This in-depth article will teach you how to perform web scraping using PHP, even if you're a complete beginner. By the end, you'll have a solid understanding of the best PHP libraries for scraping, how to write efficient and effective scraping code, and how to overcome common challenges. Let's dive in!
Is PHP a Good Language for Web Scraping?
PHP is a versatile language well-suited for web scraping tasks. Its extensive library support, easy-to-understand syntax, and wide availability make it an excellent choice. However, it does have some challenges compared to Python:
Despite these challenges, PHP remains a solid option, especially if you're already familiar with the language.
Best PHP Web Scraping Libraries
Here is a detailed comparison of the most popular PHP libraries for web scraping:
- PHP Simple HTML DOM Parser
- Goutte
- DiDOM
Prerequisites
For this tutorial, we'll be using the PHP Simple HTML DOM Parser. To install it:
We'll also be using PHP's built-in DOM extension for some tasks. This should be enabled by default, but if not, uncomment the following line in your
extension=php_dom.dll
Let's pick a target website
We'll be scraping the Wikipedia page for dog breeds: https://commons.wikimedia.org/wiki/List_of_dog_breeds
This page provides a nice table structure with various dog breed details that we can extract, including names, breed groups, local names, and image URLs. Scraping Wikipedia pages is also generally acceptable as the information is in the public domain.
This is the page we are talking about:
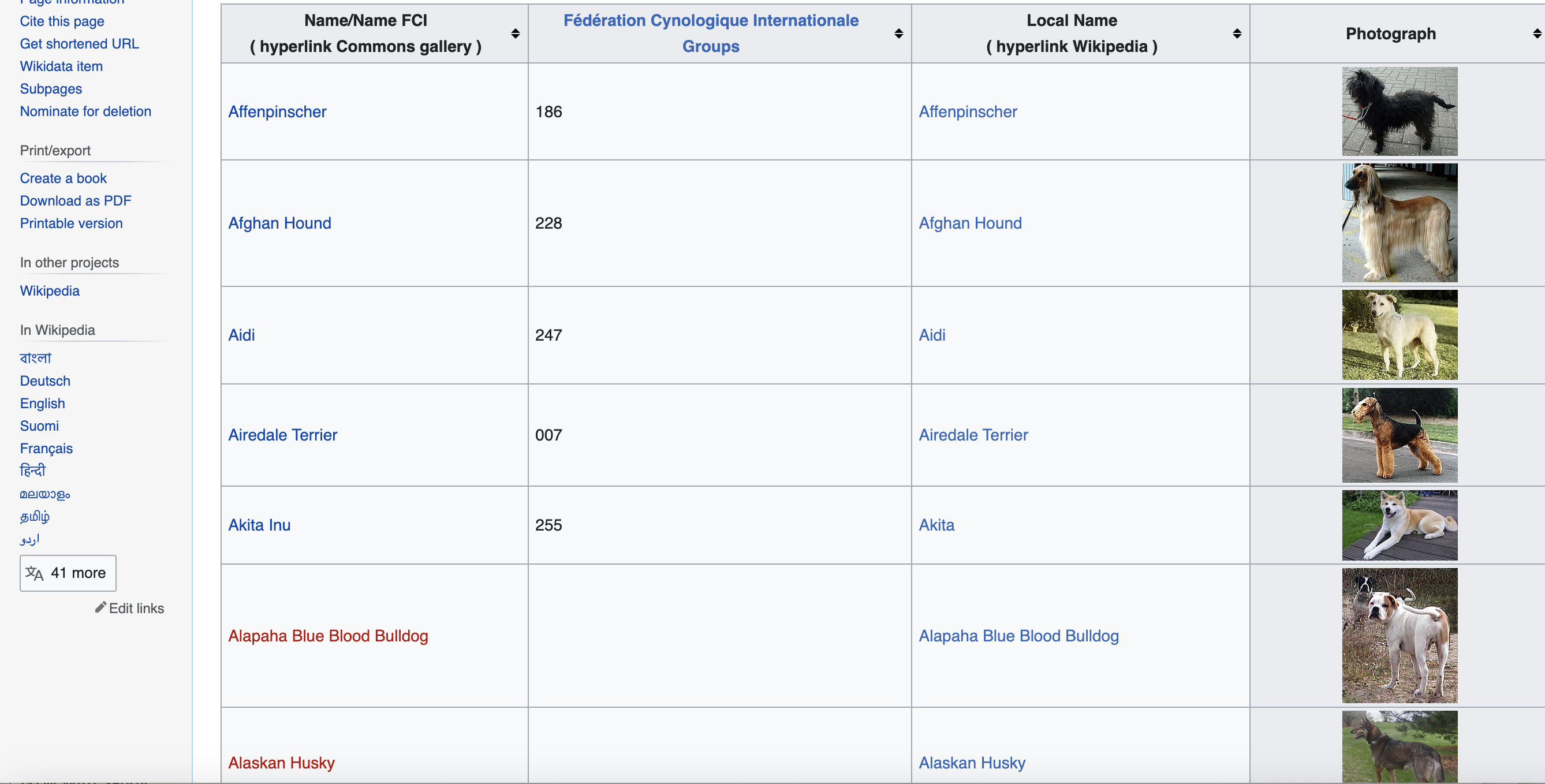
Some other good websites to practice scraping on:
Write the scraping code
Here is the full scraping code we'll walk through:
// Full code
// Include DOM extension
include 'php_dom.php';
// URL to scrape
$url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>';
// User agent header
$context = stream_context_create(array(
'http' => array(
'header' => "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
)
));
// Get page HTML
$response = file_get_contents($url, false, $context);
// Load HTML into DOMDocument
$doc = new DOMDocument();
$doc->loadHTML($response);
// Initialize DOM XPath
