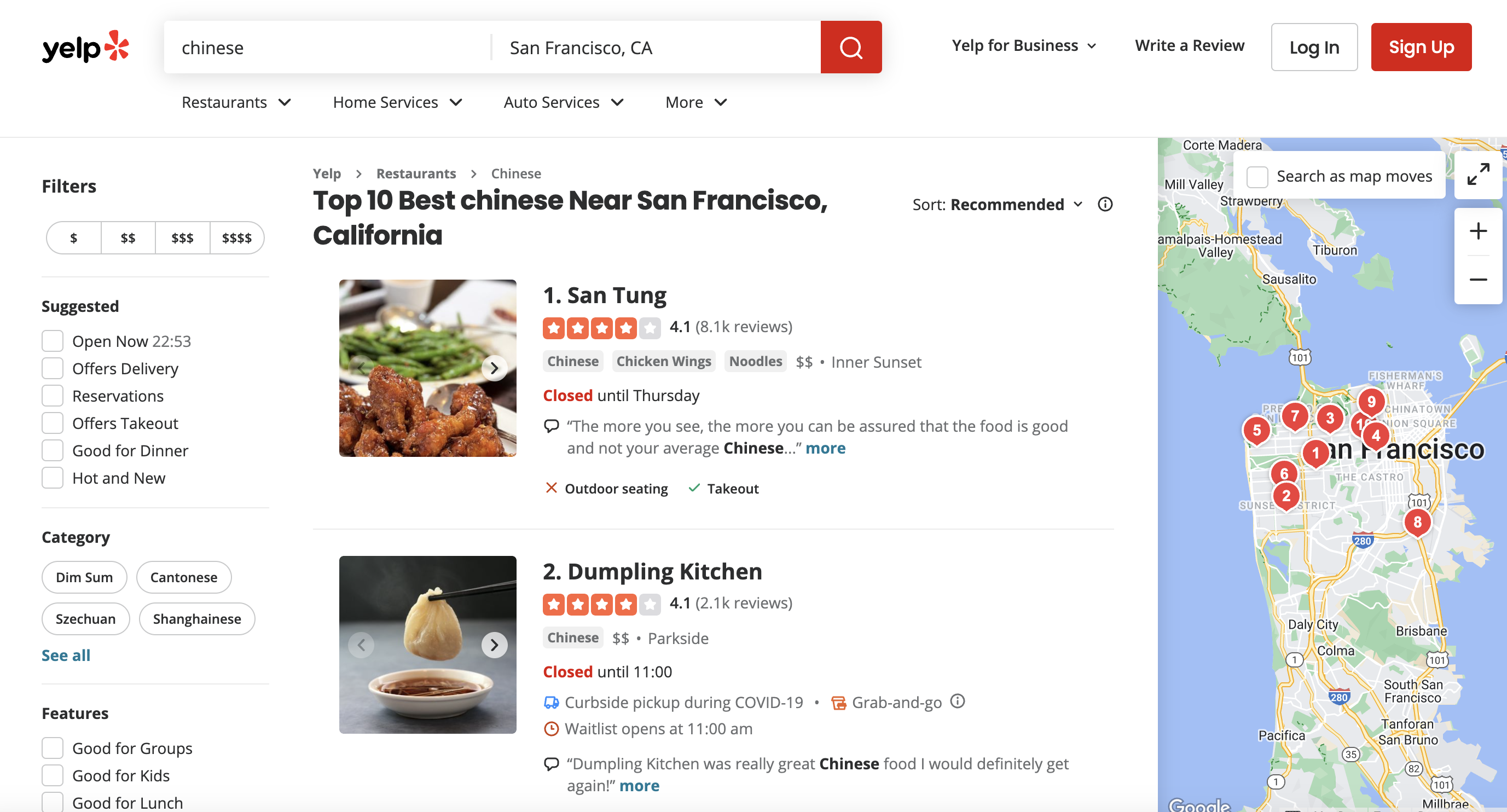
This is the page we are talking about
Getting Set Up
First, let's look at the modules we import at the top of the script:
use LWP::UserAgent;
use HTML::TreeBuilder;
use URI::Escape;
We also utilize the ProxiesAPI service to route our requests through residential proxies, bypassing Yelp's bot detection mechanisms.
Crafting the Request
Next, we construct the URL and headers to query the Yelp search page:
my $url = "<https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA>";
my $encoded_url = uri_escape($url, ":/?&=");
my $api_url = "<http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=$encoded_url>";
my $ua = LWP::UserAgent->new;
$ua->agent("Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
The key steps are:
- Define the Yelp URL with our search parameters
- Encode it properly for use in the API call
- Construct the full API URL using our auth key
- Instantiate a UserAgent object
- Set a legit browser User-Agent string
This will let us bypass bot protection when requesting the page contents.
Sending the Request
With our URL and headers configured, we can fire off the GET request:
my $response = $ua->get($api_url);
if ($response->is_success) {
# Parse page content...
} else {
print "Failed to retrieve data. Status Code: " . $response->code . "\\n";
}
We simply call
💡 Pro Tip: Using the ProxiesAPI service routes each request through different residential IP proxies. This makes it appear like real user traffic instead of bots!
