In this article, we will learn how to quickly scrape New York Times News Articles posts using Puppeteer.
Puppeteer uses the Chromium browser behind the scenes to actually render HTML and Javascript and so is very useful if getting the content that is loaded by javascript/AJAX functions.
For this, you will need to install Puppeteer inside a directory where you will write the scripts to scrape the data. For example, make a directory like this...
mkdir puppeteer
cd puppeteer
npm install puppeteer --save
That will take a moment to install Puppeteer and Chromium.
Once done, let's start with a script like this...
const puppeteer = require('puppeteer');
puppeteer.launch({ headless: true, args: ['--user-agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3312.0 Safari/537.36"'] }).then(async browser => {
const page = await browser.newPage();
await page.goto("https://www.nytimes.com/");
await page.waitForSelector('body');
var rposts = await page.evaluate(() => {
});
console.log(rposts);
await browser.close();
}).catch(function(error) {
console.error(error);
});Even though it looks like a lot, It just loads up the puppeteer browser, creates a new page and loads the URL we want and waits for the full of the HTML to be loaded.
The evaluate function now gets into the page's content and allows you to query it with Puppeteer's query functions and CSS selectors.
The second line where the launch happens instructs puppeteer to load in in the headless mode so you dont see the browser but it's there behind the scenes. The —user-agent string imitates a Chrome browser on a Mac so you dont get blocked.
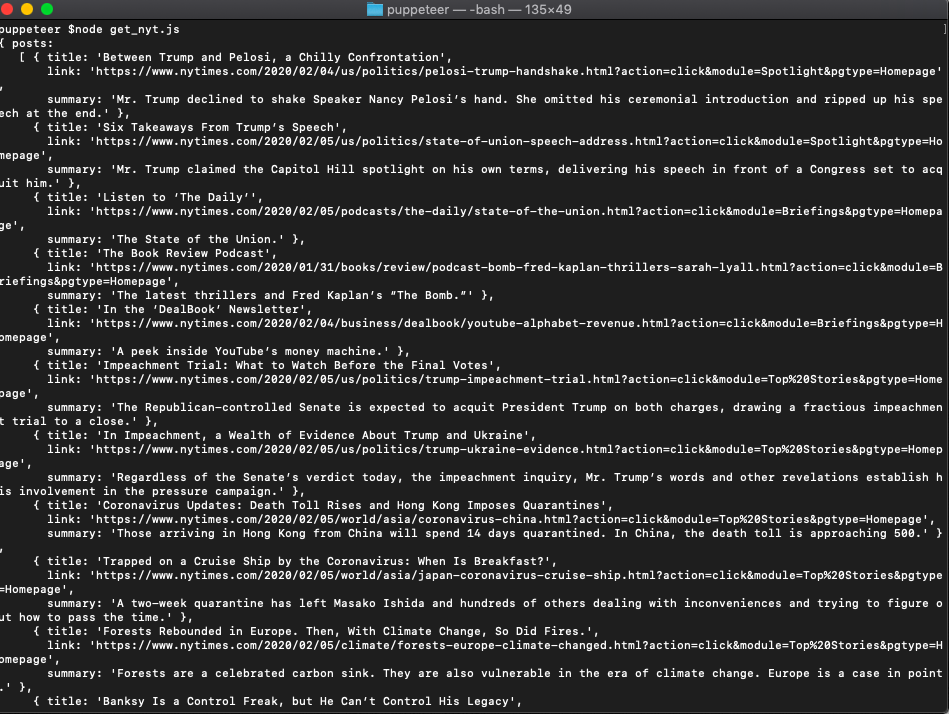
Save this file as get_nyt.js and if you run it, it should not return any errors.
node get_nyt.jsNow let's see if we can scrape some data...
Open Chrome and navigate to the nytimes.com website.
We are going to scrape the article headlines, links and summary. Let's open the inspect tool to see what we are up against.
You can see with some tinkering around that each post is encapsulated in a tag with the class name assetWrapper.
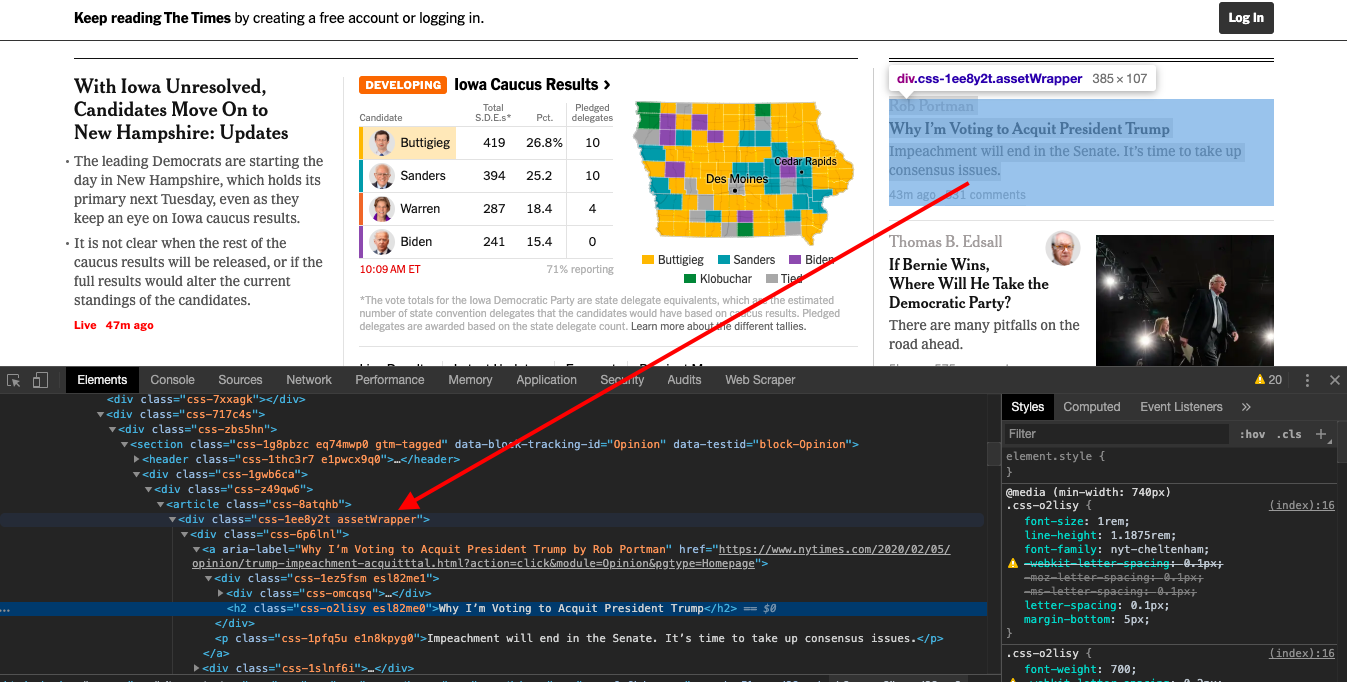
Since everything is inside this one class, we are going to use it for each loop to get the data inside them and get all the individual pieces separately.
So the code will look like this...
const puppeteer = require('puppeteer');
puppeteer.launch({ headless: true, args: ['--user-agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3312.0 Safari/537.36"'] }).then(async browser => {
const page = await browser.newPage();
await page.goto("https://www.nytimes.com/");
await page.waitForSelector('body');
var rposts = await page.evaluate(() => {
let posts = document.body.querySelectorAll('.assetWrapper');
postItems = [];
posts.forEach((item) => {
let title = ''
let summary = ''
let link = ''
try{
title = item.querySelector('h2').innerText;
if (title!=''){
summary = item.querySelector('p').innerText;
link = item.querySelector('a').href;
postItems.push({title: title, link: link, summary: summary});
}
}catch(e){
}
});
var items = {
"posts": postItems
};
return items;
});
console.log(rposts);
await browser.close();
}).catch(function(error) {
console.error(error);
});
You can see how the tag always has the title of the article so we fetch that. the query...
summary = item.querySelector('p').innerText;
summary = item.querySelector('p').innerText;
Gets us the summary attached to each article. We put this in a try... catch... because some might not have a summary and might raise an error and break the code.
If you want to use this in production and want to scale to thousands of links then you will find that you will get IP blocked easily by NYT. In this scenario using a rotating proxy service to rotate IPs is almost a must.
Otherwise, you tend to get IP blocked a lot by automatic location, usage and bot detection algorithms.
Our rotating proxy server Proxies API provides a simple API that can solve all IP Blocking problems instantly.
- With millions of high speed rotating proxies located all over the world.
- With our automatic IP rotation.
- With our automatic User-Agent-String rotation (which simulates requests from different, valid web browsers and web browser versions).
- With our automatic CAPTCHA solving technology.
Hundreds of our customers have successfully solved the headache of IP blocks with a simple API.
The whole thing can be accessed by a simple API like below in any programming language.
In fact, you dont even have to take the pain of loading Puppeteer as we render Javascript behind the scenes and you can just get the data and parse it any language like Node, Puppeteer or PHP or using any framework like Scrapy or Nutch. In all these cases you can just call the URL with render support like so...
curl "http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com"
curl "http://api.proxiesapi.com/?key=API_KEY&render=true&url=https://example.com"
We have a running offer of 1000 API calls completely free. Register and get your free API Key here.