$xpath = new DOMXPath($doc);
// Find table by class name
$table = $xpath->query('//table[contains(@class, "wikitable") and contains(@class, "sortable")]');
// Initialize arrays
$names = [];
$groups = [];
$localNames = [];
$photographs = [];
// Loop through rows
foreach ($table->item(0)->childNodes as $row) {
if ($row->nodeType == 1) {
// Get cells
$cells = $row->childNodes;
// Extract column data
$name = trim($cells->item(0)->textContent);
$group = trim($cells->item(1)->textContent);
$localNameNode = $cells->item(2)->firstChild;
$localName = trim($localNameNode->textContent) if ($localNameNode);
$imgNode = $cells->item(3)->firstChild;
$photograph = $imgNode->getAttribute('src') if ($imgNode);
// Download and save image
if ($photograph) {
$image = file_get_contents($photograph, false, $context);
$imagePath = "dog_images/{$name}.jpg";
file_put_contents($imagePath, $image);
}
// Store data
$names[] = $name;
$groups[] = $group;
$localNames[] = $localName;
$photographs[] = $photograph;
}
}
The includes
First we include the necessary PHP libraries:
include 'php_dom.php';
The
Downloading the page
To download the HTML content of the page, we use PHP's built-in
$url = '<https://commons.wikimedia.org/wiki/List_of_dog_breeds>';
$response = file_get_contents($url, false, $context);
This sends a GET request to the specified URL and returns the response content as a string.
A couple things to note:
Setting user-agent
Some websites attempt to block scraper bots by inspecting the user-agent header on requests. To avoid this, we can specify our own user-agent string matching a typical browser:
$context = stream_context_create(array(
'http' => array(
'header' => "User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
)
));
We create a stream context with the user-agent header set to a Chrome browser string. This context is then passed to
For more advanced scraping, you may need to rotate user agents and other headers to avoid detection. There are PHP libraries to help automate this.
Inspecting the code
Before we start parsing the HTML, it's a good idea to inspect the page source to understand its structure. In Chrome, right-click the dog breeds table and select "Inspect".
We can see the table has classes of
Parsing the HTML
To parse the downloaded HTML, we load it into a DOMDocument object:
$doc = new DOMDocument();
$doc->loadHTML($response);
This converts the HTML string into a tree-like DOM structure that we can traverse and extract data from.
If your HTML contains special characters like accents, you may need to use the
Finding the table
Looking at the Raw HTML, we notice a table tag with CSS class wikitable sortable contains the main breed data.
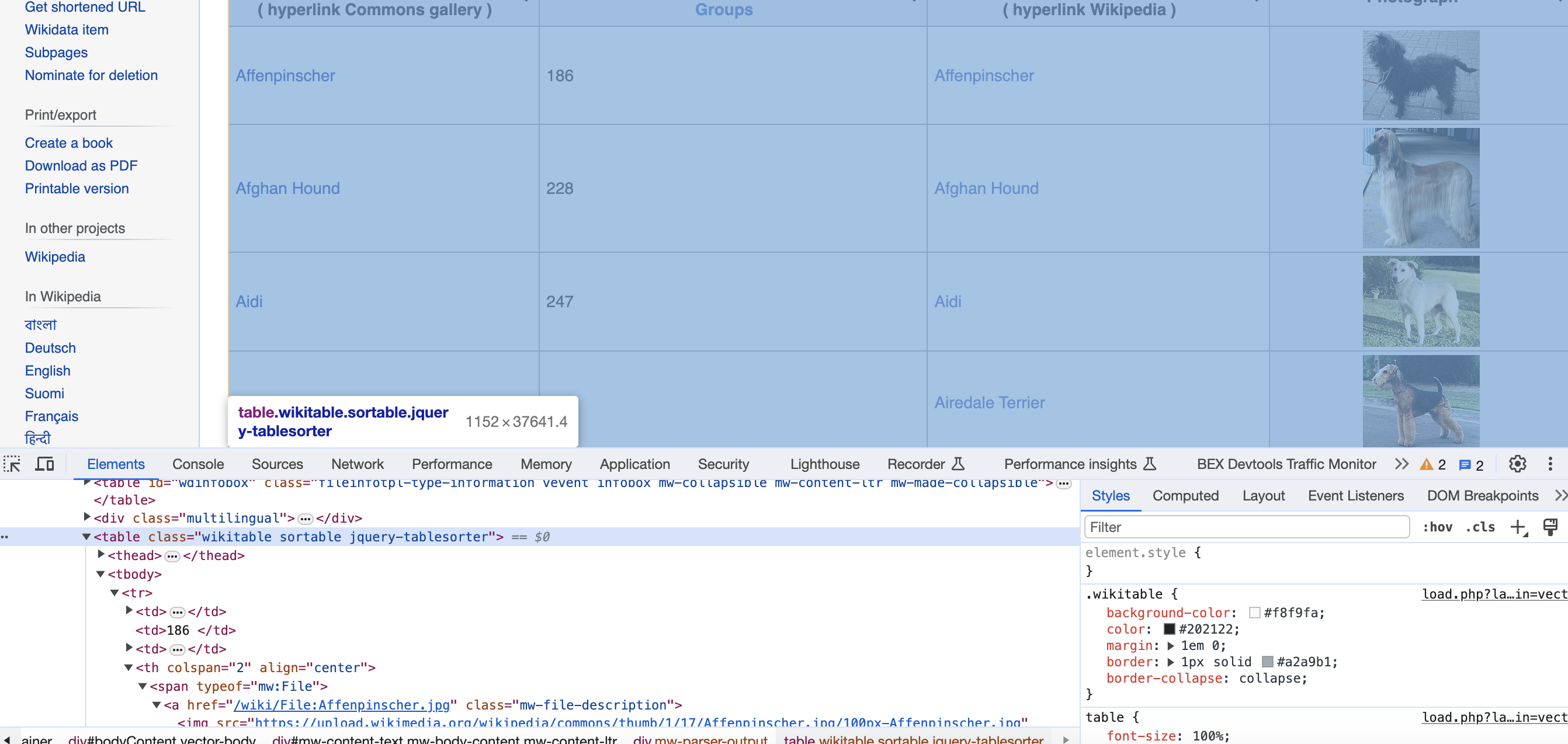
To locate the dog breeds table, we use XPath to query for a table with the classes
$xpath = new DOMXPath($doc);
$table = $xpath->query('//table[contains(@class, "wikitable") and contains(@class, "sortable")]');
XPath is a powerful query language that allows us to find elements based on their tag, attributes, and position in the DOM tree.
This query says: "Find a
If the query returns multiple results, we can access them using array notation on the resulting node list (e.g.
Extracting all the fields
Now that we have the table node, we can loop through its rows and extract the data for each dog breed:
foreach ($table->item(0)->childNodes as $row) {
if ($row->nodeType == 1) {
$cells = $row->childNodes;
$name = trim($cells->item(0)->textContent);
$group = trim($cells->item(1)->textContent);
$localNameNode = $cells->item(2)->firstChild;
$localName = trim($localNameNode->textContent) if ($localNameNode);
$imgNode = $cells->item(3)->firstChild;
$photograph = $imgNode->getAttribute('src') if ($imgNode);
$names[] = $name;
$groups[] = $group;
$localNames[] = $localName;
$photographs[] = $photograph;
}
}
Breaking this down step-by-step:
A few things to watch out for:
Downloading and saving the images
As a bonus, let's download the dog breed images and save them to our local filesystem. We'll use
if ($photograph) {
$image = file_get_contents($photograph, false, $context);
$imagePath = "dog_images/{$name}.jpg";
file_put_contents($imagePath, $image);
}
For each
Make sure to create a
Note that this simple approach doesn't handle duplicate breed names well, as the image files will overwrite each other. You'd need to add extra logic to generate unique filenames in that case.
The Power of XPath and CSS Selectors
When it comes to extracting data from HTML documents, XPath and CSS selectors are two of the most powerful and flexible tools at your disposal. They allow you to precisely target elements on a page based on their tag names, attributes, classes, IDs, and more.
XPath Selectors
XPath (XML Path Language) is a query language for selecting nodes in an XML or HTML document. It provides a concise syntax for navigating the document tree and filtering elements based on various criteria.
Here are some common XPath expressions and their meanings:
In PHP, you can use the built-in
$dom = new DOMDocument();
$dom->loadHTMLFile('<https://example.com>');
$xpath = new DOMXPath($dom);
// Select all <img> elements
$images = $xpath->query("//img");
foreach ($images as $img) {
echo $img->getAttribute('src') . "\\n";
}
// Select <a> elements that link to <https://example.com>
$links = $xpath->query("//a[contains(@href, '<https://example.com>')]");
foreach ($links as $link) {
echo $link->textContent . "\\n";
}
CSS Selectors
CSS selectors are patterns used to select HTML elements based on their tag, id, class, attribute, or relationship to other elements. They offer a more compact and readable syntax compared to XPath.