Parsing the Page with HTML::TreeBuilder
Now we can parse the HTML content using the
my $tree = HTML::TreeBuilder->new_from_content($response->decoded_content);
This gives us a DOM tree representation that we can traverse to find elements by their CSS selectors.
💡 For beginners, CSS selectors allow you to pinpoint elements on a page through their id, class, tag name and more. It's the easiest way to locate the data you want from an HTML document.
Extracting Listing Data through Selectors
Here is where the real scraping magic happens!
Inspecting the page
When we inspect the page we can see that the div has classes called arrange-unit__09f24__rqHTg arrange-unit-fill__09f24__CUubG css-1qn0b6x

We use the parsed
my @listings = $tree->look_down(_tag => 'div', class => qr/arrange-unit__09f24__rqHTg|arrange-unit-fill__09f24__CUubG|css-1qn0b6x/);
foreach my $listing (@listings) {
my $name_elem = $listing->look_down(_tag => 'a', class => qr/css-19v1rkv/);
my $rating_elem = $listing->look_down(_tag => 'span', class => qr/css-gutk1c/);
my $price_range_elem = $listing->look_down(_tag => 'span', class => qr/priceRange__09f24__mmOuH/);
# And so on...
print "Name: " . $name . "\\n";
print "Rating: " . $rating . "\\n";
}
The key things to understand:
This takes practice but is the most important scraping concept!
Full code:
use LWP::UserAgent;
use HTML::TreeBuilder;
use URI::Escape;
# URL of the Yelp search page
my $url = "https://www.yelp.com/search?find_desc=chinese&find_loc=San+Francisco%2C+CA";
# URL-encode the URL
my $encoded_url = uri_escape($url, ":/?&=");
# API URL with the encoded Yelp URL
my $api_url = "http://api.proxiesapi.com/?premium=true&auth_key=YOUR_AUTH_KEY&url=$encoded_url";
# Define a user-agent header to simulate a browser request
my $ua = LWP::UserAgent->new;
$ua->agent("Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36");
$ua->default_header("Accept-Language" => "en-US,en;q=0.5");
$ua->default_header("Accept-Encoding" => "gzip, deflate, br");
$ua->default_header("Referer" => "https://www.google.com/"); # Simulate a referrer
# Send an HTTP GET request to the URL with the headers
my $response = $ua->get($api_url);
# Check if the request was successful (status code 200)
if ($response->is_success) {
# Save the HTML content to a file
open my $file, '>', "yelp_html.html" or die "Failed to open file: $!";
print $file $response->decoded_content;
close $file;
# Parse the HTML content of the page using HTML::TreeBuilder
my $tree = HTML::TreeBuilder->new_from_content($response->decoded_content);
# Find all the listings
my @listings = $tree->look_down(_tag => 'div', class => qr/arrange-unit__09f24__rqHTg|arrange-unit-fill__09f24__CUubG|css-1qn0b6x/);
print scalar(@listings) . "\n";
# Loop through each listing and extract information
foreach my $listing (@listings) {
# Assuming you've already extracted the information as shown in your code
# Check if business name exists
my $business_name_elem = $listing->look_down(_tag => 'a', class => qr/css-19v1rkv/);
my $business_name = $business_name_elem ? $business_name_elem->as_text : "N/A";
# If business name is not "N/A," then print the information
if ($business_name ne "N/A") {
# Check if rating exists
my $rating_elem = $listing->look_down(_tag => 'span', class => qr/css-gutk1c/);
my $rating = $rating_elem ? $rating_elem->as_text : "N/A";
# Check if price range exists
my $price_range_elem = $listing->look_down(_tag => 'span', class => qr/priceRange__09f24__mmOuH/);
my $price_range = $price_range_elem ? $price_range_elem->as_text : "N/A";
# Find all <span> elements inside the listing
my @span_elements = $listing->look_down(_tag => 'span', class => qr/css-chan6m/);
# Initialize num_reviews and location as "N/A"
my $num_reviews = "N/A";
my $location = "N/A";
# Check if there are at least two <span> elements
if (@span_elements >= 2) {
# The first <span> element is for Number of Reviews
$num_reviews = $span_elements[0]->as_text;
# The second <span> element is for Location
$location = $span_elements[1]->as_text;
} elsif (@span_elements == 1) {
# If there's only one <span> element, check if it's for Number of Reviews or Location
my $text = $span_elements[0]->as_text;
if ($text =~ /^\d+$/) {
$num_reviews = $text;
} else {
$location = $text;
}
}
# Print the extracted information
print "Business Name: $business_name\n";
print "Rating: $rating\n";
print "Number of Reviews: $num_reviews\n";
print "Price Range: $price_range\n";
print "Location: $location\n";
print "=" x 30 . "\n";
}
}
} else {
print "Failed to retrieve data. Status Code: " . $response->code . "\n";
}Final Thoughts
And we've now walked through the full process of scraping Yelp from search to data extraction!
Some final takeaways:
There's lots more to learn but this covers the basics of scraping Yelp listings. For next steps, try gathering data from additional pages or even aggregating results across other locations!
Browse by tags:
Browse by language:
The easiest way to do Web Scraping
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
Try ProxiesAPI for free
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...
Don't leave just yet!
Enter your email below to claim your free API key: