Welcome to web scraping with C#! This simple guide will teach you the basics of pulling data from websites using C#, a useful programming language. Once you finish this article, you'll know the tools, methods, and good habits for web scraping in C#. You'll be ready to take on real scraping tasks confidently.
Is C# a Good Language for Web Scraping?
C# is a fantastic tool for web scraping, thanks to its robustness, speed, and abundance of helpful resources. While Python often gets the limelight when it comes to web scraping, C# brings a lot to the table:
But bear in mind, C# might take a bit more effort to learn compared to Python, especially if you're just starting out. Also, you might find fewer web scraping resources and community support for C# than for Python. But don't let that deter you, C# is a worthy contender in the world of web scraping!
Best C# Web Scraping Libraries
When it comes to web scraping in C#, you have several powerful libraries at your disposal. Here's a comparison of the most popular ones:
Example usage of HtmlAgilityPack:
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load("<https://example.com>");
var titles = doc.DocumentNode.SelectNodes("//h1");
foreach (var title in titles)
{
Console.WriteLine(title.InnerText);
}
Prerequisites
Before diving into web scraping with C#, ensure you have the following prerequisites:
To install the HtmlAgilityPack library, run the following command in your terminal or package manager console:
dotnet add package HtmlAgilityPack
Let's Pick a Target Website
For this tutorial, we'll be scraping the Wikipedia page for dog breeds: https://commons.wikimedia.org/wiki/List_of_dog_breeds
We chose this page because:
This is the page we are talking about…
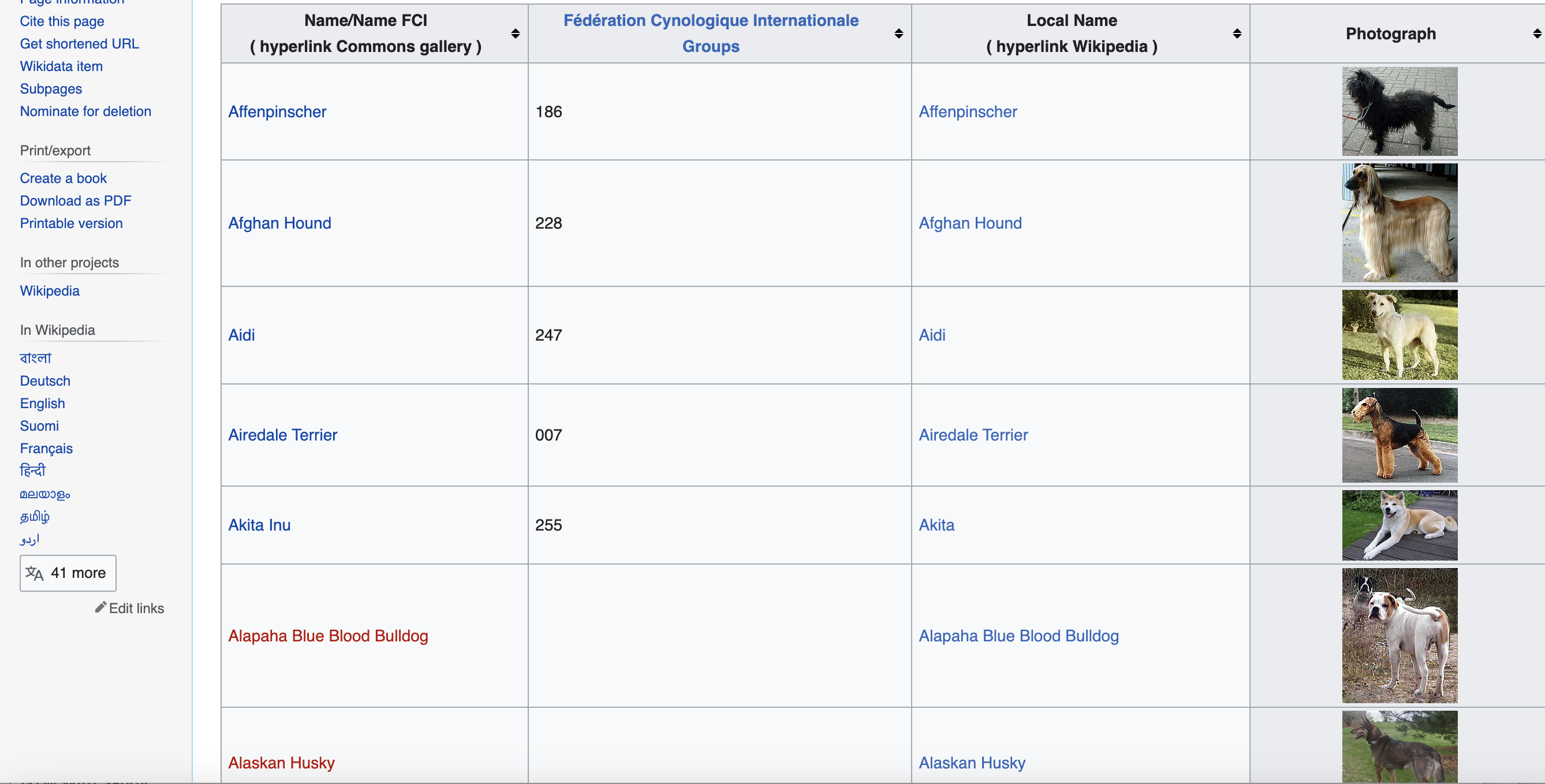
Writing the Scraping Code
Let's break down the scraping code step by step:
using System.Net;
using HtmlAgilityPack;
using System.IO;
using System.Linq;
These lines import the necessary namespaces for making HTTP requests, parsing HTML, and working with files and LINQ.
List<string> names = new List<string>();
List<string> groups = new List<string>();
List<string> localNames = new List<string>();
List<string> photographs = new List<string>();
We create lists to store the extracted data for each dog breed: name, group, local name, and photograph URL.
string url = "https://commons.wikimedia.org/wiki/List_of_dog_breeds";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
We define the target URL and create an HttpWebRequest object. Setting the UserAgent property mimics a browser request, which can help avoid being blocked by some websites.
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(response.GetResponseStream());
// ...
}
We send the request and load the HTML response into an HtmlDocument object for parsing.
Finding the table
Looking at the Raw HTML, we notice a table tag with CSS class wikitable sortable contains the main breed data.
var table = doc.DocumentNode.SelectSingleNode("//table[contains(@class, 'wikitable') and contains(@class, 'sortable')]");
Using XPath, we locate the table containing the dog breed data. The selector finds a table element with CSS classes 'wikitable' and 'sortable'.
foreach (var row in table.ChildNodes.Where(n => n.NodeType == HtmlNodeType.Element))
{
var cells = row.ChildNodes;
string name = cells[0].InnerText.Trim();
string group = cells[1].InnerText.Trim();
var localNameNode = cells[2].FirstChild;
string localName = localNameNode != null ? localNameNode.InnerText.Trim() : "";
var imgNode = cells[3].FirstChild;
string photograph = imgNode != null ? imgNode.GetAttributeValue("src", "") : "";
// ...
}
We iterate over each row in the table, extracting the data from each cell:
if (!string.IsNullOrEmpty(photograph))
{
using (WebClient client = new WebClient())
{
byte[] imageBytes = client.DownloadData(photograph);
string imagePath = $"dog_images/{name}.jpg";
File.WriteAllBytes(imagePath, imageBytes);
}
}
If a photograph URL is found, we download the image using a WebClient and save it locally with the dog breed's name as the filename.
names.Add(name);
groups.Add(group);
localNames.Add(localName);
photographs.Add(photograph);
Finally, we add the extracted data to their respective lists for further processing or storage.
Here is the code in full:
// Full code
using System.Net;
using HtmlAgilityPack;
using System.IO;
using System.Linq;
// Lists to store data
List<string> names = new List<string>();
List<string> groups = new List<string>();
List<string> localNames = new List<string>();
List<string> photographs = new List<string>();
string url = "https://commons.wikimedia.org/wiki/List_of_dog_breeds";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36";
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(response.GetResponseStream());
var table = doc.DocumentNode.SelectSingleNode("//table[contains(@class, 'wikitable') and contains(@class, 'sortable')]");
foreach (var row in table.ChildNodes.Where(n => n.NodeType == HtmlNodeType.Element))
{
var cells = row.ChildNodes;
string name = cells[0].InnerText.Trim();
string group = cells[1].InnerText.Trim();
var localNameNode = cells[2].FirstChild;
string localName = localNameNode != null ? localNameNode.InnerText.Trim() : "";
var imgNode = cells[3].FirstChild;
string photograph = imgNode != null ? imgNode.GetAttributeValue("src", "") : "";
if (!string.IsNullOrEmpty(photograph))
{
using (WebClient client = new WebClient())
{
byte[] imageBytes = client.DownloadData(photograph);
string imagePath = $"dog_images/{name}.jpg";
File.WriteAllBytes(imagePath, imageBytes);
}
}
names.Add(name);
groups.Add(group);
localNames.Add(localName);
photographs.Add(photograph);
}
}
The Power of XPath and CSS Selectors
XPath and CSS selectors are like super handy flashlights that help you find and pull out those special elements hiding in HTML documents. They're like your personal guides through the structure of the document, leading you right to the data you're looking for. So, let's dive in and get to know these awesome tools a bit better:
XPath (XML Path Language)
XPath is like a handy guide through the world of XML or HTML documents. It's a query language that helps you find nodes or compute values. It's like a map that lets you navigate the document tree and find elements based on their relationships, attributes, or content. So, let's dive in and explore some common XPath expressions:
Example usage of XPath with HtmlAgilityPack:
HtmlDocument doc = new HtmlDocument();
doc.LoadHtml(htmlContent);
// Select all 'a' elements
var links = doc.DocumentNode.SelectNodes("//a");
// Select 'div' elements with class 'article'
var articles = doc.DocumentNode.SelectNodes("//div[@class='article']");
// Select the first 'h1' element
var heading = doc.DocumentNode.SelectSingleNode("//h1");
// Select the text content of 'p' elements
var paragraphs = doc.DocumentNode.SelectNodes("//p/text()");
CSS Selectors
CSS selectors are like friendly guides that help us find and style elements in CSS (Cascading Style Sheets). They're super handy for web scraping too, letting us locate elements based on their tag name, class, ID, or other attributes. Here's a peek at some common CSS selector patterns:
Example usage of CSS selectors with AngleSharp:
var config = Configuration.Default.WithDefaultLoader();
var context = BrowsingContext.New(config);
var document = await context.OpenAsync(url);
// Select all 'a' elements
var links = document.QuerySelectorAll("a");
// Select 'div' elements with class 'article'
var articles = document.QuerySelectorAll("div.article");
// Select the element with ID 'main-content'
var mainContent = document.QuerySelector("#main-content");
// Select 'p' elements that are direct children of 'div'
var paragraphs = document.QuerySelectorAll("div > p");
If you're trying to find items in HTML, XPath and CSS selectors are your new best friends. XPath is great for complex searches and navigation, while CSS selectors are more straightforward and perfect for simpler tasks.
When it comes to web scraping, it's all about understanding the page setup. You can use developer tools to do that and test different XPath or CSS selectors to find the most effective way to extract data. Just be mindful of situations where selectors might change due to website updates. Using relative paths or backup selectors can help you navigate these changes.
Alternative Libraries and Tools for Web Scraping
In addition to the libraries mentioned earlier, there are other tools and approaches for web scraping in C#:
Choose the appropriate tool based on your scraping requirements:
Challenges of Web Scraping in the Real World: Tips & Best Practices
Web scraping at scale comes with its own set of challenges. Here are some common issues and tips to overcome them:
Dynamic Content
Using PuppeteerSharp with Headless Chrome
PuppeteerSharp is a .NET port of the Node.js library Puppeteer. It provides a high-level API for controlling headless Chrome or Chromium browsers. This makes it an excellent tool for web scraping dynamic websites that rely heavily on JavaScript to render content.
Here's a basic example of using PuppeteerSharp to load a web page and extract some data:
using PuppeteerSharp;
// ...
// Launch a new headless browser
using (var browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true }))
{
// Open a new page
using (var page = await browser.NewPageAsync())
{
// Navigate to the target URL
await page.GoToAsync("<https://example.com>");
// Wait for a specific element to load
await page.WaitForSelectorAsync("#my-element");
// Extract the element's text content
var element = await page.QuerySelectorAsync("#my-element");
var text = await page.EvaluateFunctionAsync<string>("element => element.textContent", element);
Console.WriteLine(text);
}
}
In this example, we start by launching a new headless browser. We then open a new page and navigate to the target URL. We wait for a specific element to load using
PuppeteerSharp can do much more than just extracting text content. It offers a range of functionalities that are useful for web scraping:
Using Selenium with Headless Chrome
Selenium is a powerful tool for controlling a web browser through the program. It is functional for all browsers, works on all major OS and its scripts are written in various languages i.e Python, Java, C#, etc.
Here's a basic example of using Selenium with headless Chrome to load a webpage and extract some data:
using OpenQA.Selenium;
using OpenQA.Selenium.Chrome;
// ...
// Setup options for headless Chrome
ChromeOptions options = new ChromeOptions();
options.AddArgument("--headless");
// Initialize a new Chrome driver with the options
IWebDriver driver = new ChromeDriver(options);
// Navigate to the target URL
driver.Navigate().GoToUrl("<https://example.com>");
// Find an element using its ID and get its text
IWebElement element = driver.FindElement(By.Id("my-element"));
string text = element.Text;
Console.WriteLine(text);
// Always remember to quit the driver when done
driver.Quit();
In this example, we start by setting up options for Chrome to run in headless mode. We then initialize a new Chrome driver with these options and navigate to the target URL. We find an element using its ID and extract its text content.
Selenium can do much more than just extracting text content. It offers a range of functionalities that are useful for web scraping:
Anti-Scraping Measures
Rotating user-agent strings example
User-Agent strings help web servers identify the client software making an HTTP request. Web scraping often involves making a large number of requests to the same server, which can lead to the server identifying and blocking the scraper based on its User-Agent string. To avoid this, you can rotate through a list of User-Agent strings, using a different one for each request.
Here's a simple example:
using System;
using System.Net;
// ...
List<string> userAgents = new List<string>
{
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X x.y; rv:42.0) Gecko/20100101 Firefox/42.0",
// Add more User-Agent strings as needed
};
string url = "<https://example.com>";
Random rand = new Random();
foreach (string userAgent in userAgents)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.UserAgent = userAgent;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
// Process the response...
}
// Wait a random interval between requests
System.Threading.Thread.Sleep(rand.Next(1000, 5000));
}
In this example, we start with a list of User-Agent strings. We then create a new HTTP request for each User-Agent, setting the UserAgent property of the request to the current User-Agent string. After processing the response, we wait a random interval between 1 and 5 seconds before making the next request.
This approach helps mimic human behavior by using different User-Agents for each request and introducing a delay between requests. However, it's still important to respect the website's robots.txt file and not overload the server with too many requests.
Rotating Headers to mimic various environments
In addition to rotating user-agents, you can also rotate headers to mimic various environments and avoid being detected as a scraper. By changing headers like
Here's a simple example of how to rotate headers in C#:
using System;
using System.Net;
// ...
List<WebHeaderCollection> headersList = new List<WebHeaderCollection>
{
new WebHeaderCollection
{
{ "User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3" },
{ "Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" },
{ "Accept-Language", "en-US,en;q=0.5" },
{ "Referer", "<https://www.google.com/>" }
},
new WebHeaderCollection
{
{ "User-Agent", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0" },
{ "Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8" },
{ "Accept-Language", "en-US,en;q=0.5" },
{ "Referer", "<https://www.bing.com/>" }
},
// Add more headers as needed
};
string url = "<https://example.com>";
Random rand = new Random();
foreach (WebHeaderCollection headers in headersList)
{
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Headers = headers;
using (HttpWebResponse response = (HttpWebResponse)request.GetResponse())
{
// Process the response...
}
// Wait a random interval between requests
System.Threading.Thread.Sleep(rand.Next(1000, 5000));
}
In this example, we start with a list of
This approach helps mimic different browsing environments by using different headers for each request and introducing a delay between requests. However, it's still important to respect the website's robots.txt file and not overload the server with too many requests.
Conclusion
While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help.
Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself.
This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping.
With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.