Some common CSS selectors include:
To use CSS selectors in PHP, you can install the
composer require symfony/css-selector
Then use it in combination with the built-in
use Symfony\\Component\\CssSelector\\CssSelectorConverter;
$dom = new DOMDocument();
$dom->loadHTMLFile('<https://example.com>');
$converter = new CssSelectorConverter();
// Select <img> elements with a "src" attribute
$xpath = new DOMXPath($dom);
$selector = 'img[src]';
$expression = $converter->toXPath($selector);
$images = $xpath->query($expression);
foreach ($images as $img) {
echo $img->getAttribute('src') . "\\n";
}
// Select <p> elements that are descendants of <div> elements
$selector = 'div p';
$expression = $converter->toXPath($selector);
$paragraphs = $xpath->query($expression);
foreach ($paragraphs as $p) {
echo $p->textContent . "\\n";
}
The
Alternative libraries and tools for web scraping
In addition to the PHP libraries covered earlier, there are other tools and approaches you can use for web scraping:
Here are a few specific PHP tools to consider:
Laravel Dusk
Laravel-specific headless browser testing tool built on Chromedriver
PHP cURL
PHP cURL is a low-level library for making HTTP requests. Here's an example of web scraping using PHP cURL:
<?php
// URL of the page to scrape
$url = '<https://example.com>';
// Initialize cURL
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3');
// Execute the cURL request
$response = curl_exec($ch);
// Check if the request was successful
if ($response === false) {
echo 'cURL Error: ' . curl_error($ch);
} else {
// Load the HTML into a DOMDocument
$dom = new DOMDocument();
@$dom->loadHTML($response);
// Create a DOMXPath object for traversing the document
$xpath = new DOMXPath($dom);
// Example: Extracting all the titles on the page
$titles = $xpath->query('//h2');
// Loop through the titles and display them
foreach ($titles as $title) {
echo $title->nodeValue . "\\n";
}
// Example: Extracting all the links on the page
$links = $xpath->query('//a');
// Loop through the links and display their URLs
foreach ($links as $link) {
echo $link->getAttribute('href') . "\\n";
}
}
// Close the cURL handle
curl_close($ch);
In this example:
- We set the URL of the page we want to scrape in the
$url variable. - We initialize a new cURL session using
curl_init() . - We set the cURL options:
- We execute the cURL request using
curl_exec() and store the response in the$response variable. - We check if the request was successful. If not, we display the cURL error using
curl_error() . - If the request was successful, we load the HTML response into a
DOMDocument object. - We create a
DOMXPath object to traverse the document using XPath expressions. - We use XPath queries to extract specific elements from the page. In this example, we extract all the
h2 elements (titles) anda elements (links). - We loop through the extracted elements and display their values or attributes.
- Finally, we close the cURL handle using
curl_close() to free up resources.
Here's an example of using multi cURL to perform simultaneous downloads:
<?php
// Array of URLs to download
$urls = [
'https://example.com/file1.pdf',
'https://example.com/file2.pdf',
'https://example.com/file3.pdf',
'https://example.com/file4.pd 'https://example.com/file5.pdf',
];
// Create a new cURL multi handle
$mh = curl_multi_init();
// Create an array to hold the individual cURL handles
$handles = [];
// Initialize individual cURL handles for each URL
foreach ($urls as $key => $url) {
$handles[$key] = curl_init($url);
curl_setopt($handles[$key], CURLOPT_RETURNTRANSFER, true);
curl_setopt($handles[$key], CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3');
curl_multi_add_handle($mh, $handles[$key]);
}
// Execute the cURL requests simultaneously
$running = null;
do {
curl_multi_exec($mh, $running);
} while ($running > 0);
// Process the downloaded files
foreach ($handles as $key => $handle) {
// Get the downloaded content
$content = curl_multi_getcontent($handle);
// Generate a filename for the downloaded file
$filename = 'file_' . ($key + 1) . '.pdf';
// Save the content to a file
file_put_contents($filename, $content);
// Remove the individual cURL handle
curl_multi_remove_handle($mh, $handle);
curl_close($handle);
}
// Close the cURL multi handle
curl_multi_close($mh);
echo "All files downloaded successfully!\n";
In this example:
- We define an array
$urls containing the URLs of the files we want to download simultaneously. - We create a new cURL multi handle using
curl_multi_init() . This handle will manage the simultaneous cURL requests. - We create an empty array
$handles to store the individual cURL handles for each URL. - We iterate over the
$urls array and perform the following steps for each URL: - We execute the cURL requests simultaneously using
curl_multi_exec() in a loop until all requests are completed. - After all requests are finished, we iterate over the
$handles array to process the downloaded files: - Finally, we close the cURL multi handle using
curl_multi_close() to free up resources.
