
Synchronous Web Scraping v/s Asynchronous Web Scraping with Python
One of the features of our Rotating Proxy Service Proxies API is the enormous concurrency it offers straight from the free plan itself. This is because we wanted the ability to scale our customer's web scrapers to be there from moment one. People do ask us what is the best way to make concurrent requests on their side. So we thought we would put together a getting started code that helps you understand and get started with async requests in Python.
To properly understand them, however, let's look at the differences between a normal, synchronous approach as compared to an asynchronous one.
To fetch URLs sequentially, we will use the requests module in python.
import requestsLets store all the URLs in an array-like so...
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']The simple function uses the requests.get function to get the URLs one by one and calculate the time taken for each and also for the total.
from timeit import default_timer
import requests
def get_urls(urls):
start_time = default_timer()
for url in urls:
start_time_url = default_timer()
_ = requests.get(url)
elapsed = default_timer() - start_time_url
print(url ' took ' str(elapsed))
tot_elapsed = default_timer() - start_time
print('Total time taken for all : ' str(tot_elapsed))
if __name__ == '__main__':
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']
get_urls(urls)And when we run it we get something like...
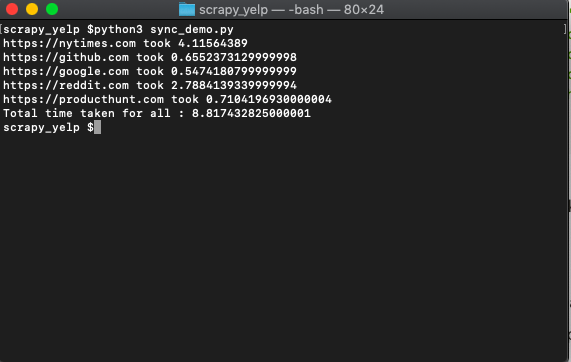
The whole thing runs one after the other and takes around 8.8 seconds on my machine.
Now let's see if we can do this the Asynchronous way.
Async is a better option than multi-threading because it's very difficult to write thread-safe code.
So here is an example of fetching multiple URLs simultaneously using aiohttp module.
We will try and fetch all the URLs from this array...
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']First, we will initialize everything by loading the modules we need...
import asyncio
from timeit import default_timer
from aiohttp import ClientSession
import requestsWe need a function to handle individual fetches.
async def fetch(url, session):
fetch.start_time[url] = default_timer()
async with session.get(url) as response:
r = await response.read()
elapsed = default_timer() - fetch.start_time[url]
print(url ' took ' str(elapsed))
return rNotice how we use the start_time is stored in an array for each URL and the time taken is calculated and printed.
The fetch_urls calls the ensure_future function to make sure the URLs finish fetching.
async def fetch_all(urls):
tasks = []
fetch.start_time = dict()
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
_ = await asyncio.gather(*tasks) The fetch_async sets up the event loops and uses the run_until_complete to wait till all the URL fetches are completed to pass the control back so we can print the total time taken...
def fetch_async(urls):
start_time = default_timer()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_all(urls))
loop.run_until_complete(future)
tot_elapsed = default_timer() - start_time
print('Total time taken : ' str(tot_elapsed))Putting it all together...
import asyncio
from timeit import default_timer
from aiohttp import ClientSession
import requests
def fetch_async(urls):
start_time = default_timer()
loop = asyncio.get_event_loop()
future = asyncio.ensure_future(fetch_all(urls))
loop.run_until_complete(future)
tot_elapsed = default_timer() - start_time
print('Total time taken : ' str(tot_elapsed))
async def fetch_all(urls):
tasks = []
fetch.start_time = dict()
async with ClientSession() as session:
for url in urls:
task = asyncio.ensure_future(fetch(url, session))
tasks.append(task)
_ = await asyncio.gather(*tasks)
async def fetch(url, session):
fetch.start_time[url] = default_timer()
async with session.get(url) as response:
r = await response.read()
elapsed = default_timer() - fetch.start_time[url]
print(url ' took ' str(elapsed))
return r
if __name__ == '__main__':
urls = ['https://nytimes.com',
'https://github.com',
'https://google.com',
'https://reddit.com',
'https://producthunt.com']
fetch_async(urls)And when you run it...
python3 async.pyYou get..
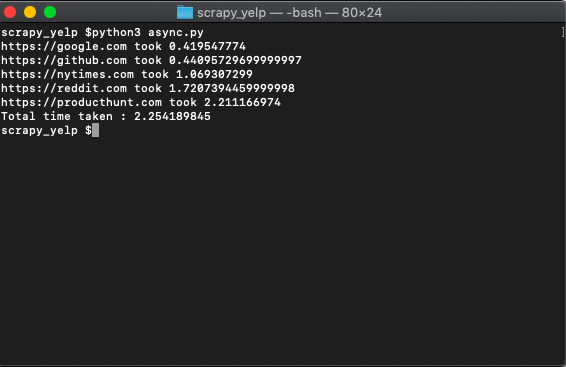
That's much faster than doing it synchronously which took 8.8 seconds earlier.
This will scale but If you want to use this in production and want to scale to thousands of links then you will find that you will get IP blocked easily by many websites as well. In this scenario using a rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage, and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
With millions of high speed rotating proxies located all over the world,
With our automatic IP rotation
With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions)
With our automatic CAPTCHA solving technology,
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
In fact, you dont even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so...
curl "http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com"We have a running offer of 1000 API calls completely free. Register and get your free API Key here.