here is an example of how you can rate limit in PHP cURL:
<?php
// Array of URLs to download
$urls = [
'https://example.com/file1.pdf',
'https://example.com/file2.pdf',
'https://example.com/file3.pdf',
'https://example.com/file4.pdf',
'https://example.com/file5.pdf',
];
// Maximum number of simultaneous downloads
$maxSimultaneousDownloads = 2;
// Delay between each batch of downloads (in seconds)
$delayBetweenBatches = 1;
// Create a new cURL multi handle
$mh = curl_multi_init();
// Initialize variables for rate limiting
$currentBatch = 0;
$totalBatches = ceil(count($urls) / $maxSimultaneousDownloads);
// Process the URLs in batches
while ($currentBatch < $totalBatches) {
// Calculate the range of URLs for the current batch
$startIndex = $currentBatch * $maxSimultaneousDownloads;
$endIndex = min(($currentBatch + 1) * $maxSimultaneousDownloads, count($urls));
// Create an array to hold the individual cURL handles for the current batch
$handles = [];
// Initialize individual cURL handles for each URL in the current batch
for ($i = $startIndex; $i < $endIndex; $i++) {
$url = $urls[$i];
$handles[$i] = curl_init($url);
curl_setopt($handles[$i], CURLOPT_RETURNTRANSFER, true);
curl_setopt($handles[$i], CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3');
curl_multi_add_handle($mh, $handles[$i]);
}
// Execute the cURL requests simultaneously for the current batch
$running = null;
do {
curl_multi_exec($mh, $running);
} while ($running > 0);
// Process the downloaded files for the current batch
for ($i = $startIndex; $i < $endIndex; $i++) {
// Get the downloaded content
$content = curl_multi_getcontent($handles[$i]);
// Generate a filename for the downloaded file
$filename = 'file_' . ($i + 1) . '.pdf';
// Save the content to a file
file_put_contents($filename, $content);
// Remove the individual cURL handle
curl_multi_remove_handle($mh, $handles[$i]);
curl_close($handles[$i]);
}
// Increment the current batch
$currentBatch++;
// Delay before starting the next batch
if ($currentBatch < $totalBatches) {
sleep($delayBetweenBatches);
}
}
// Close the cURL multi handle
curl_multi_close($mh);
echo "All files downloaded successfully!\n";Guzzle
Guzzle is a popular PHP HTTP client library that makes it easy to send requests to web pages and retrieve their content. It provides a simple and expressive interface for making GET, POST, and other types of requests, handling cookies and authentication, and parsing response data.
To install Guzzle, run the following command in your project directory:
composer require guzzlehttp/guzzle
Here's a basic example of using Guzzle to scrape a webpage:
use GuzzleHttp\\Client;
use Symfony\\Component\\DomCrawler\\Crawler;
$client = new Client();
$response = $client->get('<https://example.com>');
$html = $response->getBody()->getContents();
$crawler = new Crawler($html);
$title = $crawler->filter('h1')->first()->text();
echo $title . "\\n";
$links = $crawler->filter('a')->extract(['_text', 'href']);
print_r($links);
In this example:
- We create a new Guzzle
Client instance. - We send a GET request to the target URL using
$client->get() and store the response. - We extract the HTML content of the response using
$response->getBody()->getContents() . - We create a new
Crawler instance from the HTML, which provides methods for traversing and extracting data from the document using CSS selectors. - We select the first
h1 element and print its text content. - We select all
a elements and extract their text andhref attribute values into an array.
Guzzle also supports more advanced features like asynchronous requests, middleware, and request options. For example, you can set custom headers, timeout values, and proxy settings on a per-request basis:
$response = $client->get('<https://example.com>', [
'headers' => [
'User-Agent' => 'My Scraper/1.0',
],
'timeout' => 10,
'proxy' => '<http://user:pass@proxy.example.com:8080>',
]);
Here's an example of making asynchronous requests with Guzzle:
use GuzzleHttp\\Client;
use GuzzleHttp\\Promise;
use Symfony\\Component\\DomCrawler\\Crawler;
$client = new Client();
$urls = [
'<https://example.com/page1>',
'<https://example.com/page2>',
'<https://example.com/page3>',
];
$promises = [];
foreach ($urls as $url) {
$promises[] = $client->getAsync($url);
}
$results = Promise\\settle($promises)->wait();
foreach ($results as $result) {
if ($result['state'] === 'fulfilled') {
$response = $result['value'];
$html = $response->getBody()->getContents();
$crawler = new Crawler($html);
$title = $crawler->filter('h1')->first()->text();
echo $title . "\\n";
} else {
$reason = $result['reason'];
echo "Request failed: " . $reason->getMessage() . "\\n";
}
}
Some websites may have rate limits or other protections against high-volume scraping. Make sure to review the site's terms of service and robots.txt file before scraping.
here is an example of how you can rate limit in guzzle using the
use GuzzleHttp\Client;
use GuzzleHttp\HandlerStack;
use GuzzleHttp\Psr7\Request;
use Spatie\GuzzleRateLimiterMiddleware\RateLimiterMiddleware;
use Spatie\GuzzleRateLimiterMiddleware\Store;
// Create a Guzzle client with rate limiting middleware
$stack = HandlerStack::create();
$store = new Store();
$middleware = new RateLimiterMiddleware($store, 10, 60); // 10 requests per 60 seconds
$stack->push($middleware);
$client = new Client(['handler' => $stack]);
// Make requests with rate limiting
for ($i = 1; $i <= 20; $i++) {
$request = new Request('GET', 'https://api.example.com/data');
try {
$response = $client->send($request);
echo "Request $i succeeded: " . $response->getStatusCode() . "\n";
} catch (\Exception $e) {
echo "Request $i failed: " . $e->getMessage() . "\n";
}
}When you run this script, you should see output like:
Request 1 succeeded: 200
Request 2 succeeded: 200
...
Request 10 succeeded: 200
Request 11 failed: Too Many Requests
...
Request 20 failed: Too Many RequestsChallenges of Web Scraping in the Real World
While scraping can be a powerful tool, there are some challenges to watch out for when scraping real websites at scale:
Some best practices for handling these challenges:
Simulating a Real User with User Agents and Headers
When web scraping, it's important to simulate the behavior of a real user to avoid detection and potential blocking by websites. One key aspect of this is setting appropriate user agent strings and headers in your scraping requests.
User Agent Rotation:
A user agent is a string that identifies the browser and operating system being used to make the request. Websites often use user agent information to tailor their content and detect potential bots. To simulate a real user, you can rotate user agent strings in your scraping requests. Here's an example of how to implement user agent rotation in PHP using cURL:
<?php
// Array of user agent strings
$userAgents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36',
];
// Function to get a random user agent string
function getRandomUserAgent($userAgents) {
$index = array_rand($userAgents);
return $userAgents[$index];
}
// URL to scrape
$url = '<https://example.com>';
// Initialize cURL
$ch = curl_init();
// Set cURL options
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_USERAGENT, getRandomUserAgent($userAgents));
// Execute the cURL request
$response = curl_exec($ch);
// Process the response
// ...
// Close the cURL handle
curl_close($ch);
In this example, we define an array
Headers Rotation:
In addition to user agents, you can also rotate other headers to further simulate real user behavior. Some common headers to consider include:
You can create arrays of different header values and randomly select them for each request, similar to user agent rotation. Here's an example:
<?php
// Arrays of header values
$acceptHeaders = [
'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8',
];
$acceptLanguageHeaders = [
'en-US,en;q=0.5',
'en-GB,en;q=0.8,en-US;q=0.6,en;q=0.4',
];
$acceptEncodingHeaders = [
'gzip, deflate, br',
'gzip, deflate',
];
$refererHeaders = [
'<https://www.google.com/>',
'<https://www.bing.com/>',
];
// Function to get a random header value from an array
function getRandomHeader($headers) {
$index = array_rand($headers);
return $headers[$index];
}
// Set cURL options with random headers
curl_setopt($ch, CURLOPT_HTTPHEADER, [
'Accept: ' . getRandomHeader($acceptHeaders),
'Accept-Language: ' . getRandomHeader($acceptLanguageHeaders),
'Accept-Encoding: ' . getRandomHeader($acceptEncodingHeaders),
'Referer: ' . getRandomHeader($refererHeaders),
]);
In this example, we define arrays for different header values (
By rotating user agents and headers, you can make your scraping requests appear more like genuine user traffic, reducing the chances of being detected and blocked by websites. However, it's important to note that some websites may still employ advanced techniques to detect and block scraping activities, so it's crucial to be respectful and adhere to the website's terms of service and robots.txt file.
Headless Browsers for Web Scraping
Headless browsers are web browsers that run without a graphical user interface (GUI). They can be controlled programmatically and are particularly useful for web scraping because they can:
Some popular headless browsers used for web scraping include:
In PHP, you can use Puppeteer or Selenium through their respective PHP bindings. Here's an example of using Puppeteer with the
use Nesk\\Puphpeteer\\Puppeteer;
$puppeteer = new Puppeteer;
$browser = $puppeteer->launch();
$page = $browser->newPage();
$page->goto('<https://example.com>');
$page->waitForSelector('h1');
$html = $page->content();
$browser->close();
// Parse the rendered HTML using your preferred DOM library
$dom = new DOMDocument();
$dom->loadHTML($html);
// Extract data using DOM methods as usual
$title = $dom->getElementsByTagName('h1')->item(0)->textContent;
echo $title;
And here's the same example using Selenium with the
use Facebook\\WebDriver\\Chrome\\ChromeOptions;
use Facebook\\WebDriver\\Remote\\DesiredCapabilities;
use Facebook\\WebDriver\\Remote\\RemoteWebDriver;
use Facebook\\WebDriver\\WebDriverBy;
$host = '<http://localhost:4444/wd/hub>'; // Selenium server URL
$capabilities = DesiredCapabilities::chrome();
$options = new ChromeOptions();
$options->addArguments(['--headless']);
$capabilities->setCapability(ChromeOptions::CAPABILITY, $options);
$driver = RemoteWebDriver::create($host, $capabilities);
$driver->get('<https://example.com>');
$driver->findElement(WebDriverBy::cssSelector('h1'));
$html = $driver->getPageSource();
$driver->quit();
// Parse the rendered HTML using your preferred DOM library
$dom = new DOMDocument();
$dom->loadHTML($html);
// Extract data using DOM methods as usual
$title = $dom->getElementsByTagName('h1')->item(0)->textContent;
echo $title;
While these examples are great for learning, scraping production-level sites can pose challenges like CAPTCHAs, IP blocks, and bot detection. Rotating proxies and automated CAPTCHA solving can help.
Proxies API offers a simple API for rendering pages with built-in proxy rotation, CAPTCHA solving, and evasion of IP blocks. You can fetch rendered pages in any language without configuring browsers or proxies yourself.
This allows scraping at scale without headaches of IP blocks. Proxies API has a free tier to get started. Check out the API and sign up for an API key to supercharge your web scraping.
With the power of Proxies API combined with Python libraries like Beautiful Soup, you can scrape data at scale without getting blocked.
Browse by language:
The easiest way to do Web Scraping
Get HTML from any page with a simple API call. We handle proxy rotation, browser identities, automatic retries, CAPTCHAs, JavaScript rendering, etc automatically for you
Try ProxiesAPI for free
curl "http://api.proxiesapi.com/?key=API_KEY&url=https://example.com"
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
...
Don't leave just yet!
Enter your email below to claim your free API key: